One-to-Many Relationships in DynamoDB
A SaaS control plane almost always has a containment hierarchy: one workspace
owns many projects. In SQL you'd put a workspace_id foreign key on the
projects table and JOIN.
DynamoDB has no joins and no foreign keys, so the relationship has to live in the
key schema itself. Done right, "load a workspace and every project inside it"
becomes a single Query instead of one read plus a follow-up scan.
How do you model a one-to-many relationship in DynamoDB?
Give the parent and all its children the same so they share one , then differentiate them with the sort key. DynamoDB has no joins or foreign keys, so the relationship lives in the key schema itself. Loading a parent plus every child then becomes a single Query instead of a join.
- Model the reads, not the entities. The one-to-many relationship only exists to serve "list a workspace's projects" — shape the keys around that query.
- Encode the parent into the child's . Give the workspace and all its projects the same partition-key value so they land in one .
- Then the list read is one
Query. Parent plus an arbitrary number of children come back in a single billed call — no join, no second round trip. - Watch the . One huge tenant concentrates all its traffic on one partition; a giant workspace may need a sharded key and a fan-out read.
The access pattern, first
DynamoDB modeling is access-pattern-first, not entity-first — the same discipline behind single-table design. Before choosing any key, write down the reads the app actually issues:
- Get one workspace's settings.
- List every project in a workspace, newest-first.
- Get one specific project by id.
The "one workspace, many projects" relationship only matters because of read #2. If you never needed to list a workspace's projects together, you wouldn't model the relationship at all — you'd store projects independently.
So the question is never "how do I represent one-to-many?" in the abstract. It's "which queries must this relationship serve?" Answer that, then shape the keys around it.
Why a foreign key won't help here
In DynamoDB every GetItem and Query targets a partition key, and the
service hashes that key to locate the partition holding the item.
AWS says so directly in the Core Components docs: the partition-key value is the input to an internal hash function that decides where data lives.
That hash-based placement is the inheritance from the original 2007 Dynamo: Amazon's Highly Available Key-value Store paper, where consistent hashing distributes keys across nodes.
A bare workspace_id attribute on a project item is invisible to that
machinery — DynamoDB can't "follow" it.
To fetch related items in one request, the parent's identity must be encoded into
the project's partition key, so all of a workspace's items hash to the same
partition and one Query can sweep them.
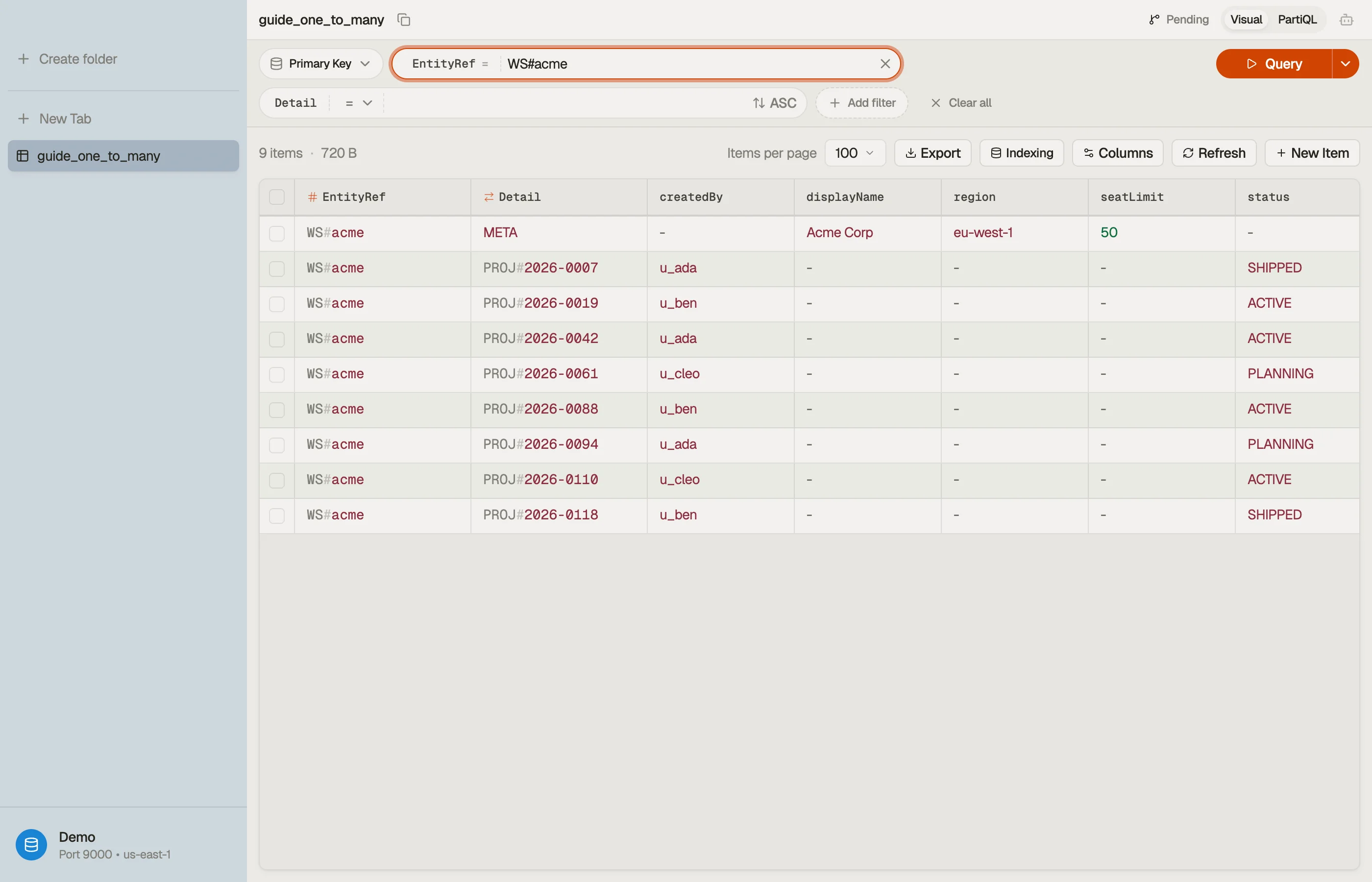
Worked example: workspaces and projects
Use a generic, overloaded key schema. Call the partition key EntityRef and the
sort key Detail. The workspace identity goes into EntityRef for both the
workspace item and every project under it:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
The workspace and all its projects share EntityRef = "WS#acme", so they form a
single item collection living together on one partition.
The Detail sort key separates them: META is the workspace record, and each
project carries a PROJ# prefix with a zero-padded, time-ordered id so projects
sort naturally.
Visually, the parent and its children stack inside one partition, ordered by the sort key:
One Query on EntityRef = "WS#acme" sweeps the whole stack — parent plus every
child — in a single read.
Now the three access patterns each collapse to one call:
- Workspace settings —
GetItem(EntityRef="WS#acme", Detail="META"). - List projects newest-first —
Query(EntityRef="WS#acme")withDetail begins_with "PROJ#", run in descending order (ScanIndexForward = false). - One project —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
The second one is the whole point: the parent and an arbitrary number of children
come back in one billed Query, no join and no second round trip. That's the
move you can't make with a foreign-key attribute and a Scan.
Writing that begins_with condition by hand is fiddly — the key-condition and
projection-expression syntax bites.
The DynamoDB Expression Builder generates
the KeyConditionExpression, the #name/:value placeholder maps, and a
ready-to-run SDK snippet so you don't fight the grammar:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Inspect the item collection in DynoTable
The payoff of this layout is visual: every row sharing an EntityRef is the
workspace plus its children, sitting next to each other.
DynoTable groups them so you see the one-to-many relationship as one contiguous block instead of guessing at it across separate tables.


Pitfalls and the alternative shape
A few things to watch:
- Hot partitions. Every item for one workspace lives on one partition, so a
single very large or very busy tenant concentrates traffic. The
adaptive capacity
behavior AWS describes absorbs moderate skew, but a workspace with millions of
projects may need a sharded key (e.g.
WS#acme#01 … #10) and a fan-out read. - Item-collection size. With a local secondary index, a single partition's item collection is capped at 10 GB; without an LSI there's no such limit. If you're weighing index types here, see GSI vs LSI.
- Reach for
Query, neverScan. The whole design exists so you canQueryone partition. Falling back to a filteredScanto "find a workspace's projects" throws the model away and reads the entire table — the trap covered in Query vs Scan.
If you genuinely need to list projects across workspaces (say, all
status = ACTIVE projects globally), the base table can't answer that — its
partition key is workspace-scoped.
That's a job for a secondary index that re-partitions projects on a different attribute, not for reshaping this relationship.
Next steps
Model the access patterns, encode the parent into the child's partition key, and
the one-to-many read is a single Query. Build and validate the key condition
with the DynamoDB Expression Builder.
Then download DynoTable to load this schema, browse the workspace→projects item collection live, and confirm each query does exactly one read.