DynamoDB Sparse Indexes
A sparse index is a secondary index that holds only the items carrying its key attribute — so a small, hot subset of a huge table becomes its own pre-filtered, ready-to-query collection.
You have millions of rows but the query you run all day touches a tiny slice: the open support tickets, the unpaid invoices, the accounts flagged for review.
Filtering that slice still scans the whole table and bills you for every read. A sparse index makes the index itself small instead.
What is a sparse index in DynamoDB?
A sparse index is a secondary index that holds only the items carrying its key attribute. Because DynamoDB skips any item missing that key, you invent a key only the wanted items write — open tickets, unpaid invoices — and the index becomes that exact subset. Queries then read just it, no filter, no wasted read capacity.
- A secondary index only indexes items that have its key. Omit the key on an item and it never enters the index — no placeholder, no null row.
- So you invent a key only the wanted items carry. Write it on the items you query, remove it on the rest. The index becomes exactly that subset.
- The query reads only the subset, no filter. Its size tracks the small hot set, not the table total.
REMOVEis the lever, not blanking. An empty string is still a value and still gets indexed — you must delete the attribute.
The problem: filtering doesn't save reads
Coming from SQL, you assume a WHERE clause narrows the work. DynamoDB's
FilterExpression does not. It runs after items are read, not before.
Per the AWS Developer Guide, filtering "does not reduce the amount of read capacity consumed" — you pay for every item examined, then throw the non-matches away.
So if 50 of your 5 million tickets are open, a filtered Query/Scan reads
through millions to hand you those 50.
That is the footgun behind every "why is my scan so expensive" thread; query vs. scan has the full cost picture.
A sparse index sidesteps it by making the index itself small.
How sparseness works
A secondary index only indexes items that actually have the index's key attributes.
The AWS docs on global secondary indexes say it plainly: "a global secondary index only contains items that have the key attributes defined for that index."
Miss the GSI's partition key (or sort key) on an item and DynamoDB just doesn't write it to the index. No placeholder, no null row — the item is absent.
That "absence by default" is the whole trick. Don't index a status attribute
that every item carries. Invent an attribute that only the items you want to
query carry at all.
The index then becomes a clean list of exactly those items, and a Query against
it reads only them — no filter, no wasted capacity.
Picture the base table feeding the index, where only items carrying the key cross over:
Only the keyed (open) items replicate to the index; closed items never enter it.
This is the same key-shaping mindset as single-table design: keys are tools you build for a specific access pattern, not faithful mirrors of your data.
A worked example: "open tickets only"
Take a support-ticket table. The base table is keyed for fetching a ticket by id and listing a customer's tickets:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
Over the table's lifetime, most tickets end up closed. But the dashboard query your agents hit all day is "show me every open ticket, oldest first" — a few hundred rows hiding inside millions.
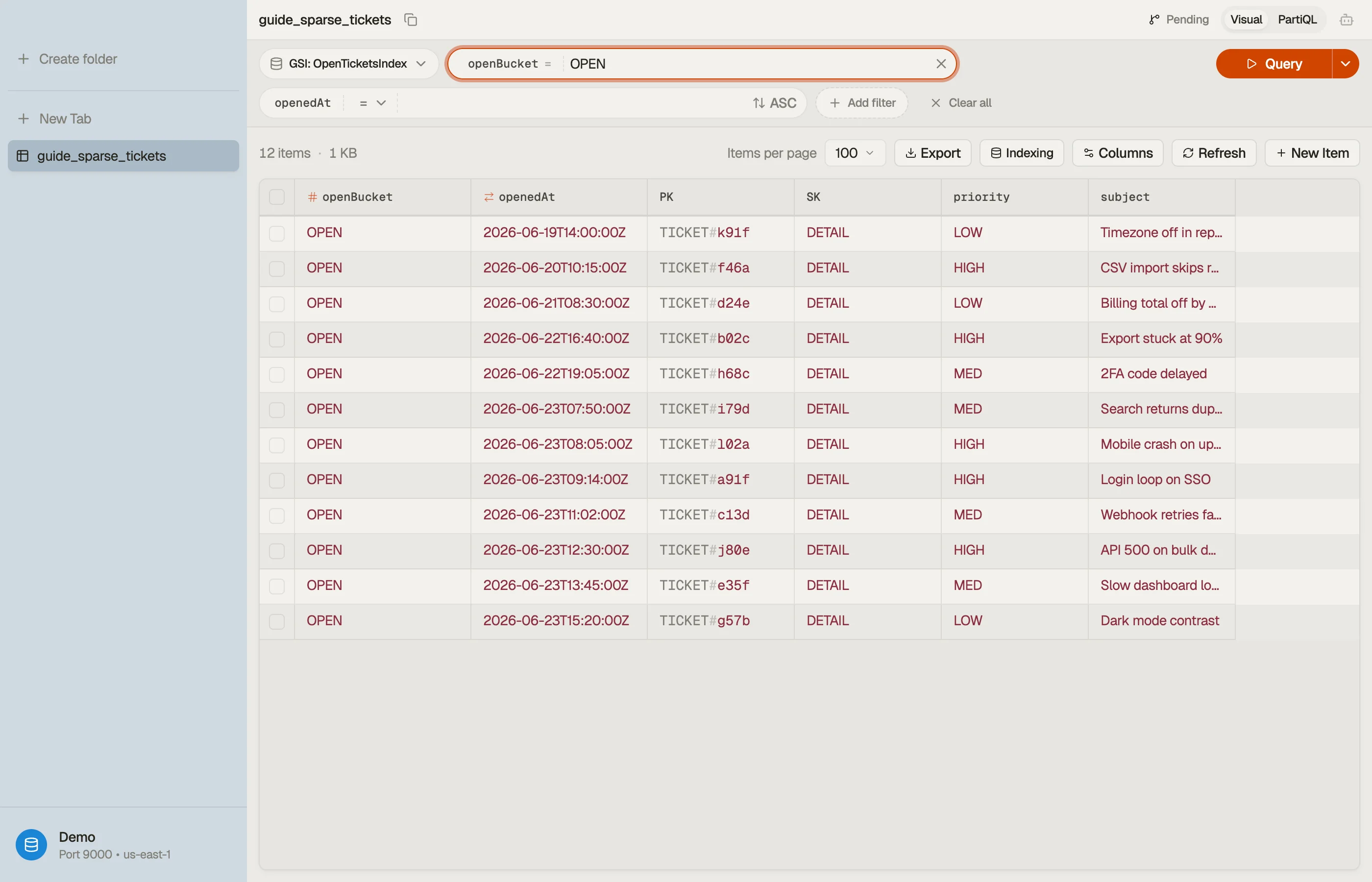
The sparse-index move: define a with partition key openBucket and sort key
openedAt, and only write openBucket on open tickets. Set it when the
ticket is created; REMOVE it when the ticket resolves.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← open: in the index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← open: in the index |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← closed: NOT in the index |
Tickets a91f and b02c carry openBucket, so they live in the GSI. Ticket
77de was resolved and had openBucket removed, so it silently dropped out. The
dashboard is now one cheap query:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstThis reads only open tickets. As tickets close, the index shrinks on its own — its size tracks the open population, never the total.
One static partition value ("OPEN") is fine here precisely because the set stays
small. A huge open set would need a sharded partition key, but the "small subset"
index is exactly where one value is the right call.
The transition that makes it work is a single — removing the attribute when the ticket resolves.
Prototype that REMOVE clause and the typed key condition for the read side in the
DynamoDB Expression Builder, instead of
hand-assembling ExpressionAttributeNames and :val placeholders yourself.
Do it in DynoTable
The hard part of a sparse index isn't the read — it's seeing which items made it into the index versus which silently fell out.
DynoTable lets you switch a table view to a secondary index and see exactly the
populated subset. So you can confirm a resolved ticket really left
open-tickets-index instead of lingering with a stale key.


Pitfalls and next steps
A few things to watch:
- Remove the key, don't blank it. An empty string is still a value, and
DynamoDB will index an item whose
openBucketis"". To drop an item from the index you mustREMOVEthe attribute — setting it to a falsy value keeps it in. - The index is . GSIs update asynchronously, so a just-resolved ticket may briefly still appear — GSI reads support eventual consistency only. Don't trust it for "is this ticket open right now".
- Mind attributes. A
Queryon the index returns only the attributes projected into it. If the dashboard needs subject and priority, project them — or pay an extraGetItemfor the full base item. - This is a GSI strength, not an LSI one. Local secondary indexes share the base table's partition key and can't selectively drop items this way. GSI vs. LSI breaks down the trade-off.
Sparse indexes are one of the oldest ideas in the model. The original 2007 Amazon Dynamo paper built the store around serving known, high-volume access patterns cheaply.
A sparse index is exactly that: shape the keys so the common query reads nothing it doesn't need.
To build and inspect one for real, download DynoTable, point it at your table, and flip the data view to your sparse GSI — watch the subset update as items gain and lose the index key.