DynamoDB の参照カウント
参照カウント とは、いくつの子アイテムがそれを指しているかを追跡するために、親アイテムに保存しておく数値です — 投稿へのいいね、ワークスペースのメンバー、コメントへの返信。読み取りのたびに子を数えるのは高くつくので、これを保持します。
DynamoDB でカウントを管理するにはどうすればよいですか?
実行中の合計を数値として親アイテムに保存し、子を作成するのと同じ書き込みで更新します。 を使えば両方が反映されるかどちらも反映されないかのどちらかになり、子の書き込みへの条件によって再試行が二重カウントするのを防ぎます — したがって、単一の GetItem で正確なカウントを取得できます。
- 読み取り時に子を数えない。 いいねを数える
Queryは、走査するすべてのいいねアイテムに対して課金される。合計を投稿に保存し、代わりに1アイテムを読む。 - 子が書き込まれる場所でカウントを維持する。 子を作成するのと同じ操作で加算し、両者が決してずれないようにする。
- 書き込みと加算が別々のアイテムに触れるときはトランザクションを使う。 いいねは1アイテム、カウントは別アイテムにある —
TransactWriteItemsが両方とも反映されるか、どちらも反映されないかを保証する。 - 地雷は二重カウント。 再試行または重複したいいねが increment を再実行すると数値が膨らむ。子の書き込みを条件でガードする。
そもそもなぜ数えるのか
SQL から来た人なら、いいね数を保存することはまずないでしょう — SELECT COUNT(*) FROM likes WHERE post_id = ? を投げ、インデックスに安くやらせます。DynamoDB には、アイテムの読み取りを省略する COUNT(*) がありません。
投稿のいいねに対する Query は、たとえ数だけが欲しくても、そのパーティションのすべてのいいねアイテムを読み — 課金します。バズった投稿では「いいねはいくつ?」に答えるのに数千 RCU かかります。これこそ参照カウントが葬るために存在する、読み取りの地雷です。
そこで 非正規化 します。実行中の合計を投稿そのものに保存するのです。カウントの読み取りは1回の GetItem になります。代償は、それを正確に保つ責任を自分で負うことです。
アイテムをモデリングする
2つのアイテム型がパーティションを共有し、投稿とそのいいねが1つのアイテムコレクションに収まるようにします。架空のキーです。
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
META アイテムの likeTally 属性が参照カウントです。各 LIKE# アイテムが子です。両方を PK = "POST#a91f" の下に置けば、リストが欲しいときに1回の Query で投稿といいねした人をまとめて取得できます。
カウントをアトミックに加算する
DynamoDB は ADD(または SET x = x + :n)の update 式で数値をインクリメントします — これは アトミックカウンター です。DynamoDB は現在の値を先に読まずにサーバー側でデルタを適用するため、並行するインクリメントが互いを上書きしません。(AWS: アトミックカウンター)
問題は、投稿にいいねするのが 2つ のアイテムへの 2回 の書き込みであることです — LIKE# アイテムを作成し、META の likeTally に 1 を加える。いいねは反映されたのに加算が失敗すると、集計は永遠に間違ったままです。両方か、どちらもなしが必要です。
それこそが TransactWriteItems が保証するものです — 複数アイテムにわたる all-or-nothing で、いずれかのアイテムが並行して変更されると、トランザクション全体をキャンセルします(AWS: トランザクションによる悲観的ロック)。
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Put と Update はまとめてコミットされます。どちらかが失敗すると、DynamoDB は両方をロールバックし、TransactionCanceledException を返します。
二重カウントをガードする
本当のバグは、いいねが半分だけ書かれることではありません — トランザクションがそれを防ぎます。それは 同じユーザーが2回いいねする こと、あるいはクライアントの再試行がリクエストを再生することです。再生のたびにもう1つ 1 が加わり、likeTally は真の数を超えてひっそりとずれていきます。
Put 上の ConditionExpression: attribute_not_exists(SK) がガードです。そのユーザーの LIKE# アイテムがすでに存在すれば、Put の条件が失敗し、トランザクション全体がキャンセルされ — 決定的に重要なことに — ADD は決して実行されません。ユーザーごとにいいね1つ、キーによって強制されます。
これらの update 式と条件式を — 正しい ExpressionAttributeValues と attribute_not_exists ガード付きで — JSON を手で組み立てるのではなく、DynamoDB 式ビルダーで構築してコピーしましょう。
いいね解除と、そのコスト
いいねの削除は鏡像です。ConditionExpression: attribute_exists(SK) で LIKE# アイテムを Delete し、同じトランザクションで ADD likeTally :minusOne する。この条件は、二重のいいね解除が集計をマイナスに駆り立てるのを止めます。
価格を知っておきましょう。トランザクション書き込みは、最大 1 KB のアイテムについて 1アイテムあたり 2 WCU かかります — 準備に1つ、コミットに1つ — 普通の書き込みの 1 WCU に対してです。いいねは2アイテムなので、いいね1つあたりおよそ4 WCU です。1アクションあたりは安いですが、有名人の投稿がいいねの嵐を浴びる前に知っておく価値があります。
DynoTable で見る
集計がずれた疑いがあるとき、本番でカウントクエリを走らせずに、保存された likeTally を実際の LIKE# 子の数と比べたくなります。

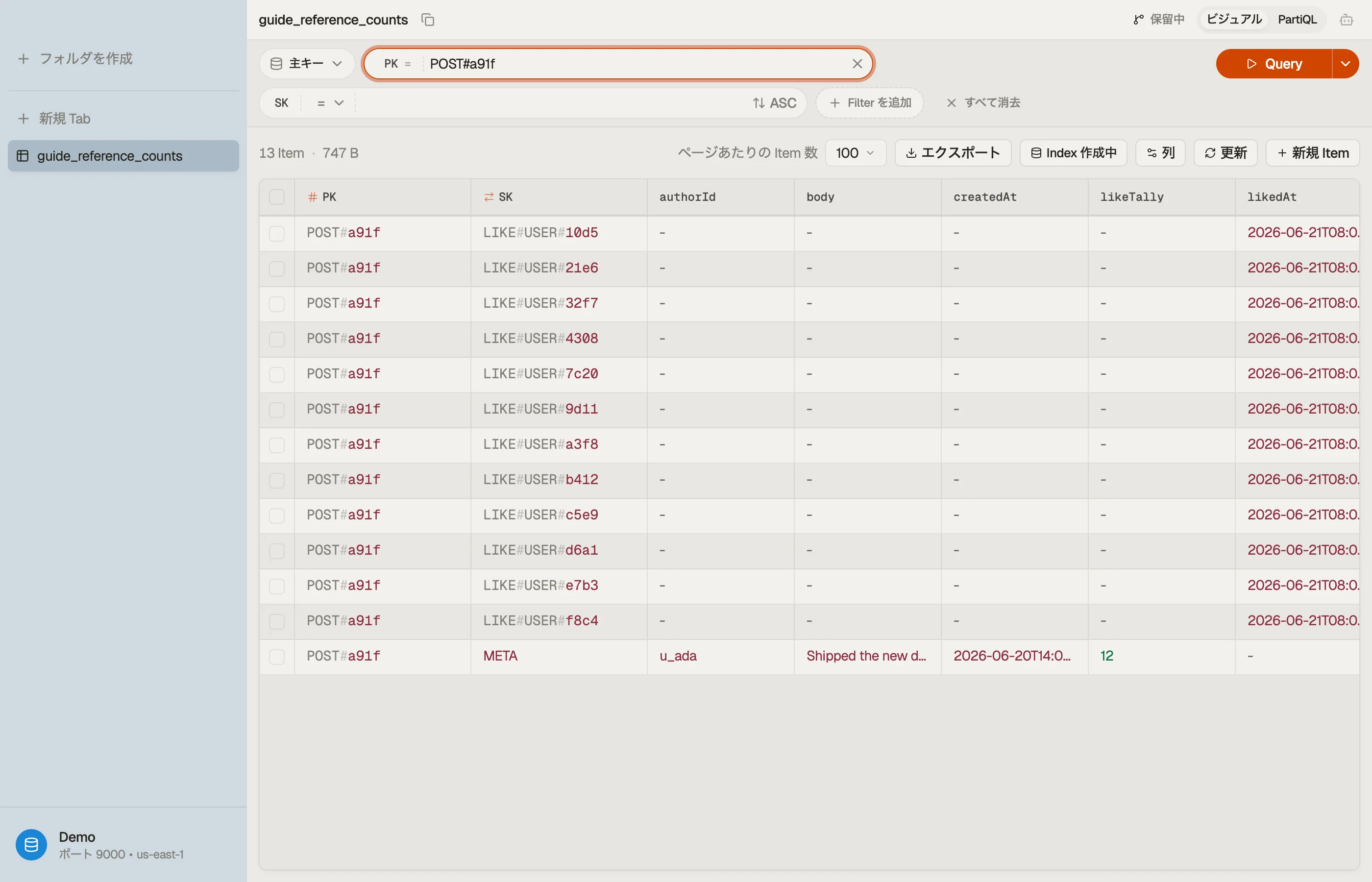

範囲を区切った投稿の集合に対する本当の照合 — 「どの集計が子の数と一致しないか?」 — のためには、DynoTable の SQL Workbench が、読み込んだ行に対して GROUP BY と join をクライアント側で実行します。プレーンな PartiQL ではこれを表現できません。
落とし穴と次のステップ
- カウントを帯域外で維持しない(毎晩数え直す Lambda など)。それは、最初からトランザクショナルであるべきだった書き込み経路への絆創膏だ。
- ホットパーティションに注意。 1つの極端に人気の投稿は、あらゆるいいね — そしてあらゆる集計の加算 — を1つのパーティションキーに集中させる。カウントは正しいが、パーティションは依然としてスロットルされうる。
- 照合は稀に、修復は外科的に。 すべての変更が条件付きなら、ずれはほぼゼロのはず。不一致は見つけるべきバグであって、上書きすべき数値ではない。
関連する読みもの: 投稿といいねがパーティションを共有する理由はシングルテーブル設計、読み取り時に子を数えるのが避けるべきパターンである理由はQuery と Scan。
そしてDynoTable をダウンロードして、これらのアイテムコレクションを調べ、自分のテーブルに対して集計を検証しましょう。