DynamoDB の隣接リストパターン
グラフはノードとエッジにすぎず、隣接リストパターンはその両方を1つのテーブルのプレーンなアイテムとして保存します。各エッジは、パーティションキーがソースノード、ソートキーがターゲットである行になります。パーティションを照会すると、すべての隣接ノードがリストされます — 結合テーブルに対する JOIN の DynamoDB 版です。
DynamoDB の隣接リストパターンとは?
隣接リストパターンは、グラフを1つのテーブルのエッジアイテムとしてモデル化します。各リレーションシップ(A が B をフォロー)は、パーティションキーにソース、ソートキーにターゲットを持つ1つの行です。パーティションを照会すればすべての隣接ノードがリストされ、反転した GSI がリレーションシップを逆転させます — 結合なし、スキャンなしで、両方向が1回のクエリで手に入ります。
- エッジはアイテム。 各リレーションシップ(ユーザー A がユーザー B をフォロー)を、ソースをパーティションキー、ターゲットをソートキーにした独自のアイテムとしてモデル化します。
- 一方向は無料、もう一方向は GSI が必要。 ベーステーブルは「A は誰をフォローしているか?」に答えます。反転したインデックスは「誰が A をフォローしているか?」に答えます。
- 結合なし、スキャンなし。 どちらの方向も、既知のパーティションに対する1回の
Queryです — 決してテーブル全体のScanではありません。 - これは多対多のプリミティブ。 フォロー、メンバーシップ、いいね、友達関係 — 1つのエンティティが多数の他のエンティティに接続するどんなグラフも、この形に当てはまります。
アクセスパターンとして捉える
SQL の出身者には、フォローグラフは結合テーブルです: follows(follower_id, followee_id)。誰かのフォロワーをリストするには一方の列にインデックスを張り、誰をフォローしているかをリストするにはもう一方にインデックスを張ります。DynamoDB には結合がないので、各読み取りに直接奉仕するようにキーを設計します。
まず読み取りを書き出しましょう。ソーシャルのフォローグラフでは:
- ユーザー A は誰をフォローしているか?(彼らのフォロー中のリスト)
- 誰が ユーザー A をフォローしているか?(彼らのフォロワーのリスト)
- A は B をフォローしているか?(単一のポイントルックアップ)
キーはそのリストに答えるためだけに存在します。それらを正しく設計すれば、すべての読み取りが1回の Query か GetItem になります。
エッジをアイテムとしてモデル化する
テーブルが複数のエンティティ型を保持できるよう汎用的なキー名を使い、ノードの型を値にエンコードします。フォローエッジはこのようになります:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice はエッジのソースで、SK = TARGET#bob は彼女がフォローしている相手です。1回の Query PK = "ACTOR#alice" で、Alice がフォローしているすべてのアカウントが1回の課金対象の読み取りで返ります — 結合なしの、彼女のフォロー中のリスト全体です。
各エッジは「私がフォローしている相手」の方向で1度だけ書き込まれます。逆方向(「私をフォローしている相手」)は、ベーステーブルがまだ答えられない部分です。
もう一方向を GSI で辿る
ベーステーブルはソースを先頭にキー付けされているので、スキャンなしには「誰が Bob をフォローしているか?」に答えられません。キーを反転させるグローバルセカンダリインデックスを追加します。ターゲットをインデックスのパーティションキーに、ソースをインデックスのソートキーに投影します。
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
これで Query GSI1 WHERE GSI1PK = "TARGET#bob" が、Bob をフォローしている全員 — alice と dave — を1回の読み取りでリストします。同じエッジアイテムが両方向に奉仕します。ベーステーブルはフォロー中、インデックスはフォロワーです。各エッジを1度書き込めば、両方のクエリが無料で手に入ります。
これはまさに、AWS が DynamoDB のベストプラクティスガイドで、多対多のリレーションシップとグラフデータのモデル化のために文書化しているパターンです — エッジをアイテムとして保存し、それから GSI を使ってリレーションシップを反転させます。
単一のエッジを安価にチェックする
「Alice は Bob をフォローしているか?」はどちらのリストも必要としません。エッジが PK = ACTOR#alice、SK = TARGET#bob でキー付けされているので、これは直接の GetItem です — DynamoDB が提供する最も安価な読み取りで、Query もインデックスも不要です。
フォローを冪等に書き込み、二重カウントを避けるには、エッジがまだ存在しないという条件で PutItem をガードします:
attribute_not_exists(PK)その条件 — そしてマーシャリングされたキーの値 — は、ConditionExpression と ExpressionAttributeValues を手書きする代わりに、DynamoDB Expression Builder で組み立てられます。
DynoTable でやってみる
テーブルを閲覧すると、1人のアクターのエッジが単一のパーティションキーの下に1つのアイテムコレクションとして積み重なり、GSI ビューに切り替えると反転したフォロワーリストが表示されます — リレーションシップの2つの半分が並んで見えます。

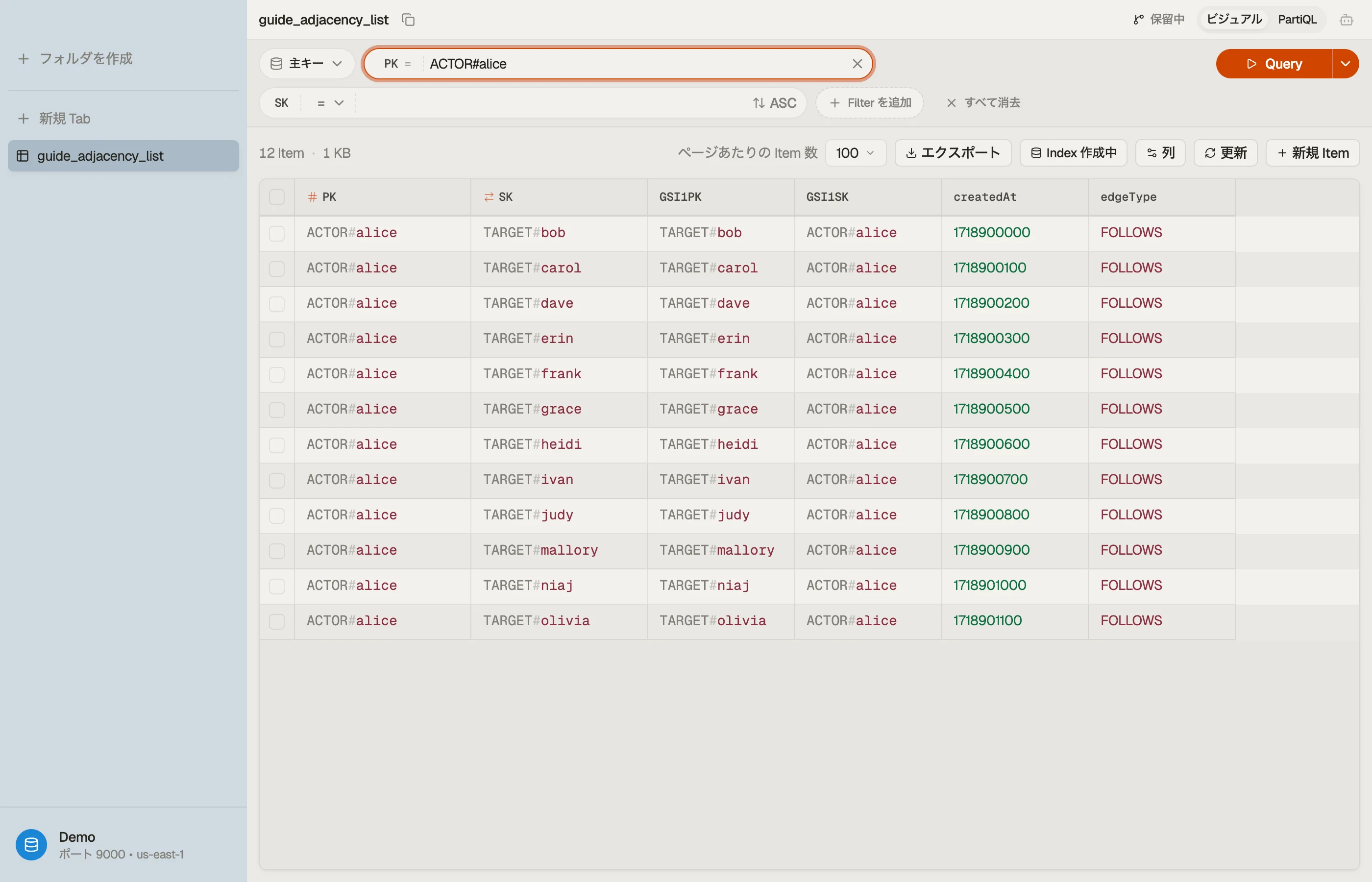

落とし穴
人気者のパーティション。 数百万人のフォロワーを持つユーザーは、すべてのフォロワーエッジを1つの GSI1PK = TARGET#<star> パーティションの下に集中させます。そのコレクションの読み取りはページネーションされ、ホットになり得ます。ファンアウトの多いグラフでは、ホットキーをシャーディングする(例: TARGET#bob#0..N)か、リスト全体を再読み取りしなくて済むようカウントを非正規化しましょう。
エッジにカウントを保存すること。 フォロワー数はエッジではありません — プロフィール表示のたびにパーティション全体を読んで数えることで導出してはいけません。ユーザーアイテムにカウンタ属性を維持し、それをエッジとトランザクションで更新しましょう。
ここでは逆方向の書き込みが不要であることを忘れること。 古典的な隣接リストの変種は、ID を入れ替えてエッジを2度書き込みます。キー反転の GSI なら、エッジを1度書き込み、インデックスに逆方向をマテリアライズさせます — 書き込みが少なく、2つのコピー間のずれもありません。
次のステップ
隣接リストはシングルテーブル設計のリレーションシップの構成要素です。反転インデックスは LSI ではなく GSI です。パーティションキーが変わるからです。そしてここでのすべての読み取りは、既知のキーに対する Query か GetItem です — 決して Scan の罠ではありません。
DynamoDB Expression Builder で条件式とキー式を構築し、DynoTable をダウンロードして、自分のテーブルに対してフォローグラフをモデル化し、両方向が1回の読み取りで解決される様子を観察しましょう。