DynamoDB でのデータモデリング
SQL ではまずエンティティとリレーションシップをモデリングし、あとは何を尋ねても組み立てて くれるクエリプランナーを信頼します。DynamoDB はそれを逆転させます。あなたは すでに 行うとわかっている読み取り をモデリングし、キーはそれらに応えるために存在します。
結合エンジンも、実行時に戦略を選ぶプランナーもありません。Query は1つのキーに沿って
1つのパーティションを読み、それがパフォーマンス契約のすべてです。だから、整然とした
スキーマのためではなく、既知のアクセスパターンのためにキーを設計します。
AWS は ベストプラクティスガイド で明快にこう述べています。「スキーマが答える必要のある問いがわかるまで、スキーマの設計を 始めるべきではない」。
このガイドは1つのドメインで全プロセスを歩きます。プレイヤー、彼らがプレイする試合、 シーズンごとのランキングを追跡する マルチプレイヤーゲームのリーダーボード です。問いの リストから、動作するキースキーマへと進みます。
DynamoDB でデータをモデリングするにはどうすればよいですか?
テーブルではなく、まず読み取りをモデリングします。アプリが行うすべてのクエリを列挙し、各問いが単一の Query または GetItem に解決されるようとを設計します。一緒に読まれるアイテムを同じパーティションに配置し、ソートキーで値を範囲指定し、ベーステーブルでは対応できないアクセスパターンには GSI を追加します。
- テーブルではなく、まず読み取りを列挙する。 問いが仕様で、名詞は気を散らすものです。
- 各問いは1回の
QueryかGetItemでなければならない。 問いがScanを必要とする なら、モデルが間違っています。 - 同居するアイテムはパーティションキーを共有し、範囲指定したいものはソートキーに入れる。
- ベーステーブルが答えられない問いには GSI を — フィルタ付きの
Scanではなく。
ステップ 1 — 問題をテーブルではなく問いとして組み立てる
players、matches、scores テーブルを描きたくなる衝動に抗ってください。その本能は
SQL の習慣であり、ここでは間違っています。代わりに、アプリが実際に行うすべての読み取りを
書き出します。私たちのリーダーボードでは。
- 1人のプレイヤーのプロフィールを id で取得する。
- プレイヤーの最近の試合を新しい順に一覧する。
- 指定したシーズンの上位 N 人のプレイヤーをレーティングでランク付けして表示する。
- プレイヤーを公開ハンドルで参照する(例:プロフィール URL のため)。
これら4つの問い — 名詞ではなく — が仕様です。各問いは単一の Query(または GetItem)に
解決しなければなりません。それが、DynamoDB が規模を保って安価に提供する唯一のアクセス形
だからです。
問いがテーブルをスキャンしてしか答えられないなら、モデルが間違っており、レイテンシと
コストでそれを感じることになります — Scan が避けるべき落とし穴である理由は
Query と Scan を参照してください。
この手法全体は、ドメインごとに一度実行する短く順序立ったパイプラインです。
以下の各ステップは1つのボックスに対応します。列挙、洗い出し、キー設計、残りのための インデックス追加、そして検証です。
ステップ 2 — モデリングに使うプリミティブを理解する
テーブルには、アイテムがどの物理パーティションに住むかを選ぶ パーティションキー(PK) と、そのパーティション 内で アイテムを順序付けるオプションの ソートキー(SK)が あります。
AWS の Core Components ドキュメント
はこのペアをアイテムのプライマリキーと呼びます。Query は常にちょうど1つの PK 値を対象
とし、SK を範囲スキャンまたはフィルタできます — それが道具一式のすべてです。
この単一パーティション設計こそが、2007 年の Amazon Dynamo 論文で初めて記述された、 予測可能で低レイテンシな水平分割された読み取りを DynamoDB に提供させているものです。
2つの帰結が以下のすべての決定を駆動します。
- 一緒に読まれるアイテムはパーティションキーを共有すべき — 1回の
Queryがそれらを 単一の課金対象リクエストで返すように。 - 範囲指定したいもの(最近の試合、上位レーティング)は ソートキー に住まなければ
ならない — それが
Queryが順序付けて境界付けられる唯一の属性だから。
問いがベーステーブルが提供するのとは 異なる アクセス形を必要とするとき、グローバル セカンダリインデックス — 異なる PK/SK の下でのテーブルの再射影 — を追加します。
(GSI とローカルセカンダリインデックスの比較は GSI と LSI を参照。)
ステップ 3 — キーを、問いごとに1つずつ設計する
汎用的でオーバーロードしたキー属性を持つ単一のテーブル — シングルテーブルの手法 — を使います。プレイヤーとその試合は一緒に読まれるからです。
自分のプレフィックスを発明します。ここでは PLAYER#、MATCH#、SEASON# が、それ以外は
汎用なキーの中でエンティティの種類をタグ付けします。
問い 1 と 2(プロフィール + 最近の試合)はパーティションを共有するため、両方が同じ PK にぶら下がります。
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" は、プロフィールとすべての試合を1回の読み取りで
返します。プロフィールだけなら GetItem です。
最近の試合には、ScanIndexForward = false を付けた rangeId begins_with "MATCH#" が
新しい順に歩きます — ソートキーのタイムスタンプが順序付けを無料でやってくれます。
問い 3 と 4 はそのパーティションから答えられません — シーズンランクとハンドルで ピボットしますが、どちらもベース PK ではありません。それぞれが GSI を得ます。
2つの汎用インデックス属性 gsiPartition / gsiSort を追加し、各アイテムにそのインデックス
が必要とするものでそれらを populate させます。
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
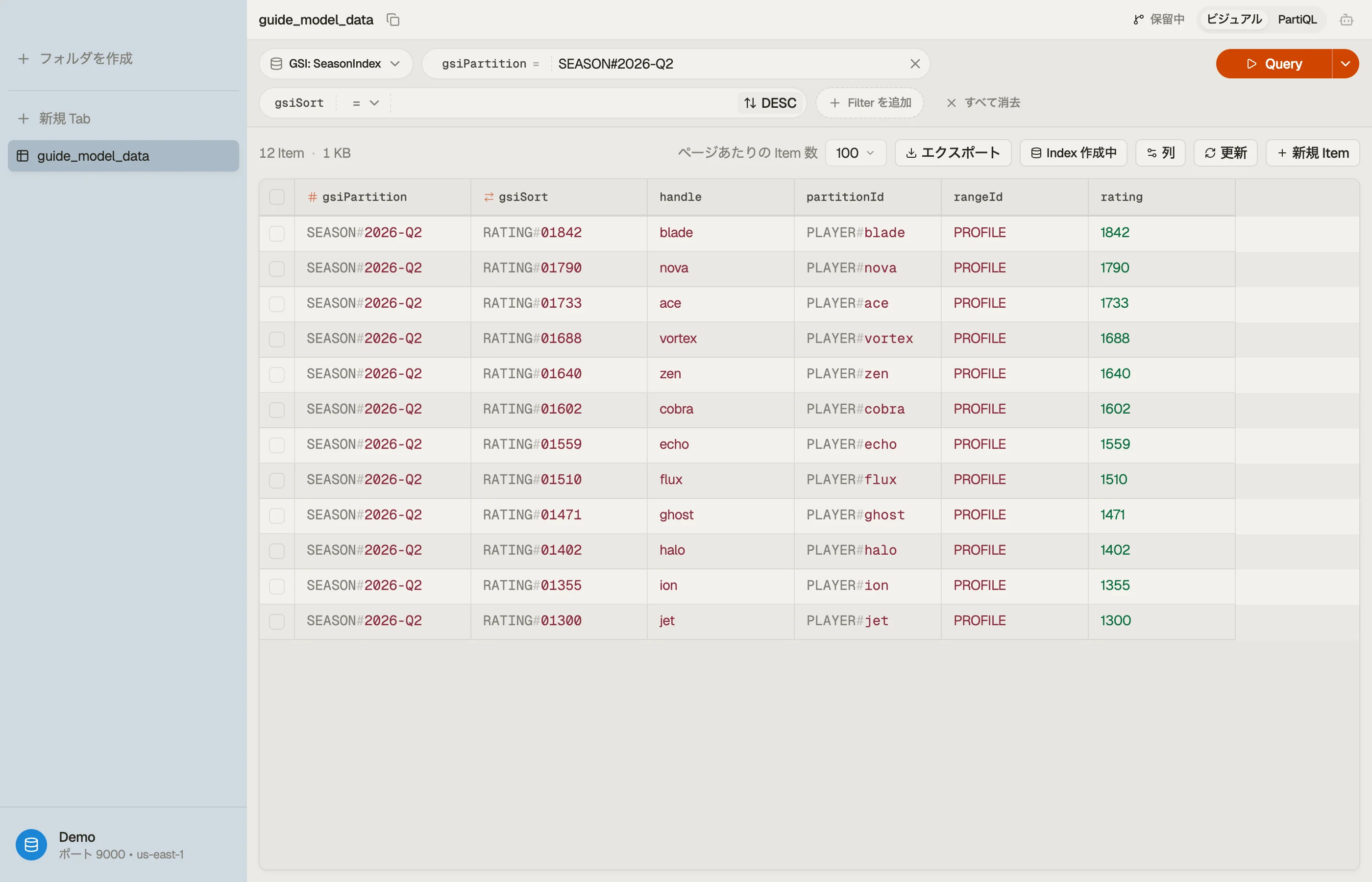
これで ScanIndexForward = false を付けてシーズンインデックスを
Query WHERE gsiPartition = "SEASON#2026-Q2" すれば、レーティングでランク付けされた
プレイヤーが返ります — それがリーダーボードです。
HANDLE#… でキーイングした2つ目のインデックスが、公開ハンドルをプレイヤー id に1回の
読み取りで解決します。1つの物理テーブル、4つの単一 Query アクセスパターン。
RATING#1842のゼロ埋めに関する注記:DynamoDB はソートキーを数値順ではなく 辞書順 でソートするため、レーティングは固定幅にゼロ埋め(RATING#01842)しなければ ならず、さもないと9が1000の後にソートされてしまいます。これは前もって正しく しておく価値のある古典的なモデリングの落とし穴です。
ステップ 4 — DynoTable でモデルを検証する
キースキーマは、実際の Query が期待したとおりのアイテムを、それ以上でも以下でもなく
返すのを見て初めて信頼を得ます。
DynoTable でテーブルを開き、シーズンインデックスに対してリーダーボードのクエリを実行し、
パーティションがランク付けされ境界付けられて返ってくることを確認しましょう — Scan も
クライアント側のソートもなしに。


これらのクエリの条件式 — begins_with、gsiPartition = :p、プレースホルダー :p の
バインド — を組み立てるときは、DynamoDB Expression Builder
にやらせましょう。
それは KeyConditionExpression、ExpressionAttributeNames、ExpressionAttributeValues
を生成するので、result のような予約語やタイプミスしたプレースホルダーが静かに読み取りを
壊すことはありません。
ステップ 5 — 落とし穴と次のステップ
モデルを出荷する前に確認すべきいくつかの罠があります。
- 一緒に読まないリレーションシップをモデリングしない。 問いごとの GSI は安価ですが、 無駄な GSI は継続的なコストです。インデックスは投機的にではなく、問いのリストから追加 しましょう。
- パーティションの熱に注意。 1つの PK(有名プレイヤー、1つのホットなシーズン)が トラフィックの大半を吸収すると、そのパーティションはスロットリングされかねません。 キーが明らかにホットなときはサフィックスシャードで書き込みを分散します — AWS は パーティションキー設計 でこれを扱っています。
- ソートキー内の数値や時刻はすべてゼロ埋めと ISO-8601 にする — 辞書順が意図した順序と 一致するように。
- 新しい問い = 新しいキーかインデックスであって、決して
Scanではない。 後から本当に 新しいアクセスパターンが現れたら、キーを拡張しましょう。フィルタでごまかしてはいけません。
まず問いをモデリングし、各問いが1回の Query になるようキーを設計し、それを証明
しましょう。
DynoTable を試して テーブルを閲覧し、これらのクエリをベーステーブルと GSI に 対して並べて実行し、設計したアクセスパターンが計画どおりのものを返すのを見てください。