DynamoDB のスパースインデックス
スパースインデックス は、そのキー属性を持つアイテムだけを保持するセカンダリ インデックスです — そのため、巨大なテーブルの小さくホットなサブセットが、それ自身の 事前フィルタ済みですぐにクエリできるコレクションになります。
数百万行があっても、一日中実行するクエリが触れるのはごく薄いスライスだけです。未対応の サポートチケット、未払いの請求書、レビュー対象としてフラグが立ったアカウント。
そのスライスをフィルタしても、それでもテーブル全体をスキャンし、すべての読み取り分を 課金されます。スパースインデックスは、代わりにインデックス自体を小さくします。
DynamoDB のスパースインデックスとは何か?
スパースインデックスは、そのキー属性を持つアイテムだけを保持するセカンダリインデックスです。DynamoDB はそのキーを持たないアイテムをスキップするため、対象アイテム(未対応チケット、未払い請求書など)だけが書き込むキーを設計すれば、インデックスはちょうどそのサブセットになります。クエリはそのインデックスだけを読み取り、フィルタも不要で、読み取りキャパシティを無駄にしません。
- セカンダリインデックスは、そのキーを持つアイテムだけをインデックスする。 アイテムで キーを省略すると、それはインデックスに一切入りません — プレースホルダーも null 行も ありません。
- だから、欲しいアイテムだけが持つキーを発明する。 クエリするアイテムに書き込み、 残りでは取り除きます。インデックスはちょうどそのサブセットになります。
- クエリはサブセットだけを読み、フィルタなし。 そのサイズはテーブル全体ではなく、 小さくホットな集合を追跡します。
REMOVEがレバーで、空白化ではない。 空文字列はそれでも値であり、それでも インデックスされます — 属性を削除しなければなりません。
問題:フィルタは読み取りを節約しない
SQL から来ると、WHERE 句が作業を狭めると思い込みます。DynamoDB の
FilterExpression はそうしません。アイテムが読まれた 後 に動き、前ではありません。
AWS デベロッパーガイド によれば、フィルタは「消費される読み取りキャパシティの量を削減しない」 — 調べたすべての アイテムに対して支払い、その後マッチしないものを捨てます。
つまり 500 万件のチケットのうち 50 件が未対応なら、フィルタ付きの Query/Scan は
数百万件を読み通してその 50 件を渡します。
それがあらゆる「なぜ私のスキャンはこんなに高価なのか」スレッドの裏にある落とし穴です。 Query と Scan にコスト全体像があります。
スパースインデックスは、インデックス自体を小さくすることでそれを回避します。
スパース性の仕組み
セカンダリインデックスは 実際にインデックスのキー属性を持つアイテムだけをインデックス します。
グローバルセカンダリインデックスに関する AWS ドキュメント は明快にこう述べています。「グローバルセカンダリインデックスには、そのインデックスに 定義されたキー属性を持つアイテムだけが含まれる」。
アイテムで GSI のパーティションキー(またはソートキー)を欠かすと、DynamoDB はそれを インデックスに書き込みません。プレースホルダーも null 行もありません — アイテムは不在 です。
その「デフォルトで不在」がトリックのすべてです。すべての アイテムが持つ status 属性を
インデックスしてはいけません。クエリしたいアイテムだけがそもそも持つ 属性を発明
しましょう。
そうすればインデックスはまさにそれらのアイテムのきれいなリストになり、それに対する
Query はそれらだけを読みます — フィルタなし、無駄なキャパシティなし。
キーを持つアイテムだけが渡る、ベーステーブルがインデックスに供給する様子を思い描いて ください。
キーを持つ(未対応の)アイテムだけがインデックスに複製され、完了したアイテムは一切 入りません。
これは シングルテーブル設計 と同じ、キーを形作る心構え です。キーはデータの忠実な鏡ではなく、特定のアクセスパターンのために作る道具です。
具体例:「未対応チケットのみ」
サポートチケットのテーブルを取り上げます。ベーステーブルは、チケットを id で取得し、 顧客のチケットを一覧するためにキーイングされています。
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
テーブルのライフタイムにわたって、ほとんどのチケットは最終的に 完了 します。しかし エージェントが一日中叩くダッシュボードのクエリは「すべての未対応チケットを古い順に見せて」 — 数百万の中に隠れた数百行です。
スパースインデックスの一手:パーティションキー openBucket、ソートキー openedAt の
GSI を定義し、openBucket を未対応チケットにのみ書き込みます。チケット作成時に設定し、
チケットが解決したら REMOVE します。
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← 未対応:インデックス内 |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← 未対応:インデックス内 |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← 完了:インデックスに含まれない |
チケット a91f と b02c は openBucket を持つため GSI に住みます。チケット 77de は
解決され openBucket が取り除かれたため、静かに脱落しました。ダッシュボードはこれで
1つの安価なクエリです。
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstこれは未対応チケットだけを読みます。チケットが完了するにつれて、インデックスはひとりでに 縮みます — そのサイズは 未対応 の母集団を追跡し、決して合計を追跡しません。
ここで1つの静的なパーティション値("OPEN")で問題ないのは、まさにその集合が小さく
保たれるからです。巨大な未対応集合にはシャーディングしたパーティションキーが必要に
なりますが、「小さなサブセット」インデックスこそ、1つの値が正しい選択になる場所です。
それを機能させる遷移は、単一の更新式 — チケットが解決したときに属性を取り除くこと — です。
ExpressionAttributeNames と :val プレースホルダーを自分で手組みする代わりに、その
REMOVE 句と読み取り側の型付きキー条件を
DynamoDB Expression Builder でプロトタイプ
しましょう。
DynoTable でやってみる
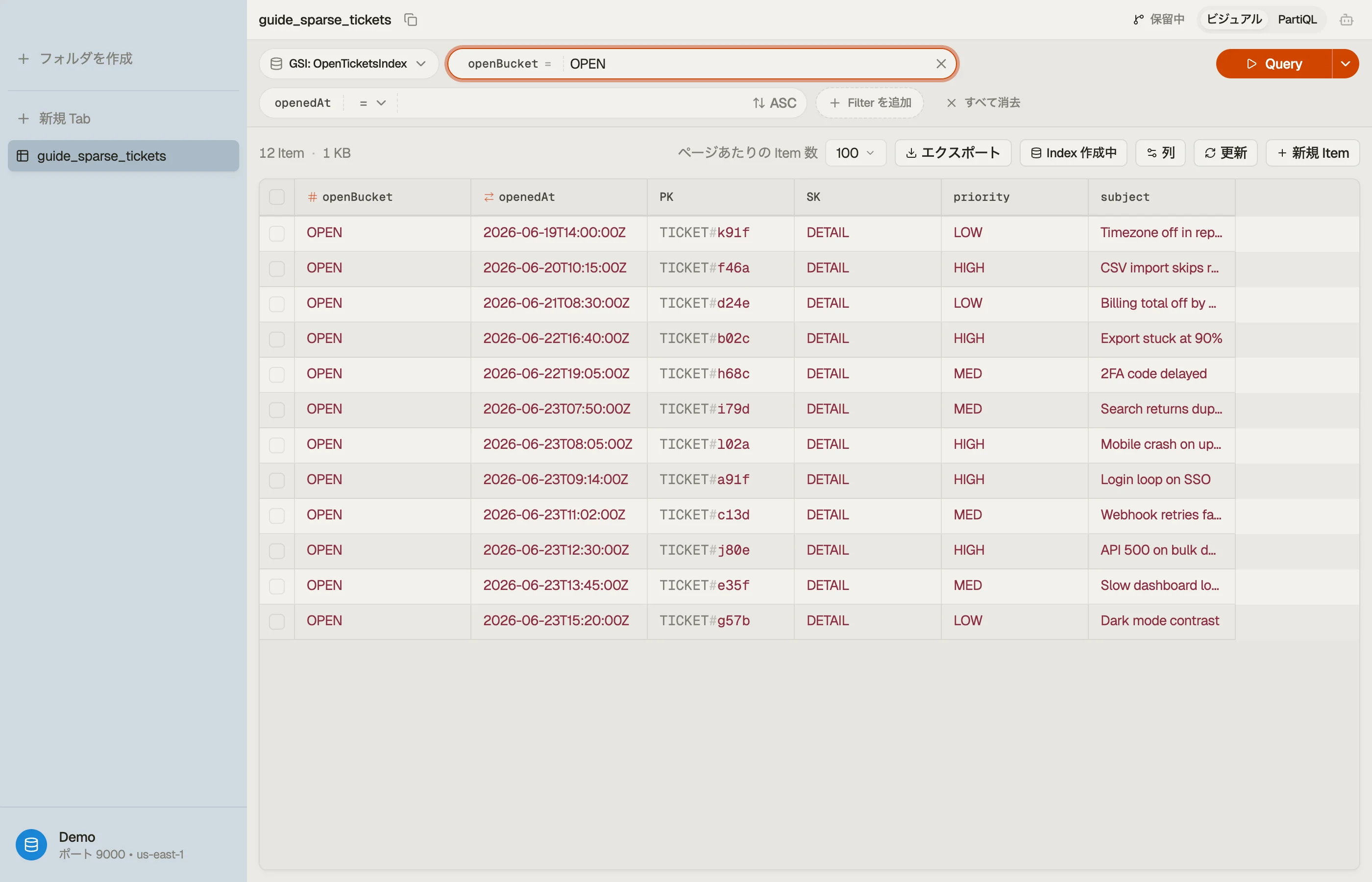
スパースインデックスの難しい部分は読み取りではありません — どのアイテムがインデックスに 入り、どれが静かに脱落したかを 見る ことです。
DynoTable は、テーブルビューをセカンダリインデックスに切り替えて、populate された
サブセットそのものを見せてくれます。解決済みチケットが、古いキーを残して居座るのではなく、
本当に open-tickets-index から去ったことを確認できます。


落とし穴と次のステップ
いくつか注意すべき点があります。
- キーを空白化するのではなく取り除く。 空文字列はそれでも値であり、DynamoDB は
openBucketが""のアイテムをインデックスします。アイテムをインデックスから落とす には属性をREMOVEしなければなりません — falsy な値に設定してもインデックスに残ります。 - インデックスは結果整合性。 GSI は非同期に更新されるため、解決したばかりのチケットが しばらく現れ続けることがあります — GSI 読み取りは 結果整合性のみをサポートします。 「このチケットは今この瞬間に未対応か」をそれに頼ってはいけません。
- 射影された属性に注意。 インデックスに対する
Queryは、そこに射影された属性だけを 返します。ダッシュボードが subject と priority を必要とするなら、それらを射影しましょう — さもなければベースアイテム全体を取得するための余分なGetItemを支払います。 - これは GSI の強みであって LSI の強みではない。 ローカルセカンダリインデックスは ベーステーブルのパーティションキーを共有し、このようにアイテムを選択的に落とせません。 GSI と LSI がトレードオフを分解します。
スパースインデックスは、このモデルで最も古いアイデアの1つです。原典の 2007 年の Amazon Dynamo 論文 は、既知の大量アクセスパターンを安価に提供することを中心にストアを構築しました。
スパースインデックスはまさにそれです。よくあるクエリが不要なものを一切読まないように キーを形作ります。
実際に1つを構築して検査するには、DynoTable をダウンロード し、テーブルに 向けて、データビューをスパース GSI に切り替えてください — アイテムがインデックスキーを 得たり失ったりするにつれて、サブセットが更新されるのを見てください。