La limite de taille d'item DynamoDB (400 Ko)
Un seul item DynamoDB peut contenir au maximum 400 Ko de données. En venant de
MongoDB (documents de 16 Mo) ou d'une ligne relationnelle sans plafond pratique, ce
plafond paraît bas — et on tend à le découvrir à la dure, quand une écriture qui
fonctionnait depuis des mois échoue soudain avec une ValidationException parce qu'un
item a fini par devenir trop gros.
La limite n'est pas arbitraire, et ce n'est pas un quota que tu peux relever. C'est une contrainte de modélisation, et les items qui l'atteignent te disent généralement que les données étaient mal modélisées.
Quelle est la taille maximale d'un item dans DynamoDB ?
DynamoDB plafonne un seul item à 400 Ko — une limite stricte que tu ne peux pas relever. La taille additionne les noms d'attributs et les valeurs ensemble, y compris chaque élément de liste, de map et de set imbriqué. Les items l'atteignent généralement par une croissance non bornée, comme une liste imbriquée qui ne cesse de grandir ; le correctif est de la modélisation — découper la collection en items distincts —, pas de la compression.
- 400 Ko par item, plafond strict. Non ajustable, pas un quota souple.
- Taille = noms d'attributs + valeurs, ensemble. Les noms d'attributs longs comptent, sur chaque item.
- L'imbrication et les sets comptent aussi. Les listes, les maps et leurs valeurs imbriquées s'additionnent toutes.
- La cause habituelle est une croissance non bornée — l'imbrication d'une liste qui grandit sans limite sur un item parent.
- Le correctif est de la modélisation, pas de la compression. Découpe la collection qui grandit en ses propres items sous une clé de partition partagée.
Le problème : l'item qui grandit pour toujours
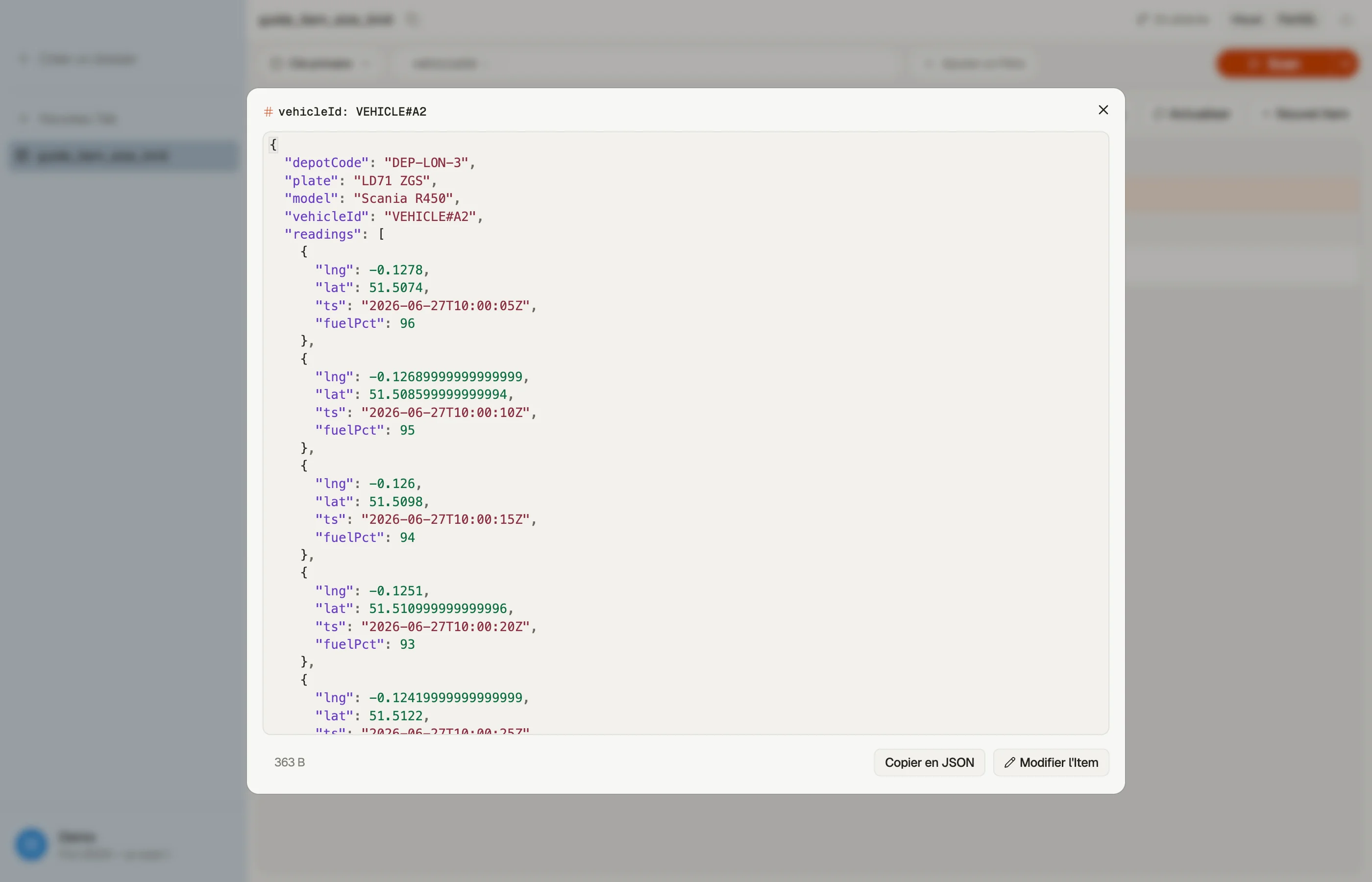
Disons que tu suis une flotte de véhicules, et que tu décides de stocker les relevés de télémétrie de chaque véhicule sous forme de liste sur l'item véhicule :
PK: VEHICLE#A1 readings: [ {ts, lat, lng, fuel}, {ts, lat, lng, fuel}, ... ]Pendant un jour ou deux, tout va bien. Mais les relevés arrivent toutes les quelques secondes et ne s'arrêtent jamais, donc la liste grandit sans borne. Finalement un seul item véhicule franchit les 400 Ko et chaque écriture vers lui échoue — tu ne peux plus enregistrer de télémétrie pour ce véhicule du tout, parce que chaque mise à jour réécrit l'item entier (désormais surdimensionné).
Le bug n'est pas la limite de taille. C'est de modéliser une relation un-à-plusieurs non bornée comme une liste imbriquée. Ça ne marche que quand le côté « plusieurs » est borné et petit.
Ce qui compte réellement dans les 400 Ko
DynamoDB mesure la taille totale de l'item comme la somme de :
- Chaque nom d'attribut, encodé en UTF-8. Un nom de 20 caractères répété sur des millions d'items est à la fois de la taille et du stockage que tu paies — c'est pourquoi les modélisateurs expérimentés gardent les noms d'attributs courts.
- Chaque valeur d'attribut. Les chaînes et le binaire par leur longueur en octets ; les nombres par un encodage compact ; les booléens et les nulls par un coût fixe minime.
- La structure imbriquée. Une liste ou une map compte sa propre surcharge plus la taille de chaque élément et clé à l'intérieur, jusqu'au plus profond.
Il n'y a pas de plafond séparé par attribut autour duquel planifier — c'est l'item entier contre la ligne des 400 Ko. Les quotas de service AWS détaillent la comptabilité exacte des octets.
Pourquoi la limite existe
Les gros items sont coûteux à déplacer. Les lectures DynamoDB sont mesurées en unités de 4 Ko, donc un item de 400 Ko coûte 100 RCU à lire fortement — et les lectures, les écritures et la réplication deviennent toutes plus lentes et plus chères à mesure que les items grossissent. Le plafond te pousse vers des items petits et ciblés, et loin de l'anti-motif « récupérer un seul gros blob » que les débutants en NoSQL adoptent par habitude relationnelle.
Modéliser autour
Pour l'exemple de la flotte, arrête d'imbriquer. Donne à chaque relevé son propre item dans la même partition que le véhicule, ordonné par horodatage sur la clé de tri :
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:05Z lat, lng, fuel
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:10Z lat, lng, fuelMaintenant aucun item ne grandit, les écritures ne dépassent jamais le plafond, et un
seul Query sur VEHICLE#A1 ramène toujours les relevés d'un véhicule sous forme d'une
collection d'items triée. Les sous-listes bornées
(une poignée de tags, un bloc de config fixe) peuvent rester imbriquées ; les non
bornées deviennent des items.
Vérifier la taille d'item dans DynoTable
Avant de t'engager sur une forme, pèse un item représentatif. Dans DynoTable, ouvre un item dans la Quick View et tu vois sa taille en octets à côté de ses attributs — pour que tu repères une forme trop lourde en parcourant des données réelles, au moment de la conception plutôt qu'à l'écriture échouée.
Tu préfères rester dans le navigateur ? Le calculateur de taille d'item DynamoDB fait la même chose à partir d'un échantillon collé, en rapportant les Ko exacts et la RCU/WCU que chaque lecture et écriture coûtera.


Pièges et étapes suivantes
- Surveille les listes imbriquées qui grandissent avec le trafic — ce sont la bombe à retardement classique des 400 Ko. Borne-les ou découpe-les.
- Raccourcis les noms d'attributs sur les items à forte cardinalité — c'est de la taille et du stockage récupérés gratuitement.
- Les grosses valeurs appartiennent à S3. Stocke les gros blobs (images, documents) dans S3 et ne garde que la clé sur l'item.
- Connexe : la dénormalisation et les relations un-à-plusieurs couvrent quand imbriquer vs découper.
Envie de voir les vraies tailles d'item à travers une table d'un coup d'œil ? Télécharge DynoTable et inspecte tes données directement.