Le zero-padding des clés de tri dans DynamoDB
Une clé de tri string DynamoDB trie lexicographiquement — un caractère à la fois,
de gauche à droite — pas numériquement. Donc "10" atterrit avant "2", parce que
"1" vient avant "2". Le zero-padding à largeur fixe est la façon dont tu fais
correspondre l'ordre des chaînes à l'ordre numérique.
Pourquoi « 10 » trie-t-il avant « 2 » dans une clé de tri DynamoDB ?
Parce qu'une clé de tri de type string dans DynamoDB est comparée lexicographiquement par ordre d'octets UTF-8, pas numériquement. L'octet de "1" précède "2", donc "10" atterrit avant "2". Pad chaque nombre à une largeur fixe avec des zéros en tête — "2" devient "0000000002" — et l'ordre des chaînes correspond alors exactement à l'ordre numérique.
- Le piège : les nombres stockés en chaînes trient comme des mots.
"100","11","2"est l'ordre que DynamoDB te donne — pas ce que tu voulais dire. - La solution : pad chaque nombre à une largeur fixe avec des zéros en tête, pour
que
"2"devienne"0000000002". Maintenant l'ordre lexicographique et numérique s'accordent. - Choisis une largeur une fois : dimensionne-la pour la plus grande valeur que tu stockeras jamais, puis ajoute quelques chiffres. Changer la largeur plus tard signifie réécrire chaque clé.
- Décroissant gratuitement : pour trier du haut vers le bas (le cas du
classement), stocke
maxValue - value, aussi zero-paddé — DynamoDB n'a pas de sens de tri par attribut.
Pourquoi les clés de tri string te trahissent
En venant de SQL, un ORDER BY score DESC sur une colonne entière « fonctionne tout
seul » — le moteur sait que la colonne est numérique. DynamoDB n'a pas ce luxe pour une
clé de tri qui n'est pas de type Number.
DynamoDB compare les clés de tri string (S) par ordre des octets UTF-8, selon la
documentation AWS sur les clés de tri.
Des octets, pas une magnitude. "9" (0x39) surclasse "10" parce que son premier
octet bat "1" (0x31). La longueur est sans importance — seul le premier octet qui
diffère décide.
C'est ça le footgun : à l'instant où un nombre vit dans une clé de tri string, chaque
Query qui parcourt la plage renvoie les lignes dans un ordre qui semble brouillé.
Construire une clé de tri de classement
Prends un classement d'arcade saisonnier. Une collection d'items par saison contient chaque run de joueur, et tu veux les meilleurs scores en premier.
Modélise-le avec une clé composite dans une seule collection d'items :
leaderboardId(clé de partition) — p. ex.SEASON#2026-SPRING.rankKey(clé de tri) — le score zero-paddé plus un départage.
Une première tentative naïve stocke le score brut sous forme de chaîne :
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "9" | quickdraw |
| SEASON#2026-SPRING | "10" | ace_pilot |
| SEASON#2026-SPRING | "1500" | nightowl |
| SEASON#2026-SPRING | "240" | bytecrash |
Un Query sur SEASON#2026-SPRING les renvoie dans cet ordre d'octets :
"10", "1500", "240", "9". Le run à 9 points se retrouve bon dernier et le run à
1500 points est enterré au milieu. Inutile pour un classement.
Pad à une largeur fixe
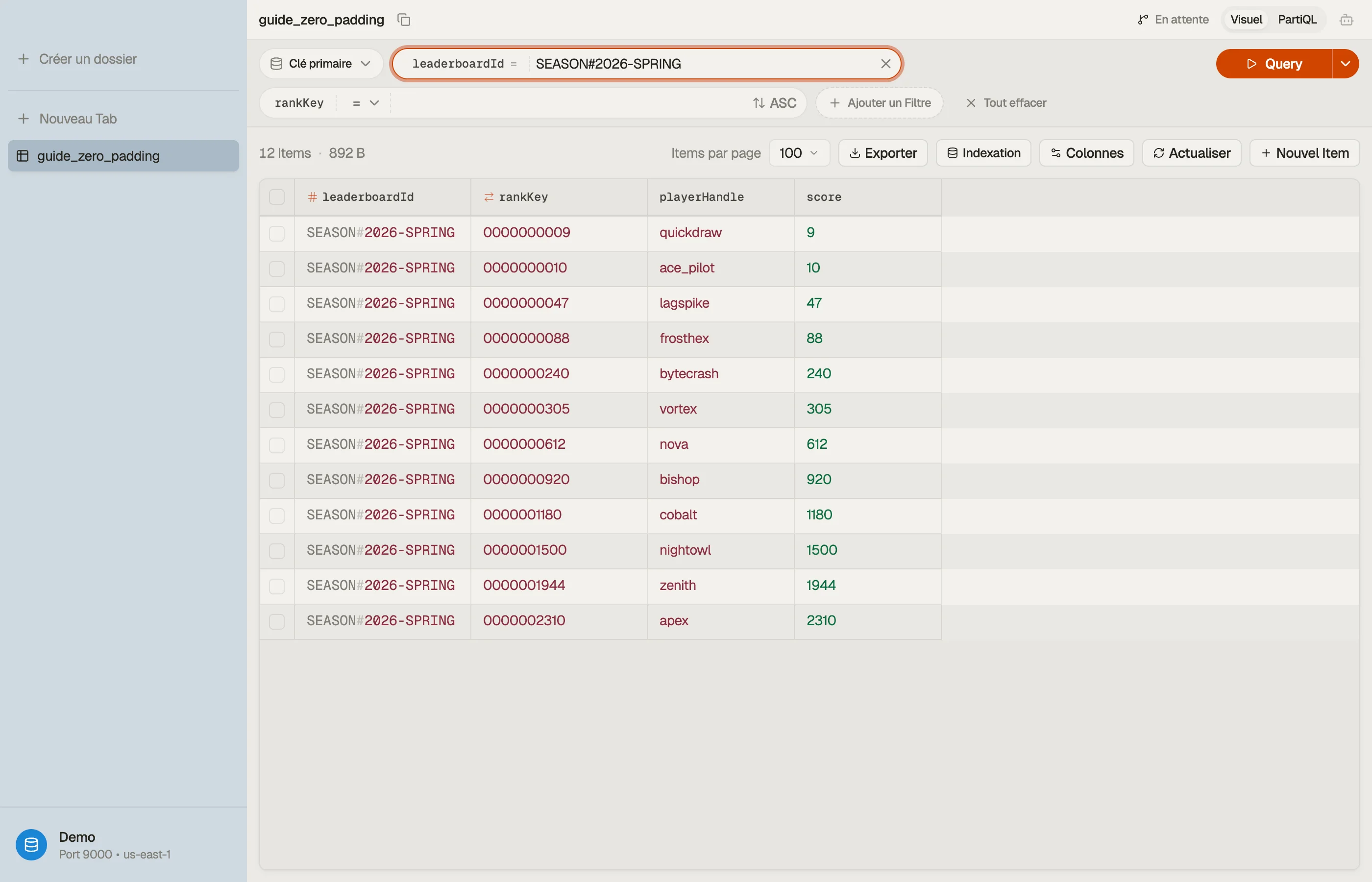
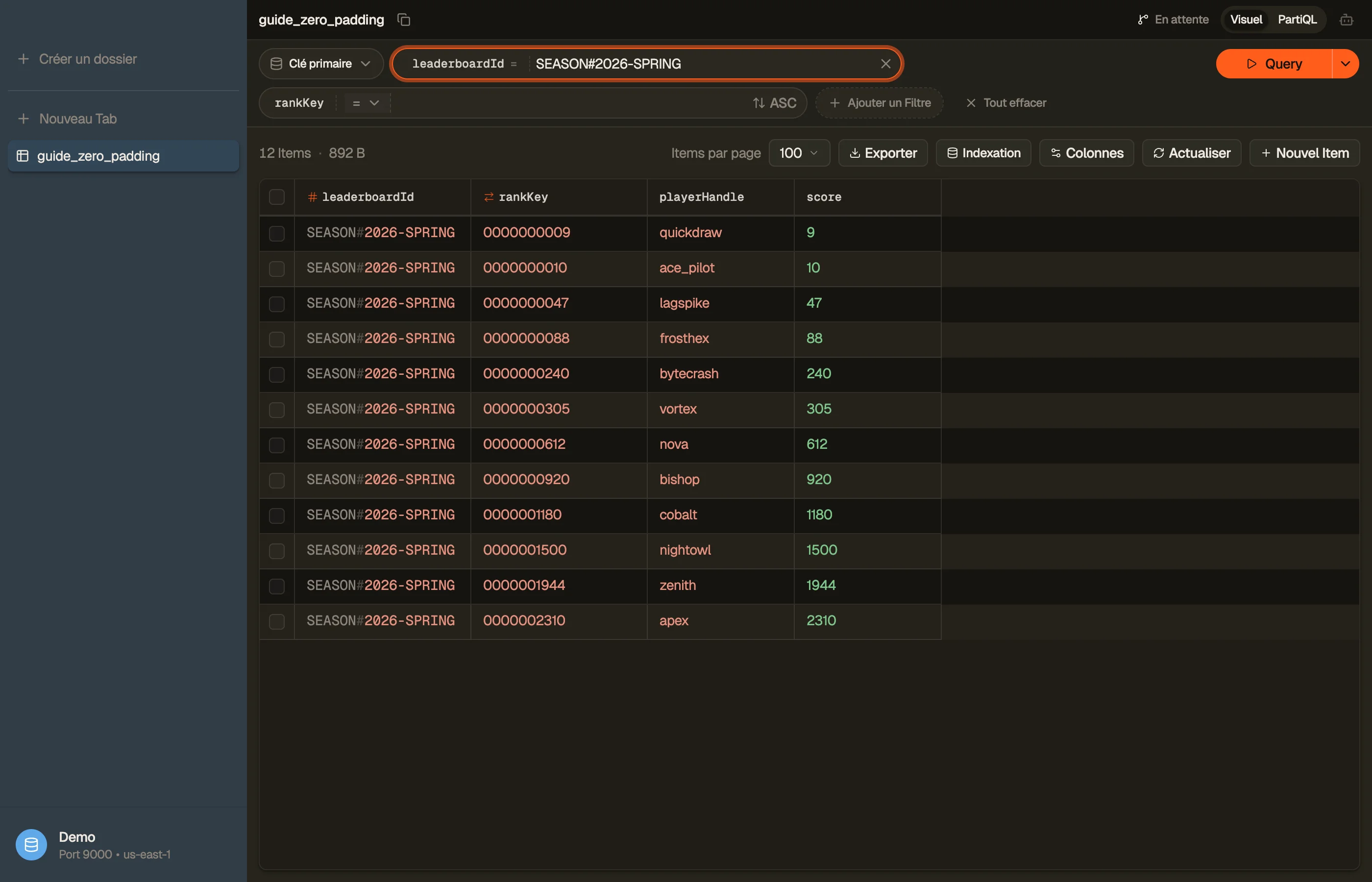
Choisis une largeur assez large pour le plus grand score que tu enregistreras jamais, puis pad à gauche avec des zéros. Disons que les scores plafonnent à dix millions — c'est huit chiffres, alors utilise dix chiffres pour la marge :
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "0000000009" | quickdraw |
| SEASON#2026-SPRING | "0000000010" | ace_pilot |
| SEASON#2026-SPRING | "0000000240" | bytecrash |
| SEASON#2026-SPRING | "0000001500" | nightowl |
Maintenant chaque clé fait la même longueur, donc la comparaison octet par octet et la
comparaison numérique produisent un ordre identique. Un Query ascendant donne 9, 10, 240, 1500. Les maths correspondent enfin aux octets.
La largeur est une porte à sens unique. Si tu pad à dix chiffres et qu'un score
dépasse ça plus tard, une valeur à 11 chiffres trie avant une à 10 chiffres — cassant
tout à nouveau — et la corriger signifie réécrire chaque rankKey existante.
Sur-provisionne la largeur ; le coût est une poignée d'octets.
Trier décroissant : stocker la différence
Un classement veut le score le plus élevé en premier. DynamoDB peut lire une clé de
tri vers l'avant ou vers l'arrière avec ScanIndexForward: false, donc le décroissant
est généralement un drapeau à la lecture — atteins ça en premier.
Mais quand une collection d'items doit servir des sens de tri mêlés, ou que tu veux le
meilleur score physiquement en premier indépendamment des drapeaux de lecture, inverse
le nombre lui-même. Stocke maxValue - score, zero-paddé à la même largeur :
score inverted (9999999999 - score) rankKey
1500 9999998499 "9999998499"
240 9999999759 "9999999759"
10 9999999989 "9999999989"
9 9999999990 "9999999990"L'ordre des octets ascendant sur la valeur inversée donne maintenant les scores
originaux du plus haut au plus bas : 1500, 240, 10, 9. L'astuce est dans l'esprit du
papier Amazon Dynamo de 2007
— les clés sont des octets opaques, donc tu encodes l'intention dans les octets.
Ajouter un départage
Deux joueurs peuvent être à égalité. Un score paddé nu entre en collision sur la clé de tri, et une seconde écriture écraserait la première (même PK + SK). Ajoute un suffixe unique pour que chaque run soit un item distinct et que les égalités se résolvent de façon déterministe :
rankKey = "<paddedScore>#<paddedTimestamp>#<playerId>"Par exemple "0000001500#0000001719100800#p_8842". À score égal, le timestamp plus
ancien gagne la meilleure place — pad aussi le timestamp, sinon il réintroduit
exactement le bug que tu viens de corriger.
Dans DynoTable, tu peux parcourir le classement de saison trié par la rankKey
zero-paddée et observer les valeurs remplies aligner correctement les lignes — preuve
que les largeurs sont bonnes avant de les déployer.
Quand tu assembles cette clé composite à la main, il est facile de se tromper d'un
chiffre de largeur. Générer le KeyConditionExpression pour un Query « haut de la
saison » dans l'expression builder garde la
syntaxe begins_with / between honnête pendant que tu expérimentes les largeurs.


Pièges à éviter
- Padding trop étroit. Tout le schéma s'effondre la première fois qu'une valeur déborde la largeur. Dimensionne pour le pire cas, puis ajoute des chiffres.
- Oublier le drapeau de lecture. Si tu lis seulement en décroissant,
ScanIndexForward: falsepeut suffire — n'atteins pas les clés inversées quand un drapeau le fait. - Largeurs mêlées dans une collection. Chaque clé partageant une plage de tri doit utiliser la même largeur. Une migration qui pad les nouvelles lignes mais pas les anciennes les entrelace mal.
- Padder le mauvais segment. Dans une clé composite, pad chaque segment numérique qui participe à l'ordre — le score et le timestamp tous les deux, pas seulement le score.
Étapes suivantes
Le zero-padding est un outil dans la boîte plus large de
conception de clé de tri ; associe-le aux
collections d'items quand tu surcharges une clé pour servir
plusieurs modes, et appuie-toi sur un Query précis plutôt qu'un
Scan une fois l'ordre correct.
Essaie DynoTable pour parcourir une vraie table et observer tes clés de tri zero-paddées tomber dans l'ordre numérique avant de livrer le schéma.