DynamoDB のキーオーバーロード
SQL の出身者には、列は永遠に1つの意味を持ちます: orders.created_at は常に日付、users.email は常にメールアドレスです。キーオーバーロードはそれを投げ捨てます。パーティションキーとソートキーに汎用的な名前 — pk、sk — を与え、各アイテム型がそこに別々の意味を注ぎ込めるようにします。1つのテーブル、多数のエンティティ、1つの形です。
DynamoDB のキーオーバーロードとは何ですか?
キーオーバーロードとは、多数のエンティティ型を pk/sk のような汎用的なキー名の下に1つのテーブルに保存し、型を値にエンコードする設計手法です(例: USER#u_3001、INVOICE#2026-0014)。属性名は中立のままにするので、ユーザー、請求書、イベントが1つのパーティションを共有できます。値が型を運び、ソートキーのプレフィックスにより begins_with を使った1回の Query で各エンティティをスライスできます。
- 汎用的なキー名、型付けされた値。 キーに
pk/skと名付け、エンティティの型を値に入れます:pk = "TENANT#acme"、sk = "USER#u_3001"。名前は無頓着で、値が型を運びます。 - これがシングルテーブル設計を機能させるもの。 オーバーロードがなければ、共有テーブルはただのガラクタ入れです。オーバーロードがあれば、すべてのエンティティが
Queryできるパーティションに収まります。 begins_withが見返り。 ソートキーの型プレフィックスにより、1回のQueryでエンティティ全体、またはその一部のスライスを、Scanもフィルタもなしに取り出せます。- コストは可読性。 生の
pk/skのダンプは何も教えてくれません。プレフィックスをデコードするビューアが必要で、さもなければ文字列を凝視することになります。
なぜ汎用的な名前が実名に勝るのか
DynamoDB はテーブルごとに正確に2つのキー属性を持ち、Query は単一のパーティションキーしかターゲットにできません。だからキーを userId と名付けると、そのテーブルにきれいに収まるのはユーザーアイテムだけになり、それ以外はすべて userId を偽装するか、独自のテーブルに移らなければなりません。
オーバーロードはそれを回避します。pk のような中立的な名前はどのエンティティにもコミットしないので、ユーザー、請求書、監査イベントがすべて同じキー属性と同じテーブルを共有できます。アイテムが何であるかを言うのは、属性名ではなく値です。
これがシングルテーブル設計を理論から実際に照会できるものへと変える一手です。共有テーブルはコンテナで、オーバーロードは別個のエンティティがその中で共存できるようにするものです。
マルチテナントの例
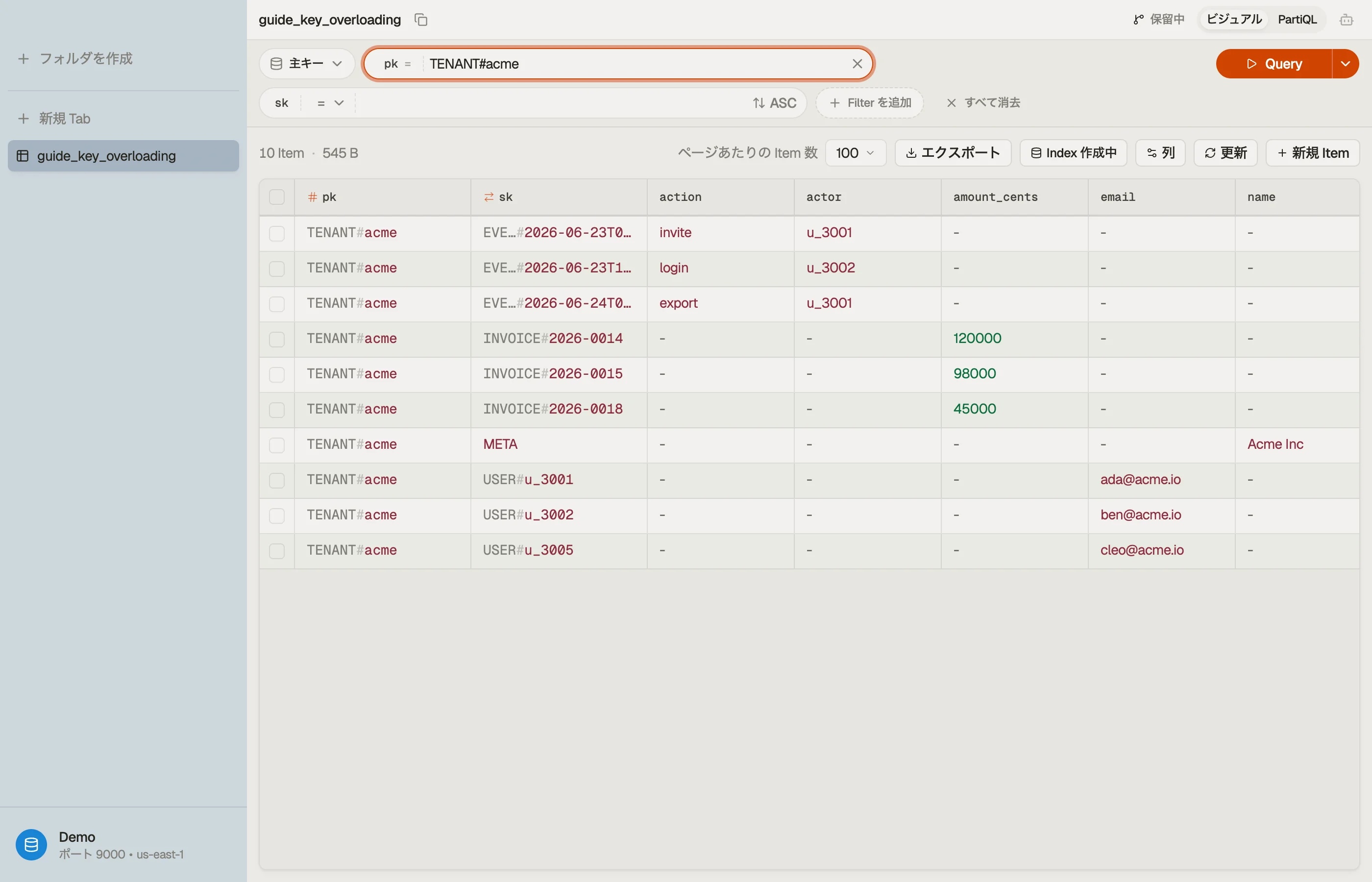
SaaS の課金製品を運用しているとします。各テナントにはメンバー、請求書、監査証跡があります。3つのテーブルの代わりに、それらすべてを1つに入れてキーをオーバーロードします:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
すべての行が pk = "TENANT#acme" を共有するので、1つのアイテムコレクションを形成します — すべて同じ場所に配置され、すべて単一のパーティション読み取りで到達可能です。
ソートキーのプレフィックスが本当の仕事をしています。エンティティをグループ化し、かつそれらを順序付けます。
オーバーロードされたコレクションを照会する
型がソートキーのプレフィックスに存在するので、begins_with は何もスキャンせずにパーティションをエンティティごとにスライスします:
Query pk = "TENANT#acme" -- テナント全体、すべての型
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- メンバーだけ
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- 請求書だけ条件が一致するアイテム分だけ料金を払い、パーティション全体ではありません — フィルタ付き Scan の逆です。フィルタ付きスキャンでは、読んで捨てる行の分まで料金を払います。AWS はこれをキーの条件と呼びます。データがパーティションから出る前に、キーに対して実行されます。
その begins_with 条件を手で構築する場合は、型タグを正しく書きましょう — USER# の代わりにうっかり USERS# と書くと、何も返らず、しかも何も警告されません。Expression Builder は、プレフィックスが実際に書いたものと一致するよう、KeyConditionExpression と ExpressionAttributeValues マップを生成します。
インデックスもオーバーロードする
同じコツが GSI にも適用されます。汎用的なキー名 — gsi1pk、gsi1sk — を与え、各エンティティが必要なものを何でも書けるようにします。すると1つのインデックスが、ベーステーブルにはできないパターンに答えます。
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
これで Query gsi1 WHERE gsi1pk = "STATUS#open" が、すべてのテナントにわたるすべての未払い請求書を、支払期日順でリストします — ベーステーブルのテナントスコープのキーでは決して提供できないクロスパーティションのビューです。別のエンティティが独自の意味で gsi1 を再利用できる(たとえば gsi1pk = "ROLE#admin")ので、1つのインデックスが複数の読み取りをカバーします。ただし GSI は結果整合性であることを覚えておきましょう — その書き込みはベーステーブルに遅れます。
DynoTable でやってみる
生のオーバーロードされたキーは読むのに敵対的です: INVOICE#2026-0015 と EVENT#2026-06-23T09:12Z はフラットなリストの中で混ざり合います。パーティションでグループ化してプレフィックスを浮かび上がらせるビューアが、ガラクタ入れをエンティティに戻します。


落とし穴
- 区切り文字は一度選んだら決して変えない。
#が慣例です。エンティティ間で#と:を混ぜると、何も警告されない形でbegins_withが壊れます。 - 範囲計算が必要な値をオーバーロードしない。
INVOICE#2026-0015というソートキーは数値ではなく辞書順でソートされます — ID をゼロ埋めし、ISO-8601 の日付を使って、文字列順が意図した順序と一致するようにしましょう。 - プレフィックスの名前空間を予約する。 どちらも
USERで始まる2つのエンティティ型(たとえばUSER#とUSERGROUP#)は、begins_with(sk, "USER")の下で衝突します。プレフィックスは最初の文字から曖昧でないようにしましょう。 - キーの前に読み取りを計画する。 オーバーロードは、列挙済みのアクセスパターンに奉仕します。まだ読み取りがわからないなら、まずシングルテーブル設計を参照してください — キーはクエリの下流にあります。
パーティションを描き出したら、DynoTable をダウンロードして、自分のオーバーロードされたキーを閲覧し、1回の Query がテナント全体をまとめて返す様子を観察しましょう。