DynamoDB Sort Key Strategies
A DynamoDB primary key is one or two attributes: a alone, or a partition key plus a sort key. The partition key decides which physical partition holds an item.
The sort key decides the order of items inside that partition — and that
ordering is what makes Query powerful.
Pick the wrong sort key and you can still write data, but you lose range reads, ordering, and several access patterns from one collection.
Coming from SQL you'd reach for an ORDER BY or a secondary index after the
fact. In DynamoDB you bake the order into the key up front, or you don't get it.
How do DynamoDB sort keys work?
A DynamoDB sort key orders items within a partition, so Query can do range reads — >=, between, begins_with — instead of fetching one item at a time. Ordering is byte-order on the encoded key, so design it (an ISO-8601 timestamp, a zero-padded number) so byte-order equals the order you want to read.
- The sort key is your in-partition index. It orders the on
disk, so
Querycan do range reads (>=,between,begins_with) instead of a singleGetItem. - Ordering is byte-order on the encoded key. Design the key so byte-order
equals the order you want to read — an ISO-8601 timestamp, a zero-padded
number, never a raw UUID or
6/23/2026. - One well-shaped sort key serves many access patterns. A
(
EVT#<timestamp>) is a prefix and a range at once — no GSI needed. - Direction is free.
ScanIndexForward = falsereads newest-first at the same cost; don't store reversed timestamps to fake it.
Why the sort key is the lever
Without a sort key, every item in a partition is addressable only by its full
primary key — a GetItem at best. Add a sort key and DynamoDB stores items
sorted by it within the partition, which unlocks Query.
That means range conditions (>=, between), prefix matching (begins_with),
and a ScanIndexForward flag to read ascending or descending.
Per the AWS DynamoDB Developer Guide, all items sharing a partition key form an item collection, ordered on disk by the sort key.
So the sort key isn't just a second identifier. It's the index you query against inside a partition.
That ordering is byte-order on the encoded sort key: strings compare by UTF-8 bytes, numbers compare numerically. This one fact drives almost every strategy below.
If you want range queries to mean something, byte-order has to match the order you want to read.
Strategy 1: make the sort key sortable
The most common mistake is a sort key that isn't meaningfully ordered. A random UUID gives you uniqueness but no useful range query — "give me the last 20" becomes impossible because byte-order is arbitrary.
Instead, encode the value you sort and filter on into the sort key, in a representation whose byte-order equals its logical order. For timestamps that means a lexicographically-sortable format: an ISO-8601 string or a zero-padded epoch.
ISO-8601 was designed so string comparison equals chronological comparison —
exactly what a range query needs. Avoid formats like 6/23/2026; they sort wrong
the moment the month rolls over.
If you sort on numbers (a version counter, a score), use DynamoDB's native
Number type rather than a string, so 42 sorts after 9 instead of before
it.
If a number must live inside a composite string sort key, zero-pad it to a fixed width.
Strategy 2: composite sort keys for hierarchy
A sort key can encode a hierarchy by concatenating segments with a delimiter,
most commonly #. One begins_with condition then selects a whole sub-tree:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") returns just June's events; the broader
begins_with(SK, "EVENT#") returns all of them.
Segment ordering is a design decision. Coarse-to-fine (year → month → day) keeps related items contiguous, so a range read stays one cheap query instead of a scatter across the partition.
Strategy 3: control direction with ScanIndexForward
DynamoDB stores items in ascending sort-key order and reads them that way by
default. To read newest-first — the natural order for an activity feed — set
ScanIndexForward = false on the Query.
This is a read-time flag, not a schema decision: the same collection serves both directions at the same cost. Don't invert your timestamps (storing a "reverse epoch") just to get descending reads.
One item collection, stored once in ascending order, read either way:
Same items, same partition, same cost — only the read direction differs.
The one exception: if you specifically need the descending order to also be the
order a sparse index or pagination cursor advances in. Short of that,
ScanIndexForward is the simpler lever.
Worked example: an actor-scoped audit log
Suppose you record timestamped events produced by actors — users, services, API keys — in a SaaS product, and you have two reads:
- The activity stream for one actor, newest event first.
- One actor's events within a time window (e.g. "everything between the two deploys"), for an investigation.
Both reads are scoped to a single actor, so the actor is the partition key and the event time is the sort key. Use generic key names so the same table can hold other entities later:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
The EVT# prefix plus an ISO-8601 timestamp gives a sortable sort key. Read 1 is
Query PK = "ACTOR#u_8814" with ScanIndexForward = false for newest-first. Read
2 narrows the same partition with a between condition on the sort key:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"One collection, two access patterns, no GSI — because the sort key is both a prefix
(EVT#) and a range (the timestamp). The descending read and the window read are
the same items in the same order; only the parameters differ.
Building that key condition by hand, it's easy to fumble the between bounds or
the reserved-word escaping on attribute names.
The DynamoDB Expression Builder
generates the KeyConditionExpression, the ExpressionAttributeNames, and the
ExpressionAttributeValues for a begins_with or between sort-key condition.
Copy it straight into your SDK call instead of debugging escaping at runtime.
Do it in DynoTable
Designing a sort key is iterative: write a few representative items, run the range query, and check the rows come back in the order you expect. Doing that against a live table in a GUI beats round-tripping through code.

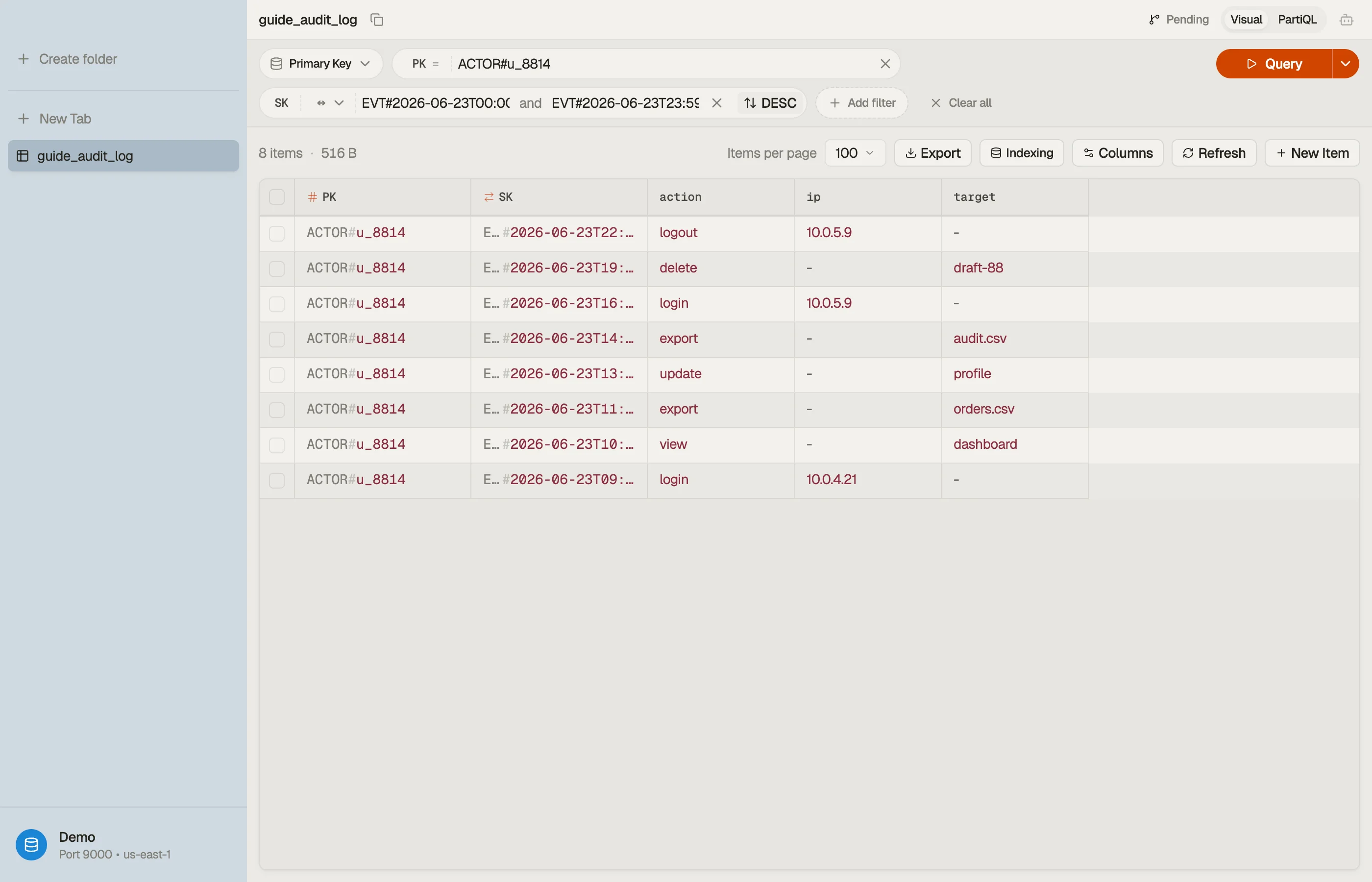

Flip the sort direction, tighten the between bounds, and watch the returned
collection change without writing a line of code — the fastest way to confirm a
sort-key design before you commit it.
Pitfalls and next steps
- Sort keys must be unique within a partition. If two events can share a timestamp, append a disambiguator (a sequence number or short id) to the sort key so the composite stays unique.
- A hot partition can't be sorted around. If one actor produces far more events than the rest, the sort key won't save you — you need a partition-key design that spreads the load. See single-table design.
- A second sort order needs a second index. The base table's sort key gives one ordering. To order the same items differently (by event type, say), add a GSI with a different sort key — weighing the local vs global secondary index trade-offs.
- Don't reach for
Scanto "sort later". Sorting client-side after aScanreads the whole table and throws ordering away; that's the Scan footgun. Push the order into the sort key instead.
Once the key condition is right, try DynoTable to model the collection, run the ascending and descending queries side by side, and verify your sort-key strategy against real data before it ships.