Le pattern de liste d'adjacence DynamoDB
Un graphe n'est que des nœuds et des arêtes, et le pattern de liste d'adjacence
stocke les deux comme de simples items dans une seule table. Chaque arête devient une
ligne dont la clé de partition est le nœud source et la clé de tri la cible. Requêter
une partition liste chaque voisin — le substitut DynamoDB d'un JOIN sur une table de
jointure.
Qu'est-ce que le pattern de liste d'adjacence DynamoDB ?
Le pattern de liste d'adjacence modélise un graphe comme des items d'arêtes dans une seule table : chaque relation (A suit B) est une ligne clée par la source sur la clé de partition et la cible sur la clé de tri. Requêter une partition liste chaque voisin, et un GSI inversé inverse la relation — pas de jointures, pas de scans, les deux directions en une seule requête.
- Les arêtes sont des items. Modélise chaque relation (l'utilisateur A suit l'utilisateur B) comme son propre item clé par la source sur la clé de partition, la cible sur la clé de tri.
- Une direction est gratuite ; l'autre nécessite un GSI. La table de base répond à « qui A suit-il ? ». Un index inversé répond à « qui suit A ? ».
- Pas de jointures, pas de scans. Les deux directions sont un seul
Querycontre une partition connue — jamais unScande table entière. - C'est la primitive plusieurs-à-plusieurs. Follows, adhésions, likes, amitiés — tout graphe où une entité se connecte à plusieurs autres correspond à cette forme.
Cadre-le en modes d'accès
En venant de SQL, un graphe de follows est une table de jointure : follows(follower_id, followee_id). Pour lister les followers de quelqu'un tu indexes une colonne ; pour
lister qui il suit tu indexes l'autre. DynamoDB n'a pas de jointures, donc tu conçois
les clés pour servir chaque lecture directement.
Écris d'abord les lectures. Pour un graphe de follows social :
- Qui l'utilisateur A suit-il ? (sa liste de following)
- Qui suit l'utilisateur A ? (sa liste de followers)
- A suit-il B ? (un simple point lookup)
Les clés n'existent que pour répondre à cette liste. Mets-les correctement et chaque
lecture est un seul Query ou GetItem.
Modéliser les arêtes en items
Utilise des noms de clés génériques pour que la table puisse contenir plus d'un type d'entité, et encode le type de nœud dans la valeur. Une arête de follow ressemble à ça :
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice est la source de l'arête ; SK = TARGET#bob est qui elle suit. Un
seul Query PK = "ACTOR#alice" renvoie chaque compte qu'Alice suit en une seule
lecture facturée — toute sa liste de following, sans jointures.
Chaque arête est écrite une fois, dans la direction « qui je suis ». La direction inverse (« qui me suit ») est la partie que la table de base ne peut pas répondre — encore.
Traverser l'autre direction avec un GSI
La table de base est clée source-d'abord, donc elle ne peut pas répondre à « qui suit Bob ? » sans scanner. Ajoute un global secondary index qui inverse les clés : projette la cible sur la clé de partition de l'index et la source sur la clé de tri de l'index.
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
Maintenant Query GSI1 WHERE GSI1PK = "TARGET#bob" liste tous ceux qui suivent Bob —
alice et dave — en une seule lecture. Le même item d'arête sert les deux directions :
la table de base est following, l'index est followers. Tu écris chaque arête une
fois et tu obtiens les deux requêtes gratuitement.
C'est exactement le pattern qu'AWS documente dans son guide de bonnes pratiques DynamoDB pour modéliser les relations plusieurs-à-plusieurs et les données de graphe — stocke les arêtes en items, puis utilise un GSI pour inverser la relation.
Vérifier une seule arête à bas coût
« Alice suit-elle Bob ? » n'a besoin d'aucune des deux listes. Parce que l'arête est
clée PK = ACTOR#alice, SK = TARGET#bob, c'est un GetItem direct — la lecture la
moins chère que DynamoDB propose, pas de Query, pas d'index.
Pour écrire le follow de façon idempotente et éviter le double comptage, garde le
PutItem avec une condition que l'arête n'existe pas déjà :
attribute_not_exists(PK)Tu peux assembler cette condition — et les valeurs de clé marshalled — avec le
DynamoDB expression builder au lieu d'écrire à la
main la ConditionExpression et les ExpressionAttributeValues.
Fais-le dans DynoTable
Quand tu parcours la table, les arêtes d'un acteur s'empilent sous une seule clé de partition comme une seule collection d'items, et basculer vers la vue GSI affiche la liste de followers inversée — les deux moitiés de la relation côte à côte.

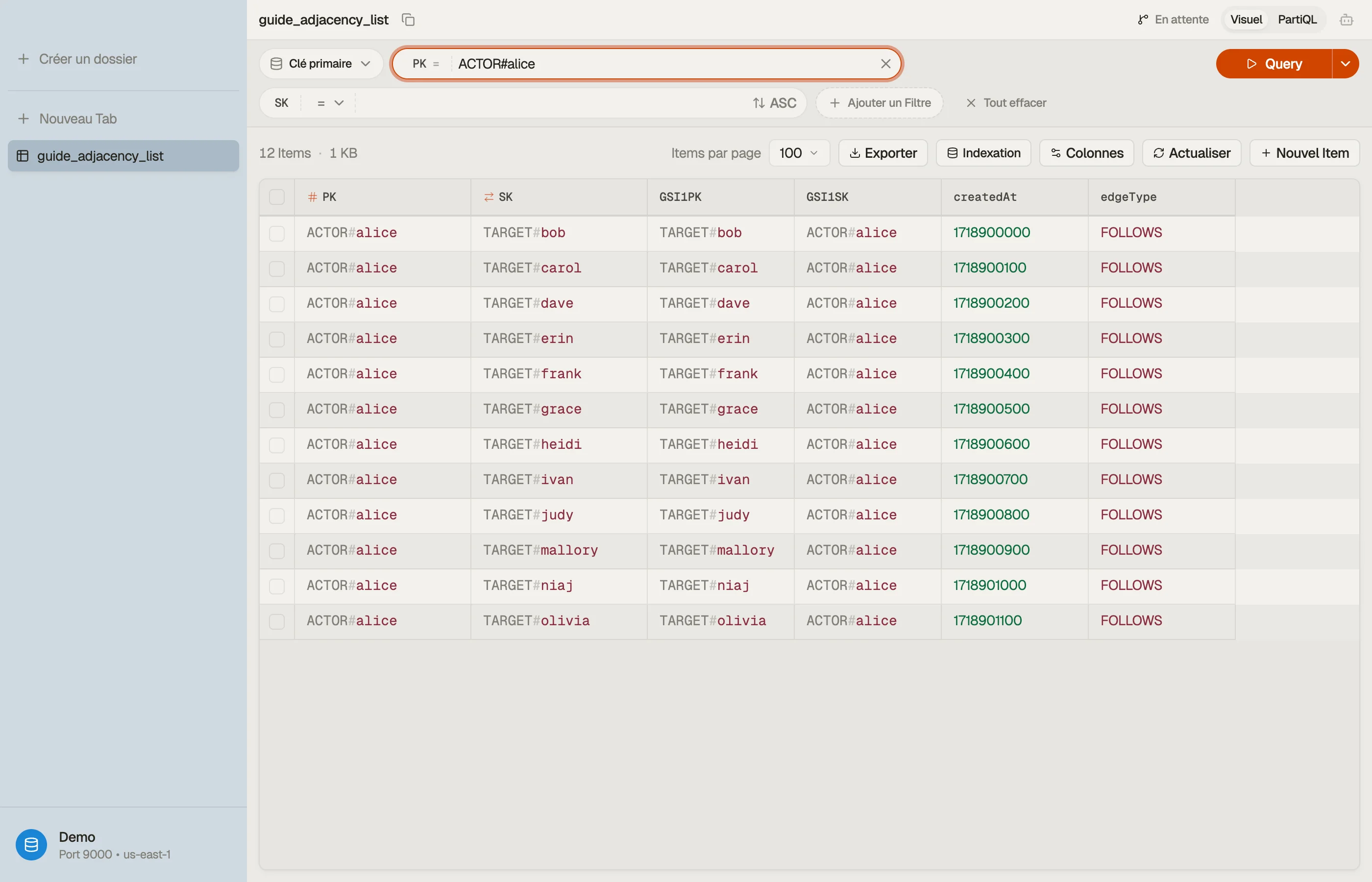

Pièges
La partition célèbre. Un utilisateur avec des millions de followers concentre
chaque arête de follower sous une seule partition GSI1PK = TARGET#<star>. Les
lectures de cette collection sont paginées et peuvent devenir chaudes. Pour les
graphes à fan-out lourd, sharde la clé chaude (p. ex. TARGET#bob#0..N) ou dénormalise
les compteurs pour ne pas relire toute la liste.
Stocker des compteurs sur l'arête. Un compteur de followers n'est pas une arête — ne le dérive pas en lisant et comptant toute la partition à chaque vue de profil. Maintiens un attribut compteur sur l'item utilisateur et mets-le à jour de façon transactionnelle avec l'arête.
Oublier que l'écriture inverse n'est pas nécessaire ici. Une variante classique de liste d'adjacence écrit l'arête deux fois avec les ids inversés. Avec un GSI à clé inversée tu l'écris une fois et tu laisses l'index matérialiser l'inverse — moins d'écritures, pas de dérive entre les deux copies.
Étapes suivantes
La liste d'adjacence est la brique de relation du
single-table design ; l'index inversant est un
GSI, pas un LSI, parce que la clé de partition change. Et chaque
lecture ici est un Query ou un GetItem sur une clé connue — jamais le
footgun du Scan.
Construis les expressions de condition et de clé avec le DynamoDB expression builder, et télécharge DynoTable pour modéliser un graphe de follows sur ta propre table et observer les deux directions se résoudre en une seule lecture.