Les compteurs de références DynamoDB
Un compteur de références est un nombre que tu stockes sur un item parent et qui suit combien d'items enfants pointent vers lui — des likes sur un post, des membres dans un espace de travail, des réponses sur un commentaire. Tu le gardes parce que compter les enfants à chaque lecture est trop coûteux.
Comment maintenir un compteur dans DynamoDB ?
Stocke le total courant comme un nombre sur l'item parent et mets-le à jour dans la même écriture qui crée l'enfant. Un fait que les deux atterrissent ou aucun, et une condition sur l'écriture de l'enfant empêche les réessais de doubler le comptage — ainsi un seul GetItem renvoie un compte exact.
- Ne compte pas les enfants au moment de la lecture. Un
Querypour compter les likes paie pour chaque item de like qu'il parcourt. Stocke le total sur le post et lis un seul item à la place. - Maintiens le compteur là où l'enfant est écrit, pas après. Incrémente-le dans la même opération qui crée l'enfant pour que les deux ne dérivent jamais.
- Utilise une transaction quand l'écriture et l'incrémentation touchent des items
différents. Un like est un item, le compteur vit sur un autre —
TransactWriteItemsfait que les deux atterrissent ou aucun. - Le piège, c'est le double comptage. Un like réessayé ou dupliqué qui rejoue l'incrémentation gonfle le nombre. Protège l'écriture de l'enfant avec une condition.
Pourquoi compter tout court
En venant de SQL, tu ne stockerais jamais un compteur de likes — tu ferais un
SELECT COUNT(*) FROM likes WHERE post_id = ? et tu laisserais un index le rendre
bon marché. DynamoDB n'a pas de COUNT(*) qui évite de lire les items.
Un Query sur les likes d'un post lit — et facture — chaque item de like dans
cette partition, même si tu ne veux que le nombre. Sur un post viral, ce sont des
milliers de RCU pour répondre à « combien de likes ? » C'est le piège de lecture
que les compteurs de références existent pour tuer.
Donc tu dénormalises : tu stockes le total courant sur le post lui-même. Lire
le compteur devient un seul GetItem. Le prix, c'est que tu es maintenant
responsable de le garder exact.
Modéliser les items
Deux types d'item partagent une partition pour que le post et ses likes vivent dans une même collection d'items. Clés inventées :
| PK | SK | attributes |
|---|---|---|
| POST#a91f | META | likeTally (Number), body, authorId, createdAt |
| PK | SK | attributes |
|---|---|---|
| POST#a91f | LIKE#USER#7c20 | likedAt |
L'attribut likeTally sur l'item META est le compteur de références. Chaque item
LIKE# est un enfant. Placer les deux sous PK = "POST#a91f" signifie qu'un seul
Query peut récupérer le post et ceux qui l'ont liké ensemble quand tu veux bien
la liste.
Incrémenter le compteur de façon atomique
DynamoDB incrémente un nombre avec une update expression ADD (ou
SET x = x + :n) — c'est un compteur atomique : DynamoDB applique le delta
côté serveur sans que tu lises la valeur actuelle d'abord, donc les
incrémentations concurrentes ne s'écrasent pas entre elles.
(AWS : compteurs atomiques)
Le problème : liker un post, ce sont deux écritures vers deux items — créer
l'item LIKE#, et ajouter 1 à likeTally sur META. Si le like atterrit mais
que l'incrémentation échoue, le total est faux à jamais. Il te faut les deux ou
aucun.
C'est ce que TransactWriteItems garantit — tout ou rien à travers plusieurs
items, et il annule toute la transaction si un item est modifié de façon
concurrente
(AWS : verrouillage pessimiste avec les transactions) :
{
"TransactItems": [
{
"Put": {
"TableName": "Social",
"Item": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "LIKE#USER#7c20"},
"likedAt": {"N": "1750636800"}
},
"ConditionExpression": "attribute_not_exists(SK)"
}
},
{
"Update": {
"TableName": "Social",
"Key": {
"PK": {"S": "POST#a91f"},
"SK": {"S": "META"}
},
"UpdateExpression": "ADD likeTally :one",
"ExpressionAttributeValues": {":one": {"N": "1"}}
}
}
]
}Le Put et l'Update sont committés ensemble. Si l'un échoue, DynamoDB annule les
deux et renvoie une TransactionCanceledException.
Se prémunir du double comptage
Le vrai bug n'est pas un like à moitié écrit — la transaction empêche ça. C'est le
même utilisateur qui like deux fois, ou un retry client qui rejoue la requête.
Chaque rejeu ajoute un autre 1, et likeTally dérive silencieusement au-dessus
du vrai compte.
La ConditionExpression: attribute_not_exists(SK) sur le Put est le garde-fou.
Si l'item LIKE# de cet utilisateur existe déjà, la condition du Put échoue,
toute la transaction est annulée et — c'est crucial — l'ADD ne s'exécute jamais.
Un like par utilisateur, imposé par la clé.
Construis et copie ces update et condition expressions — avec les bons
ExpressionAttributeValues et le garde attribute_not_exists — dans le
constructeur d'expressions DynamoDB plutôt
que d'assembler le JSON à la main.
Le unlike, et le coût
Retirer un like est l'image miroir : Delete l'item LIKE# avec
ConditionExpression: attribute_exists(SK), et ADD likeTally :minusOne dans la
même transaction. La condition empêche un double-unlike de faire passer le total
sous zéro.
Connais le prix. Une écriture transactionnelle coûte 2 WCU par item pour des items jusqu'à 1 Ko — une pour préparer, une pour committer — contre 1 WCU pour une écriture simple. Un like, ce sont deux items, donc chaque like fait à peu près quatre WCU. Pas cher par action, mais bon à savoir avant qu'un post de célébrité ne déclenche une tempête de likes.
Voir ça dans DynoTable
Quand tu soupçonnes qu'un total a dérivé, tu veux comparer le likeTally stocké au
nombre réel d'enfants LIKE# — sans lancer de requête de comptage en prod.

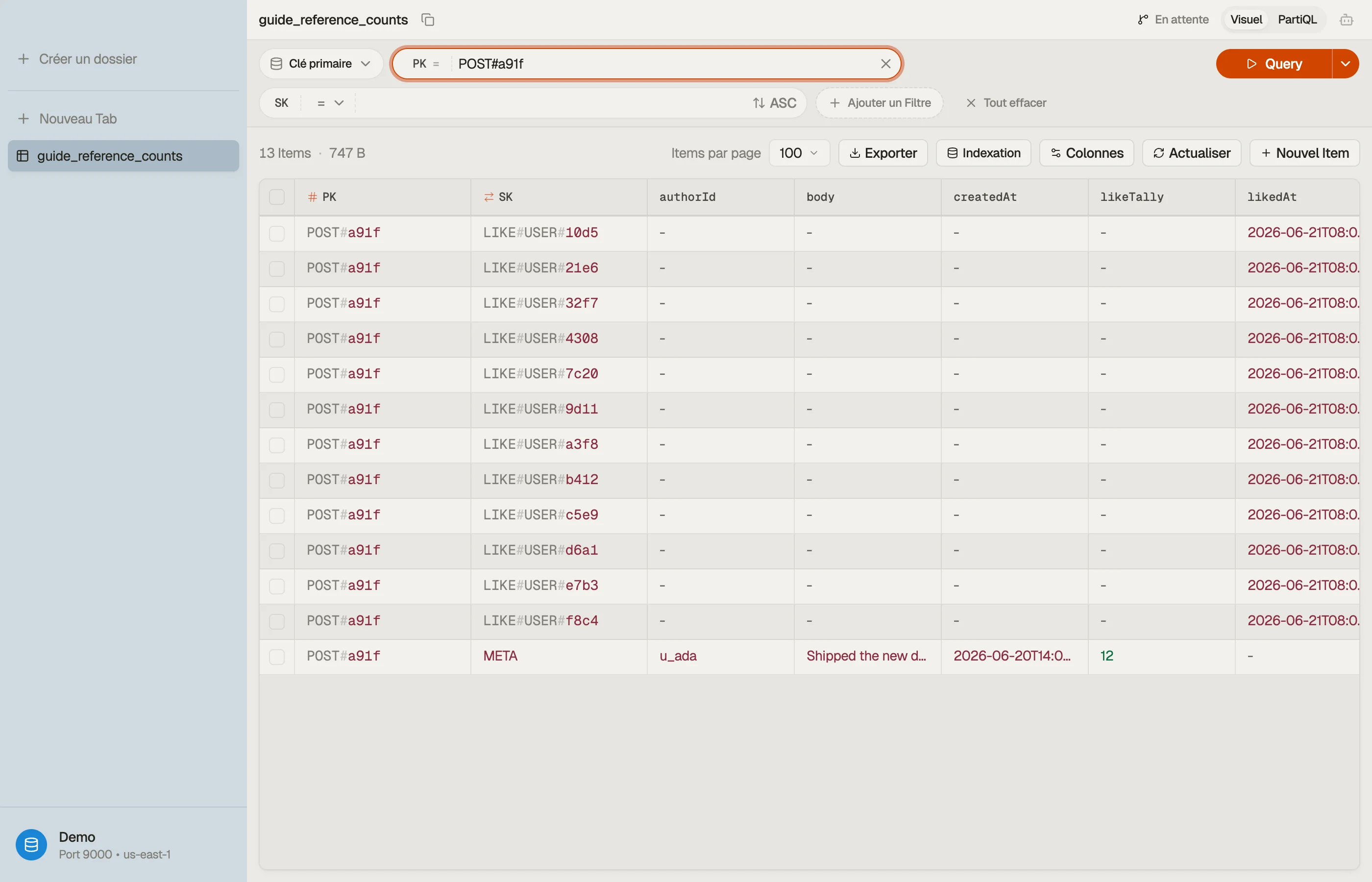

Pour une vraie réconciliation sur un ensemble borné de posts — « quels totaux ne
correspondent pas à leurs comptes d'enfants ? » — le SQL Workbench de DynoTable
exécute le GROUP BY et la jointure côté client sur les enregistrements que tu as
chargés, ce que PartiQL seul ne peut pas exprimer.
Pièges et étapes suivantes
- Ne maintiens pas le compteur hors-bande (un Lambda qui recompte chaque nuit). C'est un pansement sur un chemin d'écriture qui aurait dû être transactionnel dès le départ.
- Surveille les partitions chaudes. Un seul post follement populaire concentre chaque like — et chaque incrémentation de total — sur une seule clé de partition. Le compte est correct ; la partition peut quand même throttler.
- Réconcilie rarement, répare chirurgicalement. La dérive devrait être proche de zéro si chaque mutation est conditionnée. Traite un écart comme un bug à trouver, pas un nombre à écraser.
Lectures liées : single-table design pour comprendre pourquoi le post et les likes partagent une partition, et Query vs Scan pour comprendre pourquoi compter les enfants au moment de la lecture est le pattern que tu évites.
Ensuite, télécharge DynoTable pour inspecter ces collections d'items et vérifier tes totaux contre tes propres tables.