Comment modéliser des données dans DynamoDB
En SQL tu modélises d'abord les entités et les relations, puis tu fais confiance au planificateur de requêtes pour assembler plus tard tout ce que tu demandes. DynamoDB inverse ça. Tu modélises les lectures que tu sais déjà que tu feras, et les clés existent pour les servir.
Il n'y a pas de moteur de jointures ni de planificateur choisissant une stratégie à l'exécution. Un Query lit une partition le long d'une clé, et c'est tout le contrat de performance. Donc tu conçois les clés pour des motifs d'accès connus, pas pour un schéma soigné.
AWS le dit clairement dans son guide des bonnes pratiques : « tu ne devrais pas commencer à concevoir ton schéma avant de connaître les questions auxquelles il devra répondre ».
Ce guide parcourt tout le processus sur un domaine : un classement de jeu multijoueur qui suit les joueurs, les matchs qu'ils jouent, et leur classement par saison. On part d'une liste de questions pour arriver à un schéma de clés fonctionnel.
Comment modéliser des données dans DynamoDB ?
Modélise d'abord les lectures, pas les tables. Liste chaque requête que l'application effectue, puis conçois une et une pour que chaque question se résolve en un seul Query ou GetItem. Co-localise les items lus ensemble, range les valeurs dans la clé de tri, et ajoute un GSI pour tout motif d'accès que la table de base ne peut pas servir.
- Liste d'abord les lectures, pas les tables. Les questions sont le cahier des charges ; les noms sont une distraction.
- Chaque question doit être un seul
QueryouGetItem. Si une question nécessite unScan, le modèle est faux. - Les items co-localisés partagent une clé de partition ; tout ce sur quoi tu fais une plage va dans la clé de tri.
- Une question à laquelle la table de base ne peut pas répondre obtient un GSI — jamais un
Scanavec un filtre.
Étape 1 — Cadre le problème en questions, pas en tables
Résiste à l'envie de dessiner les tables players, matches et scores. Cet instinct est l'habitude SQL, et ici il est faux. Écris plutôt chaque lecture que l'application effectue réellement. Pour notre classement :
- Récupérer le profil d'un joueur par id.
- Lister les matchs récents d'un joueur, du plus récent au plus ancien.
- Afficher les N meilleurs joueurs d'une saison donnée, classés par rating.
- Rechercher un joueur par son pseudo public (p. ex. pour une URL de profil).
Ces quatre questions — pas les noms — sont le cahier des charges. Chacune doit se résoudre en un seul Query (ou GetItem), parce que c'est la seule forme d'accès que DynamoDB sert à bas coût à grande échelle.
Si on ne peut répondre à une question qu'en scannant la table, le modèle est faux, et tu le sentiras dans la latence et le coût — vois Query vs Scan pour comprendre pourquoi un Scan est l'arme à fragmentation à éviter.
Toute la méthode est un pipeline court et ordonné que tu exécutes une fois par domaine :
Chaque étape ci-dessous correspond à une boîte : lister, énumérer, concevoir les clés, ajouter des index pour le reste, puis valider.
Étape 2 — Comprends les primitives avec lesquelles tu modélises
Une table a une clé de partition (PK) qui choisit sur quelle partition physique un item vit, et une clé de tri (SK) optionnelle qui ordonne les items au sein de cette partition.
La doc des composants de base d'AWS appelle la paire la clé primaire de l'item. Un Query cible toujours exactement une valeur de PK et peut faire une plage ou filtrer la SK — c'est tout l'outillage.
Cette conception à partition unique est ce qui laisse DynamoDB délivrer les lectures prévisibles, à faible latence et partitionnées horizontalement décrites pour la première fois dans le papier Amazon Dynamo de 2007.
Deux conséquences pilotent chaque décision ci-dessous :
- Les items lus ensemble doivent partager une clé de partition pour qu'un seul
Queryles renvoie en une seule requête facturée. - Tout ce sur quoi tu veux faire une plage (matchs récents, meilleurs ratings) doit vivre dans la clé de tri, car c'est le seul attribut qu'un
Querypeut ordonner et borner.
Quand une question nécessite une forme d'accès différente de celle que fournit la table de base, tu ajoutes un Global Secondary Index — une reprojection de la table sous une autre PK/SK.
(Pour le GSI versus le Local Secondary Index, vois GSI vs LSI.)
Étape 3 — Conçois les clés, une question à la fois
On utilise une seule table avec des attributs de clé génériques et surchargés — l'approche single-table — parce qu'un joueur et ses matchs sont lus ensemble.
Invente tes propres préfixes ; ici PLAYER#, MATCH# et SEASON# étiquettent le type d'entité dans des clés par ailleurs génériques.
Les questions 1 et 2 (profil + matchs récents) partagent une partition, donc les deux pendent de la même PK :
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" renvoie le profil et chaque match en une seule lecture. Pour le profil seul, GetItem.
Pour les matchs récents, rangeId begins_with "MATCH#" avec ScanIndexForward = false les parcourt du plus récent au plus ancien — l'horodatage dans la clé de tri fait l'ordonnancement gratuitement.
Les questions 3 et 4 ne peuvent pas être répondues depuis cette partition — elles pivotent sur le rang de saison et sur le pseudo, dont aucun n'est la PK de base. Chacune obtient un GSI.
On ajoute deux attributs d'index génériques, gsiPartition / gsiSort, et on laisse chaque item les peupler avec ce dont cet index a besoin :
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Maintenant Query sur l'index de saison WHERE gsiPartition = "SEASON#2026-Q2" avec ScanIndexForward = false renvoie les joueurs classés par rating — c'est le classement.
Un second index clé sur HANDLE#… résout un pseudo public en id de joueur en une seule lecture. Une table physique, quatre motifs d'accès en un seul Query.
Une note sur le complétage par zéros de
RATING#1842: DynamoDB trie les clés de tri lexicographiquement, pas numériquement, donc un rating doit être complété par des zéros à une largeur fixe (RATING#01842) sinon9se trierait après1000. C'est un piège de modélisation classique à bien faire dès le départ.
Étape 4 — Valide le modèle dans DynoTable
Un schéma de clés ne gagne ta confiance que quand tu regardes un vrai Query renvoyer exactement les items que tu attendais et rien de plus.
Ouvre la table dans DynoTable, lance la requête du classement contre l'index de saison, et confirme que la partition revient classée et bornée — pas de Scan, pas de tri côté client.

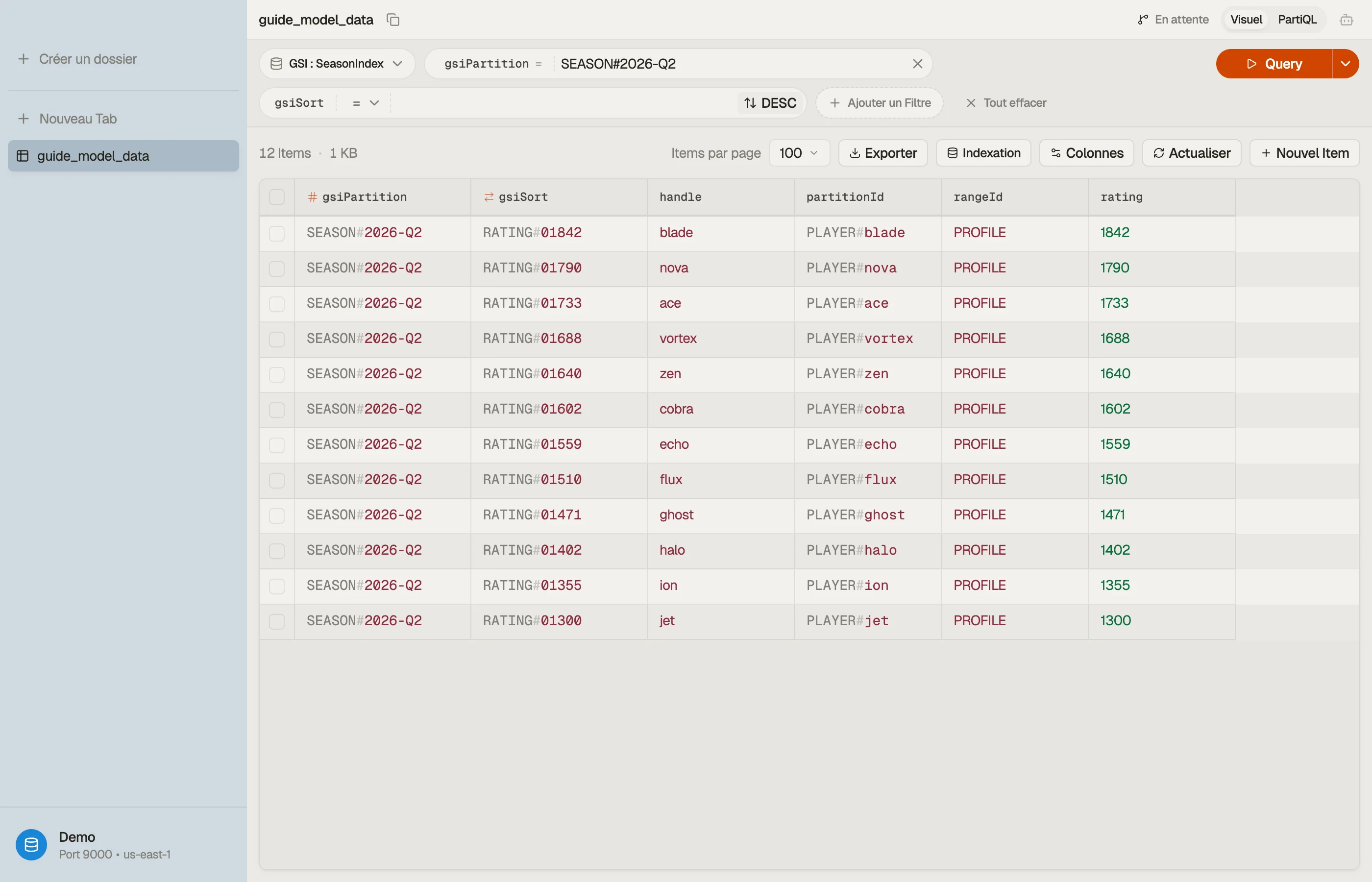

Quand tu construis les condition expressions de ces requêtes — le begins_with, le gsiPartition = :p, le binding du placeholder :p — laisse le DynamoDB Expression Builder le faire.
Il génère la KeyConditionExpression, les ExpressionAttributeNames et les ExpressionAttributeValues, pour qu'un mot réservé comme result ou un placeholder mal tapé ne casse jamais silencieusement une lecture.
Étape 5 — Pièges et étapes suivantes
Quelques pièges à vérifier avant de livrer le modèle :
- Ne modélise pas des relations que tu ne lis jamais ensemble. Un GSI par question est bon marché ; un GSI inutile est un coût récurrent. Ajoute des index depuis la liste de questions, pas de façon spéculative.
- Surveille la chaleur des partitions. Si une PK (un joueur célèbre, une seule saison chaude) absorbe la plupart du trafic, cette partition peut throttler. Disperse les écritures avec un shard en suffixe quand une clé est prouvée chaude — AWS couvre ça sous partition-key design.
- Complète par des zéros et passe en ISO-8601 tout ce qui est numérique ou temporel dans une clé de tri, pour que l'ordre lexicographique corresponde à l'ordre que tu veux dire.
- Une nouvelle question = une nouvelle clé ou un nouvel index, jamais un
Scan. Quand un motif d'accès véritablement nouveau apparaît plus tard, étends les clés ; ne le masque pas avec un filtre.
Modélise d'abord les questions, conçois les clés pour que chacune soit un seul Query, puis prouve-le.
Essaie DynoTable pour parcourir ta table, lancer ces requêtes côte à côte contre la table de base et les GSI, et regarder les motifs d'accès que tu as conçus renvoyer exactement ce que tu avais prévu.