Le key overloading dans DynamoDB
En venant de SQL, une colonne signifie une seule chose pour toujours :
orders.created_at est toujours une date, users.email est toujours un email. Le
key overloading balaie ça. Tu donnes à la clé de partition et à la clé de tri des
noms génériques — pk, sk — et tu laisses chaque type d'item y verser un sens
différent. Une table, plusieurs entités, une seule forme.
Qu'est-ce que le key overloading dans DynamoDB ?
Le key overloading consiste à stocker plusieurs types d'entités dans une seule table sous des noms de clés génériques comme pk/sk, en encodant le type dans la valeur (USER#u_3001, INVOICE#2026-0014). Le nom de l'attribut reste neutre pour que les utilisateurs, les factures et les événements partagent une même partition ; la valeur porte le type, et un préfixe de clé de tri permet à un seul Query de découper chaque entité via begins_with.
- Noms de clés génériques, valeurs typées. Nomme tes clés
pk/sket mets le type d'entité dans la valeur :pk = "TENANT#acme",sk = "USER#u_3001". Le nom est bête ; la valeur porte le type. - C'est ce qui fait fonctionner le single-table design. Sans overloading, une
table partagée n'est qu'un tiroir fourre-tout. Avec, chaque entité se trouve dans une
partition que tu peux
Query. begins_withest la récompense. Un préfixe de type sur la clé de tri permet à un seulQueryd'extraire une entité entière, ou une de ses tranches, sansScanni filtre.- Le coût : la lisibilité. Un dump brut de
pk/skne te dit rien. Tu as besoin d'un viewer qui décode les préfixes, sinon tu plisseras les yeux sur des chaînes.
Pourquoi les noms génériques battent les vrais
DynamoDB a exactement deux attributs de clé par table, et un Query ne peut viser
qu'une seule clé de partition. Donc si tu nommes ta clé userId, seuls les items
utilisateur peuvent vivre proprement dans cette table — tout le reste doit feindre un
userId ou déménager dans sa propre table.
L'overloading contourne ça. Un nom neutre comme pk ne s'engage sur aucune entité,
donc un utilisateur, une facture et un événement d'audit peuvent tous partager le même
attribut de clé et la même table. La valeur, pas le nom de l'attribut, dit ce
qu'est l'item.
C'est le geste qui transforme le single-table design de la théorie en quelque chose que tu peux réellement requêter. La table partagée est le conteneur ; l'overloading est ce qui permet à des entités distinctes d'y coexister.
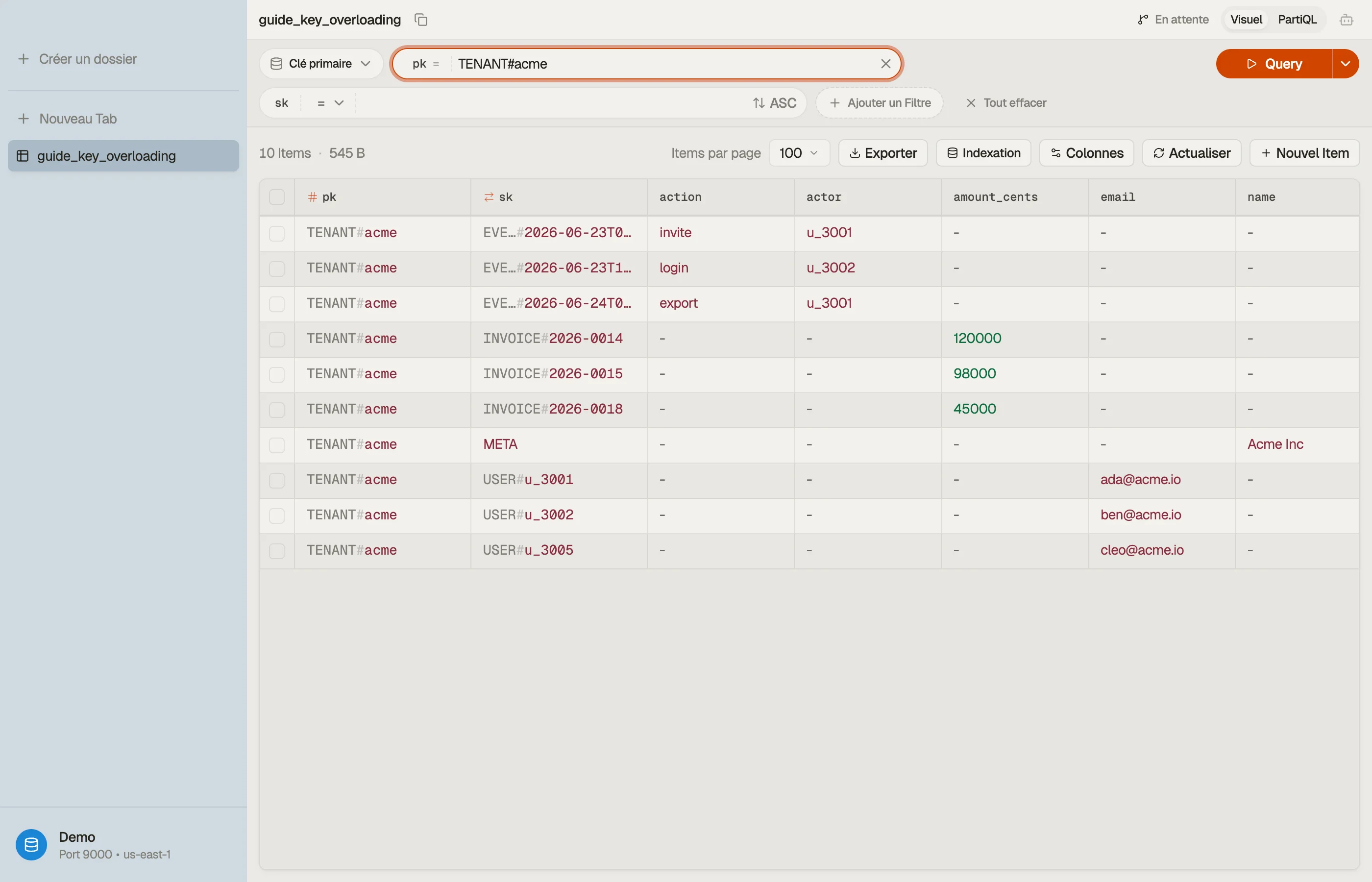
Un exemple multi-tenant
Disons que tu gères un produit de facturation SaaS. Chaque tenant a des membres, des factures et une piste d'audit. Au lieu de trois tables, mets tout dans une seule et surcharge les clés :
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
Chaque ligne partage pk = "TENANT#acme", donc elles forment une seule collection
d'items — toutes colocalisées, toutes atteignables en une seule lecture de partition.
Le préfixe de clé de tri fait le vrai travail. Il groupe les entités et les ordonne.
Requêter la collection surchargée
Parce que le type vit dans le préfixe de clé de tri, begins_with tranche la partition
par entité sans rien scanner :
Query pk = "TENANT#acme" -- tout le tenant, chaque type
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- juste les membres
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- juste les facturesTu paies seulement pour les items que la condition matche, pas toute la partition — le
contraire d'un Scan filtré, où tu paies pour lire des lignes
que tu jettes ensuite. AWS appelle ça une condition de clé ; elle s'exécute sur les
clés avant qu'aucune donnée ne quitte la partition.
Si tu construis cette condition begins_with à la main, mets bien les tags de type —
un USERS# égaré au lieu de USER# ne renvoie rien, silencieusement. L'
expression builder génère le
KeyConditionExpression et la map ExpressionAttributeValues pour que les préfixes
correspondent à ce que tu as réellement écrit.
Surcharge aussi l'index
La même astuce s'applique à un GSI. Donne-lui des noms de clés génériques — gsi1pk,
gsi1sk — et laisse chaque entité écrire ce dont elle a besoin. Un index répond alors
à des modes que la table de base ne peut pas.
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
Maintenant Query gsi1 WHERE gsi1pk = "STATUS#open" liste chaque facture ouverte à
travers tous les tenants, triée par date d'échéance — une vue inter-partitions que
les clés de la table de base, cantonnées au tenant, ne pourraient jamais servir. Une
entité différente peut réutiliser gsi1 avec sa propre signification (disons
gsi1pk = "ROLE#admin"), donc un seul index couvre plusieurs lectures. Souviens-toi
juste qu'un GSI est à cohérence à terme — ses écritures
retardent sur la table de base.
Fais-le dans DynoTable
Les clés surchargées brutes sont hostiles à la lecture : INVOICE#2026-0015 et
EVENT#2026-06-23T09:12Z se confondent dans une liste plate. Un viewer qui groupe par
partition et fait remonter les préfixes retransforme le tiroir fourre-tout en entités.


Pièges
- Choisis les délimiteurs une fois et ne les change jamais.
#est la convention. Mélanger#et:entre les entités cassebegins_withde manières dont rien ne te prévient. - Ne surcharge pas des valeurs qui nécessitent des maths de plage. Une clé de tri
INVOICE#2026-0015trie lexicalement, pas numériquement — zero-pad les ids et utilise des dates ISO-8601 pour que l'ordre des chaînes corresponde à l'ordre que tu veux. - Réserve l'espace de noms des préfixes. Deux types d'entités qui commencent tous
les deux par
USER(disonsUSER#etUSERGROUP#) entreront en collision sousbegins_with(sk, "USER"). Rends les préfixes non ambigus dès le premier caractère. - Planifie la lecture avant les clés. L'overloading sert des modes d'accès que tu as énumérés. Si tu ne connais pas encore tes lectures, vois d'abord single-table design — les clés sont en aval des requêtes.
Esquisse une partition, puis télécharge DynoTable pour parcourir tes
propres clés surchargées et observer un seul Query ramener tout un tenant d'un coup.