Projections d'index DynamoDB : KEYS_ONLY, INCLUDE et ALL
Quand tu crées un index secondaire, DynamoDB ne copie pas automatiquement l'item entier dedans. Tu choisis ce qui est copié — la projection de l'index. Choisis trop peu et tes requêtes paient une seconde lecture pour récupérer le reste ; choisis tout et tu paies du stockage et un coût d'écriture supplémentaires à chaque mise à jour. C'est un compromis que tu fixes une fois à la création de l'index et avec lequel tu vis.
(Ne confonds pas ça avec une projection expression, qui réduit les attributs qu'une seule lecture renvoie. Cette page porte sur ce qu'un index stocke physiquement — vois les projection expressions pour l'autre.)
Qu'est-ce qu'une projection d'index DynamoDB ?
Une projection est l'ensemble des attributs que DynamoDB copie de la table de base vers un index secondaire. Tu choisis l'un des trois types : KEYS_ONLY (uniquement les clés), INCLUDE (les clés plus une liste nommée d'attributs) ou ALL (l'item entier). Plus de projection signifie moins de lectures sur la table de base, mais un coût de stockage et d'écriture plus élevé.
- Une projection est l'ensemble des attributs copiés dans un index secondaire.
KEYS_ONLY— uniquement les clés de la table et de l'index. La plus petite, la moins chère.INCLUDE— les clés plus une liste nommée d'attributs supplémentaires que tu choisis.ALL— chaque attribut de l'item. La plus grande ; les requêtes n'ont jamais besoin de la table de base.- Lire un attribut qui n'est pas projeté force une récupération depuis la table de base pour un GSI — un coût supplémentaire silencieux. (Un LSI peut récupérer pour toi des attributs non projetés, à un coût de lecture supplémentaire.)
- Plus de projection = plus de stockage + plus de coût d'écriture, puisque chaque écriture sur la table de base se propage vers l'index.
Le problème : l'index qui te fait lire deux fois
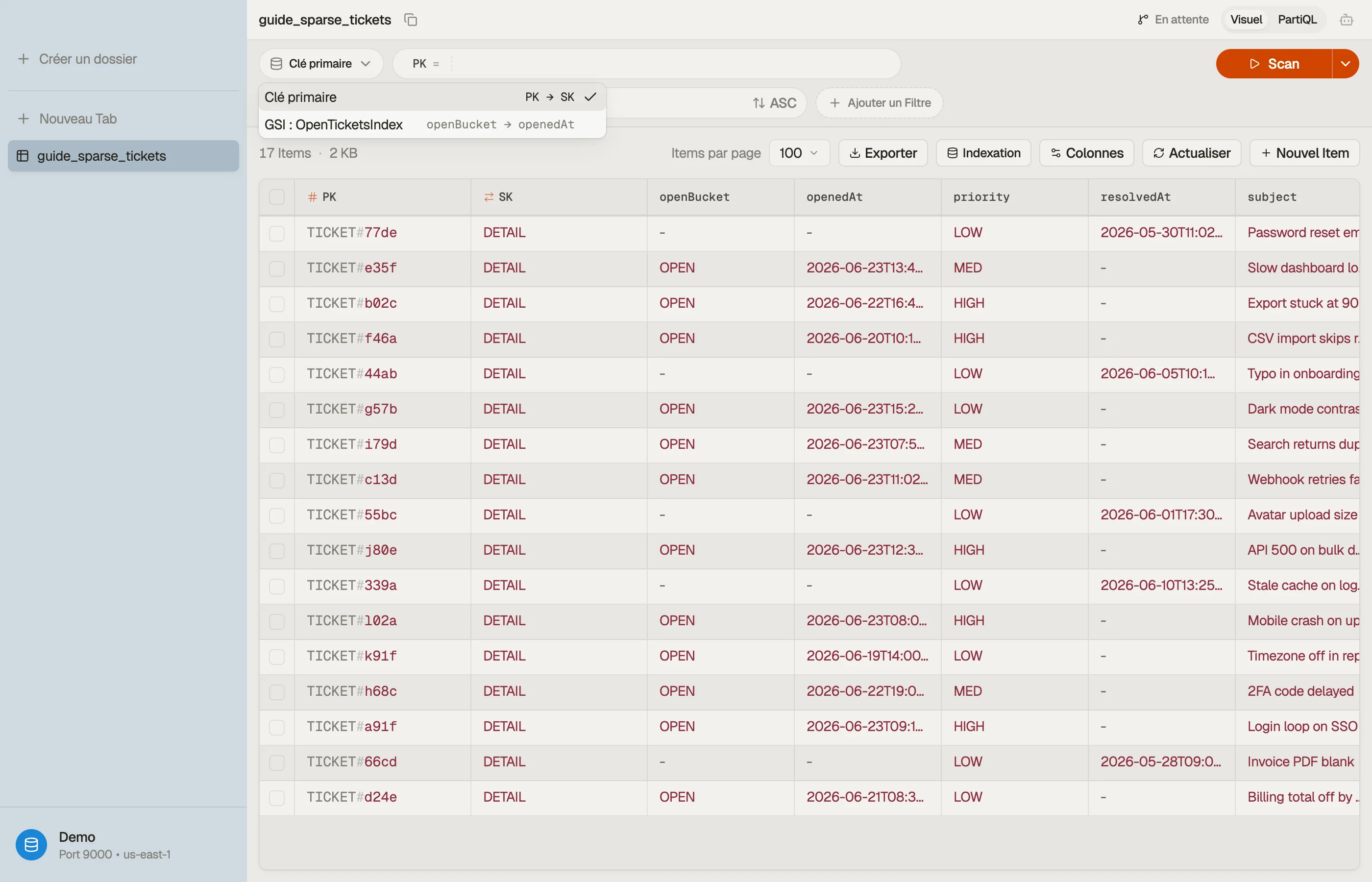
Disons que tu gères un service d'assistance avec un GSI qui te permet de lister les
tickets ouverts par priorité. Tu projettes KEYS_ONLY pour rester léger. La requête
revient vite — mais elle ne te donne que des ID de tickets, et ton écran de file
d'attente a besoin du sujet, de l'assigné et de l'ancienneté de chaque ticket.
Alors maintenant ton code fait une seconde série de lectures contre la table de base pour hydrater chaque résultat. La « requête unique » que tu as conçue est en réalité une requête plus N gets, et la latence et le coût que tu essayais d'économiser sont revenus aussitôt. La projection était trop maigre pour le motif d'accès.
Ce que chaque type de projection copie
KEYS_ONLYstocke juste la clé de la table de base et la clé de l'index. Utilise-la quand la requête a seulement besoin de savoir quels items correspondent et que tu récupéreras les détails ailleurs — ou pas du tout.INCLUDEstocke les clés plus une liste fixe d'attributs que tu nommes. Le point idéal : projette exactement les champs dont ta requête a besoin pour s'afficher, et rien de plus.ALLcopie l'item entier. Les requêtes sont entièrement auto-servies depuis l'index, au prix de la duplication du stockage et du débit d'écriture de tout l'item dedans.
Pour la file d'attente du service d'assistance, INCLUDE avec subject, assignee et
age est le bon choix — la file se rend depuis l'index seul, sans seconde récupération
et sans dupliquer le volumineux body du ticket dans l'index.
Le coût que tu échanges
Chaque attribut que tu projettes est
stocké une seconde fois
et réécrit dans l'index chaque fois que l'item de base change. Donc une projection
ALL généreuse sur une table fréquemment mise à jour multiplie à la fois le stockage et
la capacité d'écriture. La discipline est : projette ce que la requête lit, pas « tout,
au cas où ».
Une subtilité à connaître : avec un index sparse, la projection ne contient toujours
que les items qui portent la clé d'index — donc INCLUDE/ALL sur un
index sparse reste petit parce que l'index lui-même est
petit. Pèse le multiplicateur de stockage et d'écriture pour ta projection avec le
calculateur de tarification DynamoDB, et assemble
les requêtes d'index elles-mêmes avec le
DynamoDB expression builder.
Voir une projection dans DynoTable
DynoTable liste chacun des index secondaires d'une table et te permet d'interroger directement à travers l'un d'eux. Lance le même motif d'accès contre la table de base et contre un GSI puis compare les résultats — les attributs absents du résultat de l'index sont exactement ceux qu'il ne projette pas, donc l'effet d'une projection est visible sans relire la définition de la table.


Pièges et étapes suivantes
- Un attribut non projeté sur un GSI signifie une récupération sur la table de base — conçois la projection autour de ce que la requête rend.
ALLest rarement gratuit — il duplique le stockage et le coût d'écriture ; mets le défaut surINCLUDEà moins que l'index ait véritablement besoin de chaque champ.- Les projections sont essentiellement figées. Tu ne peux pas modifier librement la projection d'un GSI plus tard sans recréer l'index — choisis délibérément dès le départ.
- Connexe : GSI vs LSI et les index sparse déterminent combien une projection stocke réellement.
Tu veux voir ce que chacun de tes index renvoie réellement avant de les reconcevoir ? Télécharge DynoTable et interroge tes tables directement.