Les relations un-à-plusieurs dans DynamoDB
Un plan de contrôle SaaS a presque toujours une hiérarchie de containment : un
espace de travail possède plusieurs projets. En SQL, tu poserais une clé
étrangère workspace_id sur la table des projets et tu ferais un JOIN.
DynamoDB n'a ni jointures ni clés étrangères, donc la relation doit vivre dans le
schéma de clés lui-même. Bien fait, « charger un espace de travail et chacun
de ses projets » devient un seul Query au lieu d'une lecture plus un scan de
suivi.
Comment modéliser une relation un-à-plusieurs dans DynamoDB ?
Donne au parent et à tous ses enfants la même pour qu'ils partagent une seule , puis différencie-les avec la clé de tri. DynamoDB n'a ni jointures ni clés étrangères, donc la relation vit dans le schéma de clés lui-même. Charger un parent et chacun de ses enfants devient alors un seul Query au lieu d'une jointure.
- Modélise les lectures, pas les entités. La relation un-à-plusieurs n'existe que pour servir « lister les projets d'un espace de travail » — façonne les clés autour de cette requête.
- Encode le parent dans la clé de partition de l'enfant. Donne à l'espace de travail et à tous ses projets la même valeur de clé de partition pour qu'ils atterrissent dans une seule item collection.
- Alors la lecture de la liste est un seul
Query. Le parent plus un nombre arbitraire d'enfants reviennent dans un unique appel facturé — pas de jointure, pas de second aller-retour. - Surveille la partition chaude. Un énorme locataire concentre tout son trafic sur une seule partition ; un espace de travail gigantesque peut nécessiter une clé partitionnée (sharded) et une lecture en éventail.
D'abord le motif d'accès
La modélisation DynamoDB part des motifs d'accès, pas des entités — la même discipline derrière le single-table design. Avant de choisir une clé, écris les lectures que l'application émet réellement :
- Récupérer les paramètres d'un espace de travail.
- Lister chaque projet d'un espace de travail, du plus récent au plus ancien.
- Récupérer un projet précis par son id.
La relation « un espace de travail, plusieurs projets » ne compte qu'à cause de la lecture nº 2. Si tu n'avais jamais besoin de lister ensemble les projets d'un espace de travail, tu ne modéliserais pas du tout la relation — tu stockerais les projets indépendamment.
Donc la question n'est jamais « comment représenter le un-à-plusieurs ? » dans l'abstrait. C'est « quelles requêtes cette relation doit-elle servir ? ». Réponds à ça, puis façonne les clés autour.
Pourquoi une clé étrangère n'aide pas ici
Dans DynamoDB chaque GetItem et Query cible une clé de partition, et le
service hache cette clé pour localiser la partition qui contient l'item.
AWS le dit directement dans la doc Core Components : la valeur de la clé de partition est l'entrée d'une fonction de hachage interne qui décide où vivent les données.
Ce placement par hachage est l'héritage du papier original de 2007 Dynamo : Amazon's Highly Available Key-value Store, où le hachage cohérent distribue les clés entre les nœuds.
Un simple attribut workspace_id sur un item projet est invisible à cette
mécanique — DynamoDB ne peut pas le « suivre ».
Pour récupérer des items liés en une seule requête, l'identité du parent doit être
encodée dans la clé de partition du projet, afin que tous les items d'un espace
de travail hachent vers la même partition et qu'un seul Query puisse les balayer.
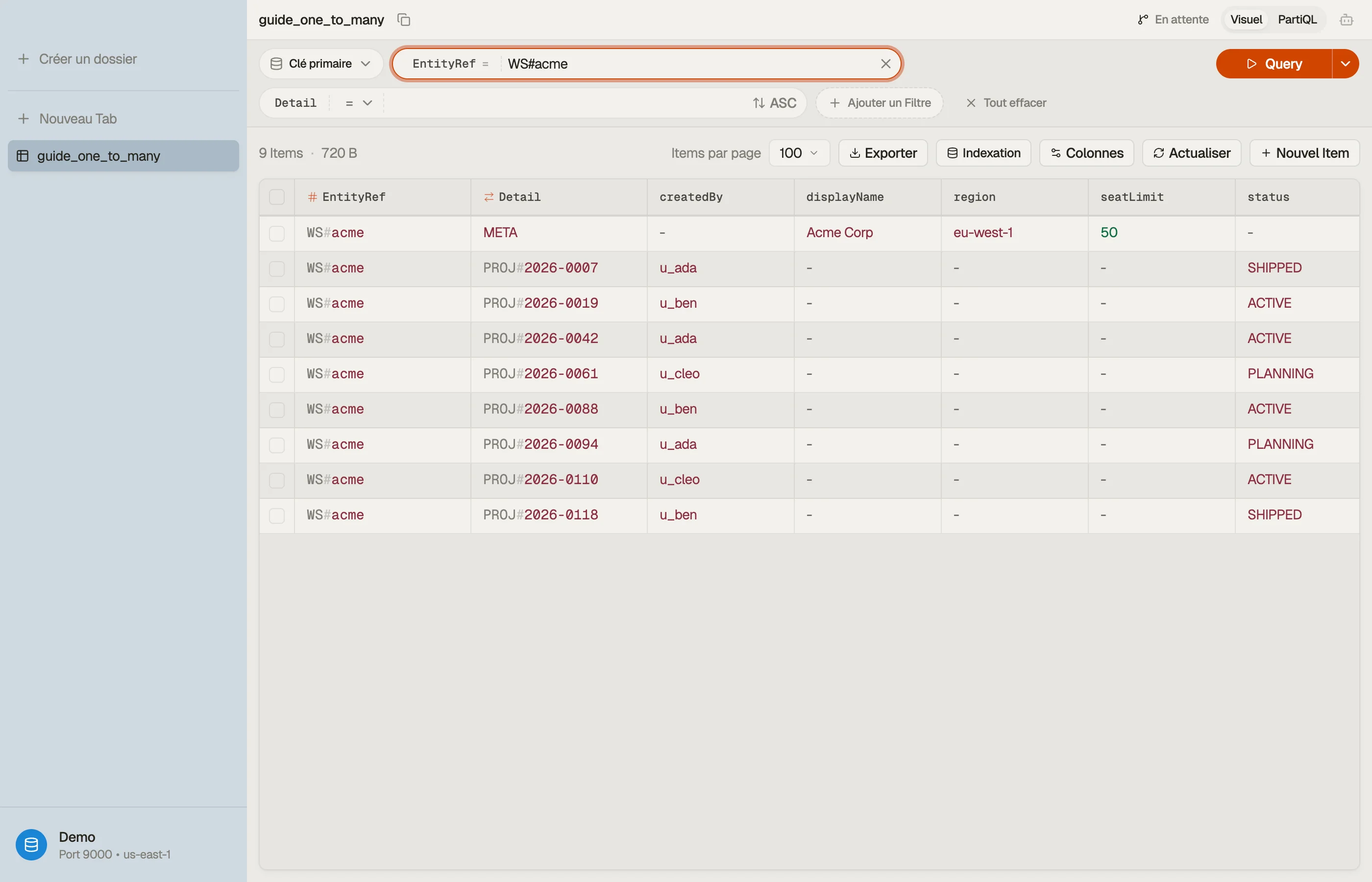
Exemple travaillé : espaces de travail et projets
Utilise un schéma de clés générique et surchargé. Appelle la clé de partition
EntityRef et la clé de tri Detail. L'identité de l'espace de travail va dans
EntityRef pour à la fois l'item de l'espace de travail et chaque projet en
dessous :
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
L'espace de travail et tous ses projets partagent EntityRef = "WS#acme", donc
ils forment une seule item collection qui vit ensemble sur une partition.
La clé de tri Detail les sépare : META est l'enregistrement de l'espace de
travail, et chaque projet porte un préfixe PROJ# avec un id ordonné dans le temps
et complété par des zéros, de sorte que les projets se trient naturellement.
Visuellement, le parent et ses enfants s'empilent dans une seule partition, ordonnés par la clé de tri :
Un seul Query sur EntityRef = "WS#acme" balaie toute la pile — le parent plus
chaque enfant — en une seule lecture.
Les trois motifs d'accès se réduisent alors chacun à un seul appel :
- Paramètres de l'espace de travail —
GetItem(EntityRef="WS#acme", Detail="META"). - Lister les projets du plus récent au plus ancien —
Query(EntityRef="WS#acme")avecDetail begins_with "PROJ#", exécuté en ordre décroissant (ScanIndexForward = false). - Un projet —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
Le deuxième est tout l'intérêt : le parent et un nombre arbitraire d'enfants
reviennent dans un seul Query facturé, pas de jointure et pas de second
aller-retour. C'est le coup que tu ne peux pas faire avec un attribut clé étrangère
et un Scan.
Écrire cette condition begins_with à la main est délicat — la syntaxe de la
condition de clé et de l'expression de projection mord.
Le DynamoDB Expression Builder génère la
KeyConditionExpression, les maps de placeholders #name/:value, et un extrait
SDK prêt à exécuter pour que tu ne te battes pas avec la grammaire :
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Inspecte l'item collection dans DynoTable
Le bénéfice de cette disposition est visuel : chaque ligne partageant un
EntityRef est l'espace de travail plus ses enfants, côte à côte.
DynoTable les groupe pour que tu voies la relation un-à-plusieurs comme un bloc contigu unique au lieu de la deviner à travers des tables séparées.


Pièges et la forme alternative
Quelques points à surveiller :
- Partitions chaudes. Chaque item d'un espace de travail vit sur une seule
partition, donc un unique locataire très grand ou très occupé concentre le
trafic. Le comportement d'adaptive capacity
qu'AWS décrit absorbe un déséquilibre modéré, mais un espace de travail avec des
millions de projets peut nécessiter une clé partitionnée (p. ex.
WS#acme#01 … #10) et une lecture en éventail. - Taille de l'item collection. Avec un local secondary index, l'item collection d'une partition est plafonnée à 10 Go ; sans LSI il n'y a pas de telle limite. Si tu pèses les types d'index ici, vois GSI vs LSI.
- Utilise
Query, jamaisScan. Toute la conception existe pour que tu puissesQueryune partition. Retomber sur unScanfiltré pour « trouver les projets d'un espace de travail » jette le modèle et lit toute la table — le piège couvert dans Query vs Scan.
Si tu as vraiment besoin de lister les projets à travers les espaces de travail
(disons, tous les projets status = ACTIVE globalement), la table de base ne peut
pas répondre à ça — sa clé de partition est limitée à l'espace de travail.
C'est le travail d'un index secondaire qui repartitionne les projets sur un autre attribut, pas un remodelage de cette relation.
Étapes suivantes
Modélise les motifs d'accès, encode le parent dans la clé de partition de l'enfant,
et la lecture un-à-plusieurs est un seul Query. Construis et valide la condition
de clé avec le DynamoDB Expression Builder.
Puis télécharge DynoTable pour charger ce schéma, parcourir l'item collection espace de travail→projets en direct, et confirmer que chaque requête fait exactement une lecture.