Les relations plusieurs-à-plusieurs dans DynamoDB
Un étudiant s'inscrit à plusieurs cours ; un cours accueille plusieurs étudiants.
En SQL tu sors la table de jointure et un JOIN à quatre voies.
DynamoDB n'a pas de jointures, donc la relation doit vivre dans les clés — et
l'astuce est de stocker chaque arête d'inscription dans une forme que les deux
côtés peuvent Query directement.
Ce guide parcourt le problème étudiants ↔ cours de bout en bout : les motifs d'accès, le motif de liste d'adjacence qui les résout, un schéma de clés original que tu peux copier, et comment relire les deux directions sans jamais scanner la table.
Comment modéliser une relation plusieurs-à-plusieurs dans DynamoDB ?
DynamoDB n'a pas de jointures, donc tu modélises une relation plusieurs-à-plusieurs avec le motif de liste d'adjacence : stocke chaque lien comme son propre item d'arête clé sur un côté, puis ajoute un GSI inversé qui échange les clés. Une seule arête, écrite une fois, répond alors aux requêtes des deux directions à bas coût.
- Stocke chaque inscription comme son propre item d'arête, pas comme un attribut liste sur l'un ou l'autre côté.
- Clé l'arête par l'étudiant (
PK = STU#…,SK = ENROLL#CRS#…) pour qu'un seulQueryrenvoie toute la liste de cours d'un étudiant. - Ajoute un GSI inversé qui échange les rôles (
GSI1PK = CRS#…) pour que la même arête réponde aussi à « qui est dans ce cours ? ». - Une arête, écrite une fois, lue à bas coût dans les deux sens — c'est tout le jeu.
Cadre d'abord les motifs d'accès
La modélisation DynamoDB part des motifs d'accès : tu décides les lectures avant de choisir le moindre nom d'attribut. Une relation plusieurs-à-plusieurs a presque toujours deux lectures symétriques plus les recherches d'entités :
- Récupérer le profil d'un étudiant, et lister chaque cours auquel cet étudiant est inscrit.
- Récupérer les métadonnées d'un cours, et lister chaque étudiant inscrit à ce cours.
- Rechercher une seule arête d'inscription — pour mettre à jour une note ou abandonner le cours.
Le hic : les deux lectures de liste pointent dans des directions opposées à travers
le même ensemble d'arêtes. Une conception naïve en sert une à bas coût et force un
Scan pour l'autre — l'arme à fragmentation exacte couverte dans
Query vs Scan.
Le travail consiste à faire des deux directions un seul Query.
Utilise le motif de liste d'adjacence
Le conseil officiel de DynamoDB pour les relations est la liste d'adjacence : modélise chaque relation comme un item dont la clé de partition est une extrémité et dont la clé de tri est l'autre.
AWS documente ceci sur la page Best Practices for Managing Many-to-Many Relationships du DynamoDB Developer Guide.
Pourquoi des clés et pas une seconde table ? Parce que la primitive que DynamoDB te
donne est un Query contre une seule partition.
Un Query lit une plage contiguë de valeurs de clé de tri sous une clé de partition
en une seule opération facturée — c'est la seule « jointure » que le moteur offre.
Pour obtenir une relation qui se lit à bas coût des deux côtés, tu dupliques l'arête : écris-la une fois clée par l'étudiant, puis utilise un index secondaire pour projeter la même arête clée par le cours.
C'est la pensée des clés surchargées de Single-Table Design, appliquée à une relation au lieu d'une hiérarchie parent-enfant.
La forme est deux vues empilées de la même arête — la table de base clée par étudiant, le GSI inversé clé par cours :
Chaque arête est écrite une fois sur la table de base et projetée dans le GSI avec
ses clés échangées, de sorte qu'un Query contre l'une ou l'autre partition lit la
relation à bas coût.
La lignée remonte au papier Amazon Dynamo de 2007 : la clé de partition est l'unité de distribution, et l'accès par clé unique est le chemin rapide.
Les relations dans DynamoDB sont un exercice consistant à plier les lectures plusieurs-à-plusieurs dans ce chemin rapide.
Travaille l'exemple : étudiants ↔ cours
Utilise une table avec des clés génériques, PK et SK, et encode le type
d'entité dans la valeur. L'arête d'inscription en est le cœur :
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Un seul Query PK = "STU#a91" renvoie le profil de l'étudiant et chaque
inscription en une seule lecture. Restreins-le avec SK begins_with "ENROLL#" pour
n'obtenir que les arêtes de cours. Ça résout « lister les cours d'un étudiant ».
Mais « lister les étudiants d'un cours » pointe dans l'autre sens — et la table de base ne peut pas y répondre, parce que l'id de l'étudiant est dans la clé de partition, pas dans la clé de tri.
Ajoute un global secondary index inversé qui échange les rôles. Donne aux items
d'arête une paire générique GSI1PK/GSI1SK tenant le cours côté partition et
l'étudiant côté tri :
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Maintenant Query GSI1 WHERE GSI1PK = "CRS#math204" liste chaque étudiant de ce
cours — la lecture que la table de base ne pouvait pas servir. Un seul item d'arête,
écrit une fois, répond aux deux directions.
Ce doit être un GSI, pas un LSI : la partition du cours est entièrement différente de la partition de l'étudiant, et un LSI partage la clé de partition de la table de base.
L'index couvre plusieurs partitions, donc il doit être global — vois GSI vs LSI.
Un piège : les GSI dans DynamoDB sont peuplés de façon asynchrone. Une inscription
toute neuve peut prendre un instant à apparaître dans la direction CRS#….
Traite la lecture du registre du cours comme à cohérence à terme — ce que le Developer Guide signale explicitement pour les global secondary indexes.
Écris-le et lis-le dans DynoTable
Écrire l'inscription signifie définir quatre attributs de clé plus les propres
données de l'arête. La condition qui empêche un étudiant de s'inscrire deux fois au
même cours est un garde attribute_not_exists(PK) sur la clé composite.
C'est exactement le genre de condition que tu peux assembler visuellement avec le
DynamoDB Expression Builder au lieu d'écrire à
la main les ExpressionAttributeNames et les valeurs de placeholders.
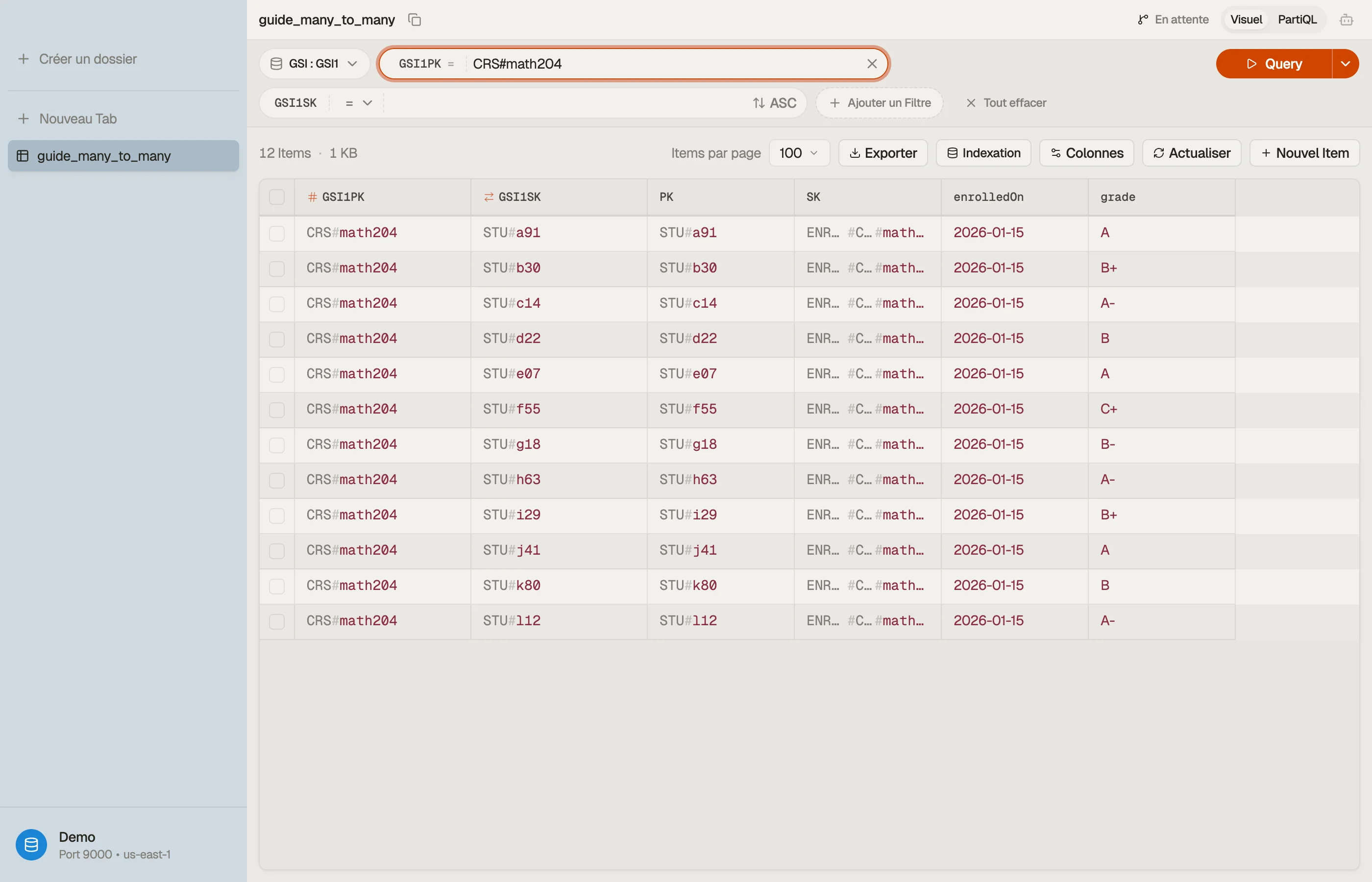
Dans DynoTable tu pointes un Query sur GSI1, tu poses GSI1PK = "CRS#math204",
et le registre revient sous forme de table que tu peux lire, trier et éditer sur
place — les deux directions de la relation parcourables depuis un seul schéma.


Pièges et étapes suivantes
- Ne stocke pas un côté comme attribut liste. Un tableau
courseIdssur l'item étudiant semble propre jusqu'à ce qu'un cours ait besoin de son registre, que le tableau atteigne le plafond d'item de 400 Ko, ou que deux inscriptions se courent après et s'écrasent. Des items d'arête distincts montent en charge et se mettent à jour indépendamment. - Garde les données d'arête sur l'arête. La
gradeet leenrolledOnde l'inscription appartiennent à l'item d'arête, pas dupliqués sur l'étudiant ou le cours — il y a exactement une ligne par paire (étudiant, cours) à mettre à jour. - Attention à la propagation du GSI. La direction de l'index inversé est à cohérence à terme, donc une lecture immédiatement après une inscription peut être en retard d'une fraction de seconde.
- Ne projette que ce dont le registre a besoin. Une projection
KEYS_ONLYou étroite garde le GSI petit quand la vue registre n'a besoin que d'ids.
Pour aller plus loin sur les motifs environnants, lis Single-Table Design pour les clés surchargées et GSI vs LSI pour savoir quand l'index inversé doit être global.
Puis télécharge DynoTable pour modéliser pour de vrai le schéma étudiants ↔ cours — écris les arêtes, construis la condition avec l'Expression Builder, et interroge les deux directions de la relation sans le moindre scan.