DynamoDB の複合ソートキー
複合プライマリキーはパーティションキーとソートキーの組み合わせです。それを強力にするコツは、ソートキーの中に何を入れるかにあります。階層を1つの区切り文字付きの文字列としてエンコードすれば、単一の Query がソート順でサブツリー全体を読み取ります — 結合も、再帰も、2回目の往復もなしに。
DynamoDB の複合ソートキーはどのように機能するのか?
複合ソートキーは、階層を1つの区切り文字付きの文字列(root/photos/2026/)に詰め込み、DynamoDB はそれを UTF-8 バイト順で保存します。このレイアウトがすでにツリーと一致しているため、begins_with(SK, "root/photos/") を使った単一の Query でサブツリー全体をパス順に読み取れます。結合も、再帰も、2回目の往復もなく — 連続したスライスに対するプレフィックススキャンだけです。
- ソートキーはソート可能な文字列であって、単なる ID ではない。 パスを詰め込めば(
root/photos/2026/)、DynamoDB はパーティション内のアイテムを自動的に UTF-8 バイト順で保存します。 - 区切り文字がプレフィックス一致をサブツリー読み取りに変える。
begins_with(SK, "root/photos/")は、そのフォルダのすべての子孫を1回のクエリで返します。 - ソートキーは範囲条件に対応するが、任意のフィルタには対応しない。 使えるのは
begins_with、between、>、<です。必要な読み取りがプレフィックスか範囲になるようにキーを設計しましょう。Scanではなく。 - 区切り文字が重要な役割を担う。 パスのセグメントに現れ得ないものを選ばないと、無関係な2つのブランチが衝突します。
なぜソートキーがすべてなのか
SQL の出身者なら、フォルダツリーを parent_id の自己結合でモデル化し、再帰的に辿るでしょう — 階層ごとに1クエリです。DynamoDB では、それは結合を持たないキーバリューストアに対する N+1 の罠になります。
DynamoDB はすべてのアイテムを、パーティションキーの下でソートキーでソートして保存します。文字列の場合は UTF-8 バイト順です(AWS: Query キー条件)。だからソートキーがパスそのものなら、物理的なレイアウトはすでにツリーと一致しています。読み取りは、グラフ探索ではなく、連続したスライスに対するプレフィックススキャンになります。
それが転換点です。ソートキーは正確に一致させる識別子ではありません。ソート可能なアドレスです。それを設計すれば、クエリは自然と導き出されます。
ファイルシステムツリーをモデル化する
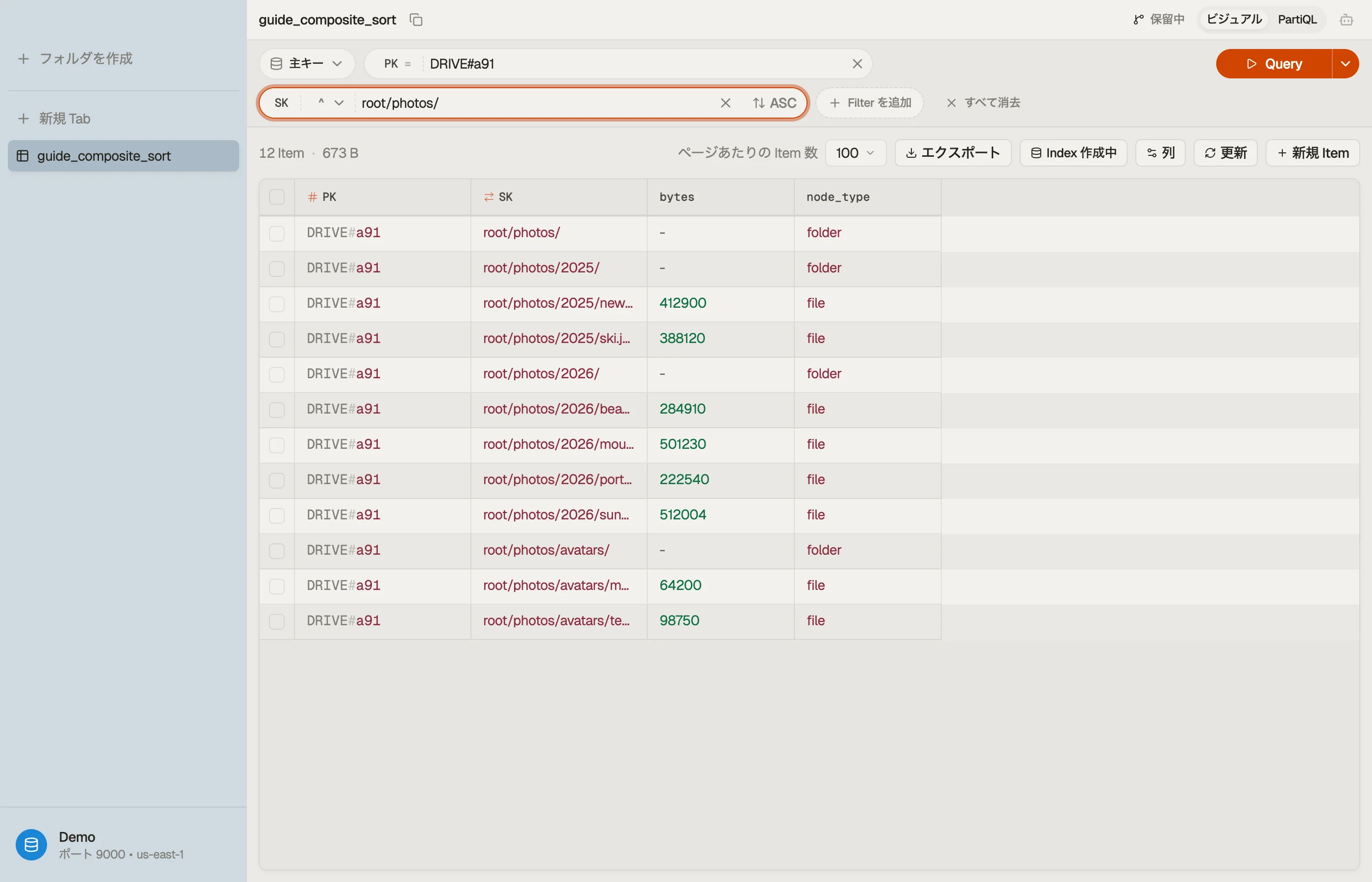
アカウントごとのファイルツリーを保存しているとします。アカウントごとに1つのドライブが自然なパーティションで、その中のパスがソートキーです。
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
ここで2つの独自の規約が仕事をしています:
PK = DRIVE#<account>は、1つのアカウントのツリー全体を単一のアイテムコレクションに保ち、どのサブツリー読み取りも単一パーティションのQueryになるようにします。SKはフルパスで、フォルダには末尾に/を付けます。末尾のスラッシュは意図的です。フォルダがその子よりも前にソートされるようにし、root/photos/をroot/photosという名前の兄弟ファイルと区別された状態に保ちます。
サブツリーを1回のクエリで読む
root/photos/ の配下すべて(フォルダ、サブフォルダ、ファイル)を再帰的にリストする:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"これは root/photos/、root/photos/2026/、beach.jpg、sunset.jpg を、パス順に、1回の課金対象の読み取りで返します。ドライブ全体ではなく、そのスライス内のアイテム分だけ料金を払います。
DynoTable では、パスのソートキーに対してこの begins_with クエリをそのまま実行でき、フォルダとその子孫がパス順で返ってきます — プレースホルダ構文を手書きする必要はありません。
自分のコード用にそのままの KeyConditionExpression(名前、値、begins_with)が必要ですか?DynamoDB Expression Builder で構築してコピーできます。


サブツリー全体ではなく1階層だけリストする
begins_with は再帰的な読み取りを提供します。非再帰的なディレクトリのリスト(root/photos/ の直接の子だけで、それより深いものは含まない)には、depth 属性を保存してソートキーの範囲とフィルタを加えるか、パスを parent GSI に分割します。最も簡単な方法は、parent 属性(root/photos/)を保持し、それをキーにした GSI を持つことです。
要点はこうです。ソートキーはプレフィックスと範囲の問いに安価に答えます。「直接の子だけ」は別の問いです。FilterExpression が効率的にしてくれることを期待するのではなく、明示的にモデル化しましょう。フィルタは読み取りの後に実行され、捨てるアイテムの分まで料金を払うことになります。
区切り文字を慎重に選ぶ
区切り文字はデータ契約の一部です。2つのルール:
- パスのセグメント内に決して現れてはならない。 ファイル名に
/が含まれ得るなら、/は間違った区切り文字です —a/bという名前のファイルは、bを保持するaというフォルダと区別がつきません。予約されたバイト(チームによっては#や制御文字を使います)を選び、セグメント内では禁止しましょう。 - 境界でのソート順に注意。
/(0x2F)は数字や文字よりも前にソートされ、これは通常ツリー順に望ましいものです。区切り文字を変えると順序が変わるので、実データに対して検証しましょう。
複合ソートキー vs. 別個のソート属性
複合ソートキー (root/photos/2026/x) | プレーンな ID ソートキー + parent 属性 | |
|---|---|---|
| サブツリー読み取り | 1回の begins_with クエリ | 再帰クエリ (N+1) または GSI 探索 |
| 順序付け | パス順、無料 | 明示的なソート属性を追加する必要あり |
| 移動 / リネーム | すべての子孫を書き換え | parent ポインタを1つ更新 |
| 直接の子のリスト | depth 属性または GSI が必要 | 自然 (parent = x) |
複合キーが勝つのは、読み取りがサブツリー型で順序が重要なときです。フラットな ID モデルが勝つのは、ツリーが絶えず変化するときです。ほとんどの読み取り中心の階層 — ファイルツリー、カテゴリツリー、組織図 — は複合に傾きます。
落とし穴と次のステップ
- キーに詰め込みすぎない。 エンコードしたものはすべて不変で、プレフィックスでのみインデックスされます。等価で照会する属性は、ソートキーに押し込むのではなく、独自のフィールドか GSI に置くべきです。
- ソートキーは任意の
WHEREをこなせない。 使えるのはbegins_with、between、比較だけです。FilterExpressionに手を伸ばしている自分に気づいたら、おそらくキーのモデル化を誤っています — Query と Scan の比較を参照してください。 - キー設計をさらに深掘りするならシングルテーブル設計に、サブツリー読み取りにベーステーブルではなくインデックスが必要なときは GSI と LSI の比較にあります。
Expression Builder で begins_with のキー条件を構築し、DynoTable をダウンロードして、これらのプレフィックスクエリを自分のテーブルに対して実行し、サブツリーがパス順に返ってくる様子を観察してください。