Les item collections DynamoDB
Une item collection est l'ensemble de tous les items d'une table (ou d'un index) qui partagent la même valeur de clé de partition. Ce n'est pas une fonctionnalité que tu actives — c'est une propriété émergente de ton schéma de clés.
Dès l'instant où deux items portent la même clé de partition, ils forment une
collection, et cette collection devient l'unité que DynamoDB te laisse lire ensemble
dans un seul Query.
Fais-le bien et tes lectures reviennent en un aller-retour. Fais-le mal et tu es
coincé avec un Scan.
Qu'est-ce qu'une item collection DynamoDB ?
Une item collection DynamoDB est l'ensemble de tous les items qui partagent la même valeur de clé de partition, stockés ensemble et triés par clé de tri. Ce n'est pas une fonctionnalité que tu actives — c'est une propriété émergente de ton schéma de clés. La collection est l'unité qu'un seul Query lit efficacement, là où un Scan parcourt chaque partition.
- Une collection, c'est juste « même clé de partition ». Deux items ou plus avec la même valeur de clé de partition sont stockés ensemble, triés par clé de tri.
- C'est l'unité d'un
Queryefficace.Querylit une collection ;Scanparcourt chaque partition. C'est toute l'histoire de la performance. - Pas de clé de tri, pas de collection. Une table à clé de partition seule contient un item par clé — rien à collecter.
- Deux limites mordent : le plafond de 10 Go par collection quand un LSI existe, et les partitions chaudes dues aux clés à faible cardinalité.
Le problème : lire ensemble des items liés
Disons que tu exploites une flotte de véhicules, chacun diffusant de la télémétrie —
vitesse, température du liquide de refroidissement, niveau de carburant — toutes les
quelques secondes. La lecture dominante est « donne-moi les relevés récents du
véhicule V-7741 ».
Venant de SQL, tu indexerais une colonne vehicle_id et laisserais le planificateur
faire le travail. Un simple key-value store n'a pas ce luxe.
Il traite chaque relevé comme un enregistrement isolé, donc cette question signifie scanner toute la table et filtrer. Lent, coûteux, et pire à mesure que la flotte grandit.
La réponse de DynamoDB est de faire de « tous les relevés d'un véhicule » une chose physiquement groupée et directement adressable. Ce groupement est l'item collection.
Ce qu'est réellement une collection
DynamoDB stocke les items dans des partitions, et il route chaque item vers une partition en hachant sa clé de partition. Chaque item avec la même valeur de clé de partition atterrit donc dans la même partition, trié par clé de tri.
Le AWS Developer Guide le nomme exactement : les items qui partagent une valeur de clé de partition sont une item collection, stockés ensemble et ordonnés par clé de tri.
C'est la même idée que celle introduite par le papier Amazon Dynamo de 2007 — le hachage cohérent pour assigner les clés aux nœuds — étendue d'une dimension de tri pour que les items liés soient adjacents sur le disque.
Parce qu'ils sont adjacents et ordonnés, DynamoDB en renvoie une séquence contiguë
avec un seul accès. C'est pourquoi Query est bon marché et Scan ne l'est pas :
Query lit une seule collection ; Scan parcourt chaque partition.
Pour former une collection il te faut une clé primaire composite — une clé de partition et une clé de tri. Une table clée sur la seule clé de partition a exactement un item par valeur de clé, donc il n'y a rien à collecter.
Notre exemple travaillé : véhicule → relevés de télémétrie
Modélise le flux de télémétrie avec une clé composite. La clé de partition identifie le véhicule ; la clé de tri est l'horodatage du relevé, ce qui garde les relevés ordonnés du plus récent au plus ancien dans la collection.
PK (vehicleId) SK (recordedAt) attributes
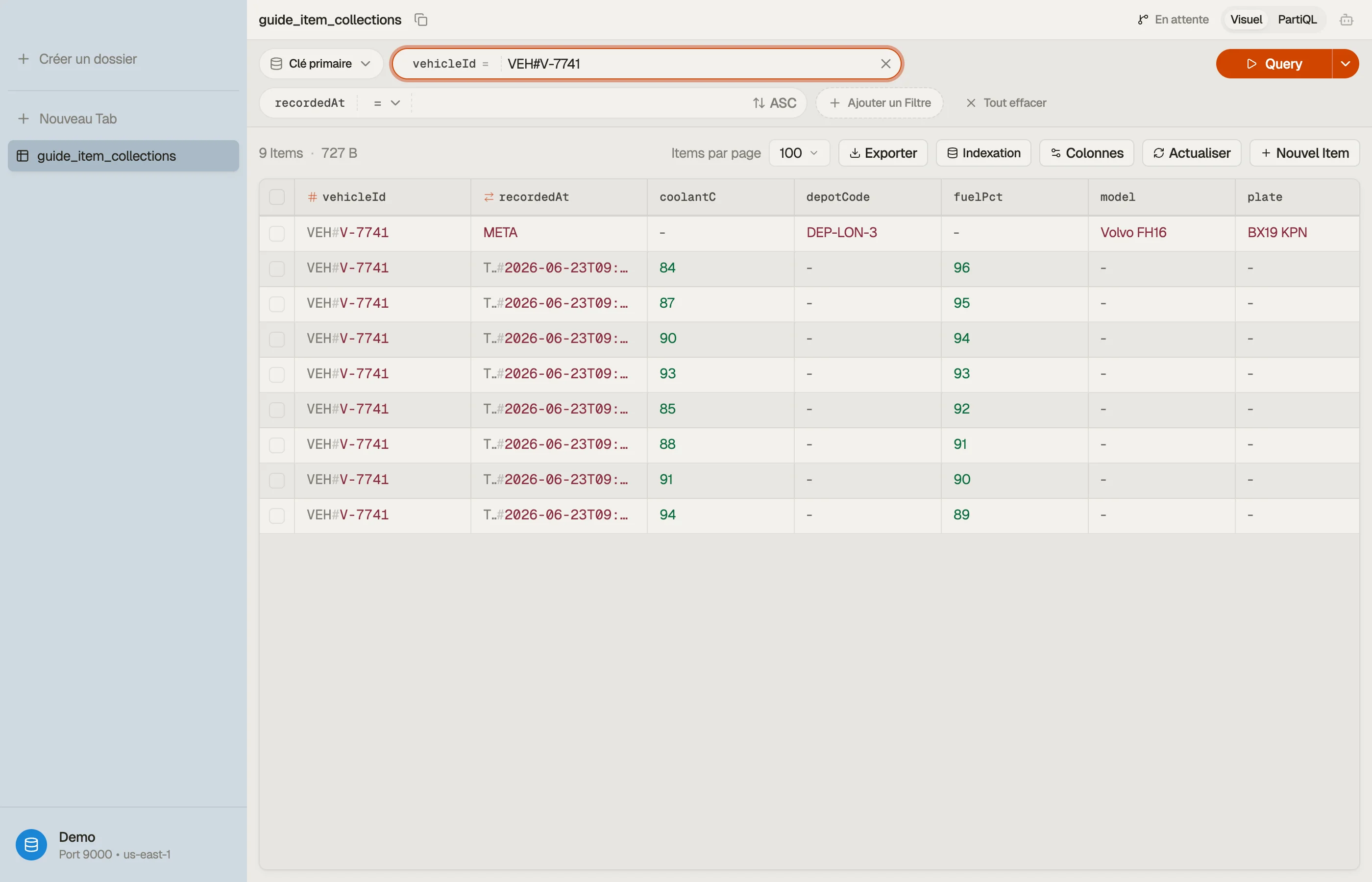
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPctDeux collections vivent ici — une par véhicule. L'item META (métadonnées du
véhicule) et tous les relevés de V-7741 forment une collection ; les items de
V-7742 en forment une autre.
Note l'astuce : donne aux métadonnées une clé de tri (META) qui se trie avant
n'importe quelle valeur TS#..., et un seul Query sur PK = "VEH#V-7741" renvoie
le profil du véhicule et ses relevés ensemble.
C'est le motif parent-et-enfants au cœur du single-table design.
Chaque boîte en pointillé est une item collection : même clé de partition, items
triés par clé de tri. Un Query lit exactement une boîte.
Interroger une collection
Parce que la collection est triée par clé de tri, tu obtiens les lectures de plage gratuitement. Pour tirer les relevés enregistrés dans une fenêtre de dix minutes pour un véhicule, tu bornes la clé de tri :
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest firstLa condition de clé te restreint à une collection (vehicleId = :v) puis à une
tranche contiguë de celle-ci (recordedAt BETWEEN ...). DynamoDB ne lit que ces
items et ne te facture que pour eux. Tu veux juste les métadonnées ?
recordedAt = "META" récupère le seul item META.
Construire ces conditions de clé et expressions de projection à la main est délicat.
Le DynamoDB Expression Builder génère la
KeyConditionExpression, les ExpressionAttributeNames et les
ExpressionAttributeValues pour toi, pour que les détails de mots réservés et de
placeholders ne mordent pas.
Les collections sur les index
Un index secondaire a son propre schéma de clés, donc il forme ses propres item collections.
Ajoute un global secondary index clé sur depotCode (partition) et recordedAt
(tri), et « tous les relevés du dépôt DEP-LON-3, du plus récent au plus ancien »
devient un seul Query contre la collection de cet index — une lecture que la table
de base ne peut pas servir.
C'est pourquoi le type d'index compte : il gouverne les collections que tu peux former et leur comportement. Vois GSI vs LSI pour le compromis.
Une distinction nette : un local secondary index (LSI) partage la clé de partition de la table de base, donc sa collection est physiquement liée à l'item collection de base — et ce lien crée une limite dure, plus bas.
Les limites qui mordent
Les item collections sont puissantes, mais deux contraintes décident comment tu façonnes les clés :
- La limite de 10 Go du LSI. Quand une table a un ou plusieurs local secondary
indexes, une seule item collection — les items de base plus leurs projections LSI
pour une clé de partition — ne peut pas dépasser 10 Go. Dépasse-la et les
écritures qui font grossir la collection commencent à échouer avec
ItemCollectionSizeLimitExceeded. Une table sans LSI n'a pas un tel plafond par collection. C'est exactement pourquoi un flux non borné et en croissance perpétuelle (de la télémétrie qui ne s'arrête jamais) convient mal à un LSI : la collection ne fait que grossir. Un GSI obtient ses propres partitions, donc il contourne la limite. - Partitions chaudes. Une collection vit dans une partition, et une seule
partition a un débit fini. Si un véhicule (ou un
depotCode) attire une part follement disproportionnée du trafic, tu peux surchauffer cette partition même pendant que la table dans son ensemble est sous-provisionnée. L'adaptive capacity — couverte dans les deep-dives re:Invent « Advanced Design Patterns for DynamoDB » d'AWS — isole et booste les clés chaudes automatiquement, mais elle ne peut pas sauver une clé sans aucune dispersion. Choisis des clés de partition à haute cardinalité pour que le trafic s'éparpille sur de nombreuses collections.
Vois-le dans DynoTable
Le moyen le plus rapide de bâtir une intuition des collections est d'en regarder
une. Dans DynoTable, interroger une clé de partition rend toute la collection comme
une liste contiguë ordonnée par clé de tri — l'item META se trouve juste devant ses
relevés horodatés, à l'écran, sans reconstruction mentale requise.


Pièges et étapes suivantes
- Pas de clé de tri, pas de collection. Une table à clé de partition seule ne peut pas grouper d'items liés. Si tu as besoin de lire des items ensemble, il te faut une clé composite.
- Ne laisse pas une collection LSI grossir sans borne. Les flux en append-only appartiennent à un GSI (ou à une clé de partition découpée par tranches de temps), pas à un LSI, à cause du plafond de 10 Go.
- Éparpille tes clés de partition. Une collection n'est aussi scalable que la partition où elle vit. Les clés de partition à faible cardinalité créent des points chauds.
- Utilise
Query, pasScan. Les collections existent pour que tu puisses lire des items liés avec un seulQueryciblé ; retomber sur unScanjette cet avantage — vois Query vs Scan.
Esquisse ton propre schéma de clés, lance un Query contre une vraie clé de
partition, et regarde la collection revenir ordonnée. Télécharge DynoTable
et explore directement les collections de tes tables.