DynamoDB のソートキー戦略
DynamoDB のプライマリキーは1つか2つの属性です。パーティションキー単独か、パーティション キー にソートキーを加えたもの です。パーティションキーが、どの物理パーティションが アイテムを保持するかを決めます。
ソートキーは、そのパーティション内のアイテムの 順序 を決めます — そしてその順序付け
こそが Query を強力にします。
間違ったソートキーを選んでも、データは書けます。しかし範囲読み取り、順序付け、そして 1つのコレクションからのいくつかのアクセスパターンを失います。
SQL から来ると、後付けで ORDER BY やセカンダリインデックスに手を伸ばすでしょう。
DynamoDB では、順序を前もってキーに焼き込むか、さもなければ手に入りません。
DynamoDB のソートキーはどのように機能しますか?
DynamoDB のソートキーはパーティション内のアイテムを順序付けるため、Query は1件ずつフェッチするのではなく、範囲読み取り(>=、between、begins_with)が可能になります。順序付けはエンコードされたキーのバイト順なので、バイト順が読みたい順序と等しくなるように設計します(ISO-8601 タイムスタンプやゼロ埋めした数値など)。
- ソートキーはパーティション内のインデックス。 ディスク上でアイテムコレクションを
順序付けるので、
Queryは単一のGetItemではなく範囲読み取り(>=、between、begins_with)ができます。 - 順序付けはエンコードされたキューのバイト順。 バイト順が読みたい順序と等しくなるよう
キーを設計します — ISO-8601 タイムスタンプ、ゼロ埋めした数値であって、生の UUID や
6/23/2026ではありません。 - よく形作られた1つのソートキーが多くのアクセスパターンに応える。 複合キー
(
EVT#<timestamp>)はプレフィックスと範囲を同時に兼ねます — GSI 不要。 - 方向は無料。
ScanIndexForward = falseは同じコストで新しい順に読みます。それを 偽装するために逆向きのタイムスタンプを保存してはいけません。
なぜソートキーがレバーなのか
ソートキーがないと、パーティション内のすべてのアイテムは完全なプライマリキーでしか
アドレス指定できません — せいぜい GetItem です。ソートキーを追加すると、DynamoDB は
アイテムを パーティション内でソートキー順に 保存し、それが Query を解き放ちます。
それは範囲条件(>=、between)、プレフィックスマッチ(begins_with)、そして昇順か
降順かを読む ScanIndexForward フラグを意味します。
AWS DynamoDB デベロッパーガイドによれば、パーティションキーを共有するすべてのアイテムは アイテムコレクション を形成し、ディスク上でソートキーで順序付けられます。
つまりソートキーは単なる2つ目の識別子ではありません。パーティション内でクエリする対象の インデックスです。
その順序付けはエンコードされたソートキーのバイト順です。文字列は UTF-8 バイトで比較され、 数値は数値的に比較されます。この1つの事実が、以下のほぼすべての戦略を駆動します。
範囲クエリに意味を持たせたいなら、バイト順が読みたい順序と一致しなければなりません。
戦略 1:ソートキーをソート可能にする
最もよくある間違いは、意味のある順序を持たないソートキーです。ランダムな UUID は一意性を くれますが、役立つ範囲クエリはくれません — バイト順が任意なので「最後の20件をくれ」が 不可能になります。
代わりに、ソートとフィルタの対象となる値を、その論理順序とバイト順が等しい表現で、 ソートキー の中に エンコードします。タイムスタンプならそれは辞書順にソート可能な形式 を意味します。ISO-8601 文字列か、ゼロ埋めしたエポックです。
ISO-8601 は文字列比較が時系列比較と等しくなるように設計されました — まさに範囲クエリが
必要とするものです。6/23/2026 のような形式は避けてください。月が切り替わった瞬間に
誤ってソートされます。
数値(バージョンカウンタ、スコア)でソートするなら、文字列ではなく DynamoDB のネイティブ
Number 型を使い、42 が 9 の前ではなく後にソートされるようにします。
数値が複合の文字列ソートキーの中に住まなければならないなら、固定幅にゼロ埋めします。
戦略 2:階層のための複合ソートキー
ソートキーは、セグメントを区切り文字 — 最もよく使われるのは # — で連結することで階層を
エンコードできます。すると1つの begins_with 条件がサブツリー全体を選択します。
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") は6月のイベントだけを返し、より広い
begins_with(SK, "EVENT#") はそのすべてを返します。
セグメントの順序付けは設計上の決定です。粗いものから細かいもの(年 → 月 → 日)へとすると 関連アイテムが連続するため、範囲読み取りはパーティション全体への散乱ではなく、1つの安価な クエリのままです。
戦略 3:ScanIndexForward で方向を制御する
DynamoDB はアイテムを 昇順 のソートキー順に保存し、デフォルトでその向きに読みます。
新しい順に読むには — アクティビティフィードの自然な順序 — Query に
ScanIndexForward = false を設定します。
これは読み取り時のフラグであって、スキーマ上の決定ではありません。同じコレクションが両方向 を同じコストで提供します。降順の読み取りを得るために(「逆エポック」を保存して) タイムスタンプを反転させてはいけません。
1つのアイテムコレクションを昇順で一度保存し、どちら向きにも読む。
同じアイテム、同じパーティション、同じコスト — 読み取りの方向だけが異なります。
唯一の例外:降順を、スパースインデックスやページネーションカーソルが進む順序にも特に
する必要がある場合です。それを除けば、ScanIndexForward の方が単純なレバーです。
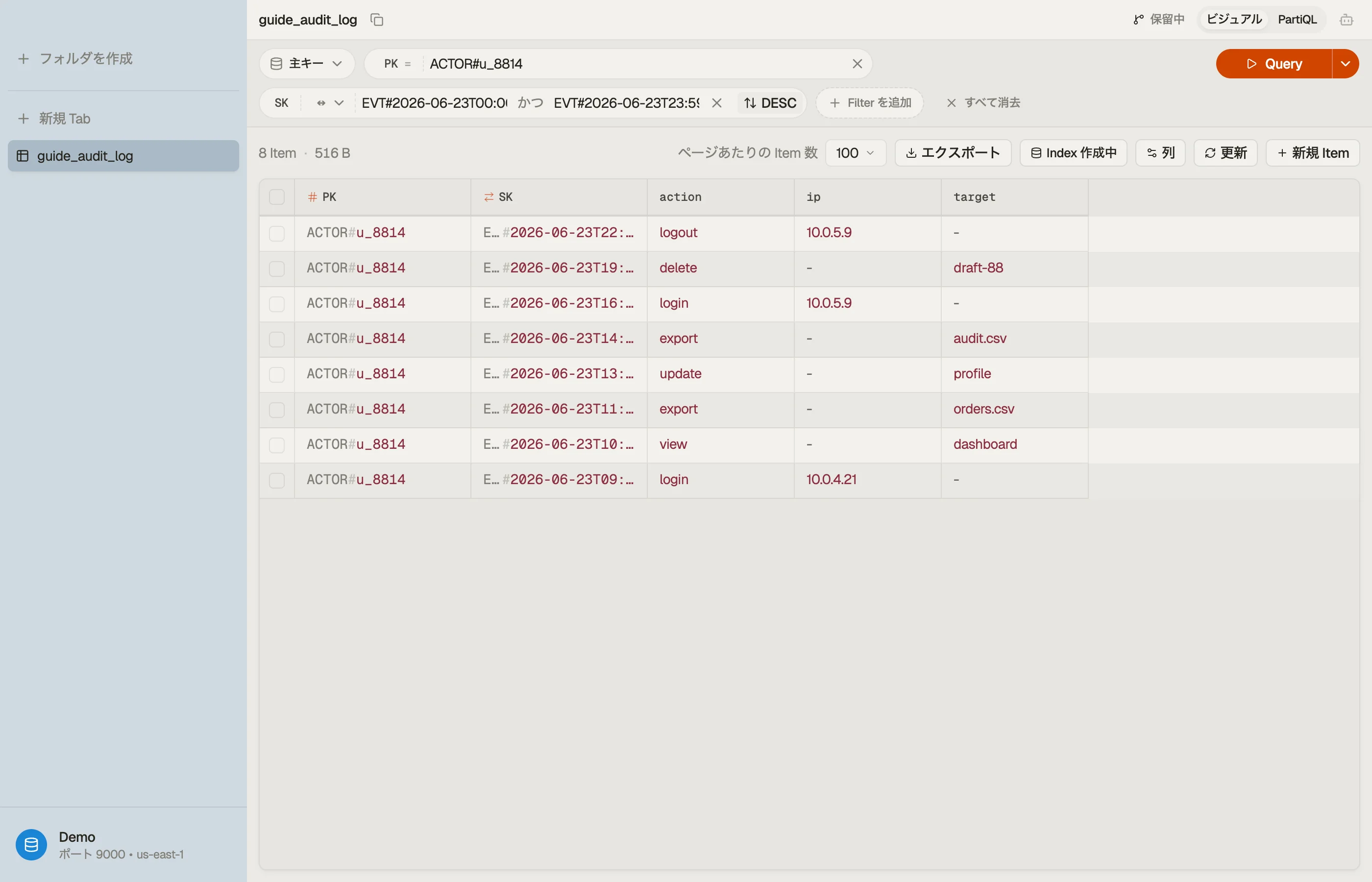
具体例:アクター単位の監査ログ
SaaS 製品で、アクター — ユーザー、サービス、API キー — が生成するタイムスタンプ付きの イベントを記録し、2つの読み取りがあるとします。
- 1人のアクターのアクティビティストリーム、新しいイベントが先頭。
- 時間の窓の中の1人のアクターのイベント(例:「2つのデプロイの間のすべて」)、調査の ため。
どちらの読み取りも単一のアクターにスコープされるため、アクターがパーティションキーで、 イベント時刻がソートキーです。後で同じテーブルが他のエンティティを保持できるよう、汎用の キー名を使います。
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
EVT# プレフィックスに ISO-8601 タイムスタンプを加えると、ソート可能なソートキーになり
ます。読み取り 1 は、新しい順のための ScanIndexForward = false を付けた
Query PK = "ACTOR#u_8814" です。読み取り 2 は、ソートキーに対する between 条件で同じ
パーティションを絞り込みます。
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"1つのコレクション、2つのアクセスパターン、GSI なし — ソートキーがプレフィックス(EVT#)
と範囲(タイムスタンプ)の両方だからです。降順の読み取りと窓の読み取りは、同じ順序の
同じ アイテムです。パラメータだけが異なります。
そのキー条件を手で組み立てると、between の境界や属性名の予約語エスケープをしくじり
やすいものです。
DynamoDB Expression Builder は、
begins_with や between のソートキー条件のための KeyConditionExpression、
ExpressionAttributeNames、ExpressionAttributeValues を生成します。
実行時にエスケープをデバッグする代わりに、それをそのまま SDK 呼び出しにコピーしましょう。
DynoTable でやってみる
ソートキーの設計は反復的です。代表的なアイテムをいくつか書き、範囲クエリを実行し、行が 期待した順序で返ってくるか確認します。それをライブのテーブルに対して GUI で行う方が、 コードを往復するより優れています。


ソートの方向を切り替え、between の境界を狭め、返ってくるコレクションが1行のコードも
書かずに変わるのを見てください — コミットする前にソートキー設計を確認する最速の方法です。
落とし穴と次のステップ
- ソートキーはパーティション内で一意でなければならない。 2つのイベントがタイムスタンプ を共有しうるなら、複合が一意のままになるよう曖昧さ解消子(シーケンス番号や短い id)を ソートキーに付け足します。
- ホットパーティションはソートで回避できない。 1人のアクターが他より遥かに多くの イベントを生成するなら、ソートキーは救ってくれません — 負荷を分散させるパーティション キー設計が必要です。シングルテーブル設計 を参照。
- 2つ目のソート順には2つ目のインデックスが必要。 ベーステーブルのソートキーは1つの 順序付けをくれます。同じアイテムを別の順序で(例えばイベント種別で)順序付けるには、 異なるソートキーを持つ GSI を追加し、ローカルとグローバルのセカンダリインデックス のトレードオフを比較します。
- 「後でソートする」ために
Scanに手を伸ばさない。Scanの後にクライアント側で ソートするとテーブル全体を読み、順序付けを捨てます。それが Scan の落とし穴 です。代わりに順序をソートキーに押し込みましょう。
キー条件が正しくなったら、DynoTable を試して コレクションをモデリングし、 昇順と降順のクエリを並べて実行し、出荷前に実データに対してソートキー戦略を検証してください。