Stratégies de clé de tri DynamoDB
Une clé primaire DynamoDB est un ou deux attributs : une clé de partition seule, ou une clé de partition plus une clé de tri. La clé de partition décide quelle partition physique contient un item.
La clé de tri décide l'ordre des items à l'intérieur de cette partition — et cet
ordonnancement est ce qui rend Query puissant.
Choisis la mauvaise clé de tri et tu peux toujours écrire des données, mais tu perds les lectures de plage, l'ordonnancement et plusieurs motifs d'accès depuis une seule collection.
Venant de SQL tu sortirais un ORDER BY ou un index secondaire après coup. Dans
DynamoDB tu cuis l'ordre dans la clé dès le départ, ou tu ne l'obtiens pas.
Comment fonctionnent les clés de tri DynamoDB ?
Une clé de tri DynamoDB ordonne les items au sein d'une partition, de sorte que Query peut effectuer des lectures de plage — >=, between, begins_with — au lieu de récupérer un item à la fois. L'ordonnancement est l'ordre des octets sur la clé encodée, donc conçois-la (un horodatage ISO-8601, un nombre complété par des zéros) pour que l'ordre des octets corresponde à l'ordre dans lequel tu veux lire.
- La clé de tri est ton index intra-partition. Elle ordonne l'item collection
sur le disque, donc
Querypeut faire des lectures de plage (>=,between,begins_with) au lieu d'un simpleGetItem. - L'ordonnancement est l'ordre des octets sur la clé encodée. Conçois la clé
pour que l'ordre des octets égale l'ordre que tu veux lire — un horodatage
ISO-8601, un nombre complété par des zéros, jamais un UUID brut ou
6/23/2026. - Une clé de tri bien façonnée sert plusieurs motifs d'accès. Une clé composite
(
EVT#<timestamp>) est un préfixe et une plage à la fois — pas de GSI nécessaire. - La direction est gratuite.
ScanIndexForward = falselit du plus récent au plus ancien au même coût ; ne stocke pas d'horodatages inversés pour la simuler.
Pourquoi la clé de tri est le levier
Sans clé de tri, chaque item d'une partition n'est adressable que par sa clé primaire
complète — un GetItem au mieux. Ajoute une clé de tri et DynamoDB stocke les items
triés par elle au sein de la partition, ce qui débloque Query.
Ça signifie les conditions de plage (>=, between), la correspondance de préfixe
(begins_with) et un flag ScanIndexForward pour lire en ordre croissant ou
décroissant.
D'après le AWS DynamoDB Developer Guide, tous les items partageant une clé de partition forment une item collection, ordonnée sur le disque par la clé de tri.
Donc la clé de tri n'est pas qu'un second identifiant. C'est l'index contre lequel tu interroges à l'intérieur d'une partition.
Cet ordonnancement est l'ordre des octets sur la clé de tri encodée : les chaînes se comparent par octets UTF-8, les nombres se comparent numériquement. Ce seul fait pilote presque toutes les stratégies ci-dessous.
Si tu veux que les requêtes de plage veuillent dire quelque chose, l'ordre des octets doit correspondre à l'ordre que tu veux lire.
Stratégie 1 : rends la clé de tri triable
L'erreur la plus courante est une clé de tri qui n'est pas ordonnée de façon significative. Un UUID aléatoire te donne l'unicité mais aucune requête de plage utile — « donne-moi les 20 derniers » devient impossible parce que l'ordre des octets est arbitraire.
À la place, encode la valeur sur laquelle tu tries et filtres dans la clé de tri, dans une représentation dont l'ordre des octets égale son ordre logique. Pour les horodatages ça veut dire un format triable lexicographiquement : une chaîne ISO-8601 ou un epoch complété par des zéros.
ISO-8601 a été conçu pour que la comparaison de chaînes égale la comparaison
chronologique — exactement ce dont une requête de plage a besoin. Évite les formats
comme 6/23/2026 ; ils se trient mal dès que le mois bascule.
Si tu tries sur des nombres (un compteur de version, un score), utilise le type
Number natif de DynamoDB plutôt qu'une chaîne, pour que 42 se trie après 9
au lieu d'avant.
Si un nombre doit vivre à l'intérieur d'une clé de tri chaîne composite, complète-le par des zéros à une largeur fixe.
Stratégie 2 : clés de tri composites pour la hiérarchie
Une clé de tri peut encoder une hiérarchie en concaténant des segments avec un
délimiteur, le plus souvent #. Une seule condition begins_with sélectionne alors
tout un sous-arbre :
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") renvoie juste les événements de juin ; le plus
large begins_with(SK, "EVENT#") les renvoie tous.
L'ordre des segments est une décision de conception. Du grossier vers le fin (année → mois → jour) garde les items liés contigus, de sorte qu'une lecture de plage reste une seule requête bon marché au lieu d'une dispersion à travers la partition.
Stratégie 3 : contrôle la direction avec ScanIndexForward
DynamoDB stocke les items en ordre croissant de clé de tri et les lit ainsi par
défaut. Pour lire du plus récent au plus ancien — l'ordre naturel d'un fil d'activité
— pose ScanIndexForward = false sur le Query.
C'est un flag à la lecture, pas une décision de schéma : la même collection sert les deux directions au même coût. N'inverse pas tes horodatages (en stockant un « epoch inversé ») juste pour obtenir des lectures décroissantes.
Une item collection, stockée une fois en ordre croissant, lue dans les deux sens :
Mêmes items, même partition, même coût — seule la direction de lecture diffère.
La seule exception : si tu as spécifiquement besoin que l'ordre décroissant soit aussi
l'ordre dans lequel un sparse index ou un curseur de pagination avance. À part ça,
ScanIndexForward est le levier le plus simple.
Exemple travaillé : un journal d'audit limité par acteur
Suppose que tu enregistres des événements horodatés produits par des acteurs — utilisateurs, services, clés API — dans un produit SaaS, et que tu as deux lectures :
- Le flux d'activité d'un acteur, événement le plus récent d'abord.
- Les événements d'un acteur dans une fenêtre temporelle (p. ex. « tout ce qui s'est passé entre les deux déploiements »), pour une investigation.
Les deux lectures sont limitées à un seul acteur, donc l'acteur est la clé de partition et l'heure de l'événement est la clé de tri. Utilise des noms de clé génériques pour que la même table puisse contenir d'autres entités plus tard :
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
Le préfixe EVT# plus un horodatage ISO-8601 donne une clé de tri triable. La
lecture 1 est Query PK = "ACTOR#u_8814" avec ScanIndexForward = false pour le plus
récent d'abord. La lecture 2 restreint la même partition avec une condition between
sur la clé de tri :
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"Une collection, deux motifs d'accès, pas de GSI — parce que la clé de tri est à la
fois un préfixe (EVT#) et une plage (l'horodatage). La lecture décroissante et la
lecture par fenêtre sont les mêmes items dans le même ordre ; seuls les paramètres
diffèrent.
En construisant cette condition de clé à la main, il est facile de se tromper sur les
bornes du between ou sur l'échappement des mots réservés dans les noms d'attribut.
Le DynamoDB Expression Builder génère
la KeyConditionExpression, les ExpressionAttributeNames et les
ExpressionAttributeValues pour une condition de clé de tri begins_with ou
between.
Copie-le directement dans ton appel SDK au lieu de déboguer l'échappement à l'exécution.
Fais-le dans DynoTable
Concevoir une clé de tri est itératif : écris quelques items représentatifs, lance la requête de plage, et vérifie que les lignes reviennent dans l'ordre attendu. Faire ça contre une table en direct dans une GUI vaut mieux que des allers-retours par le code.

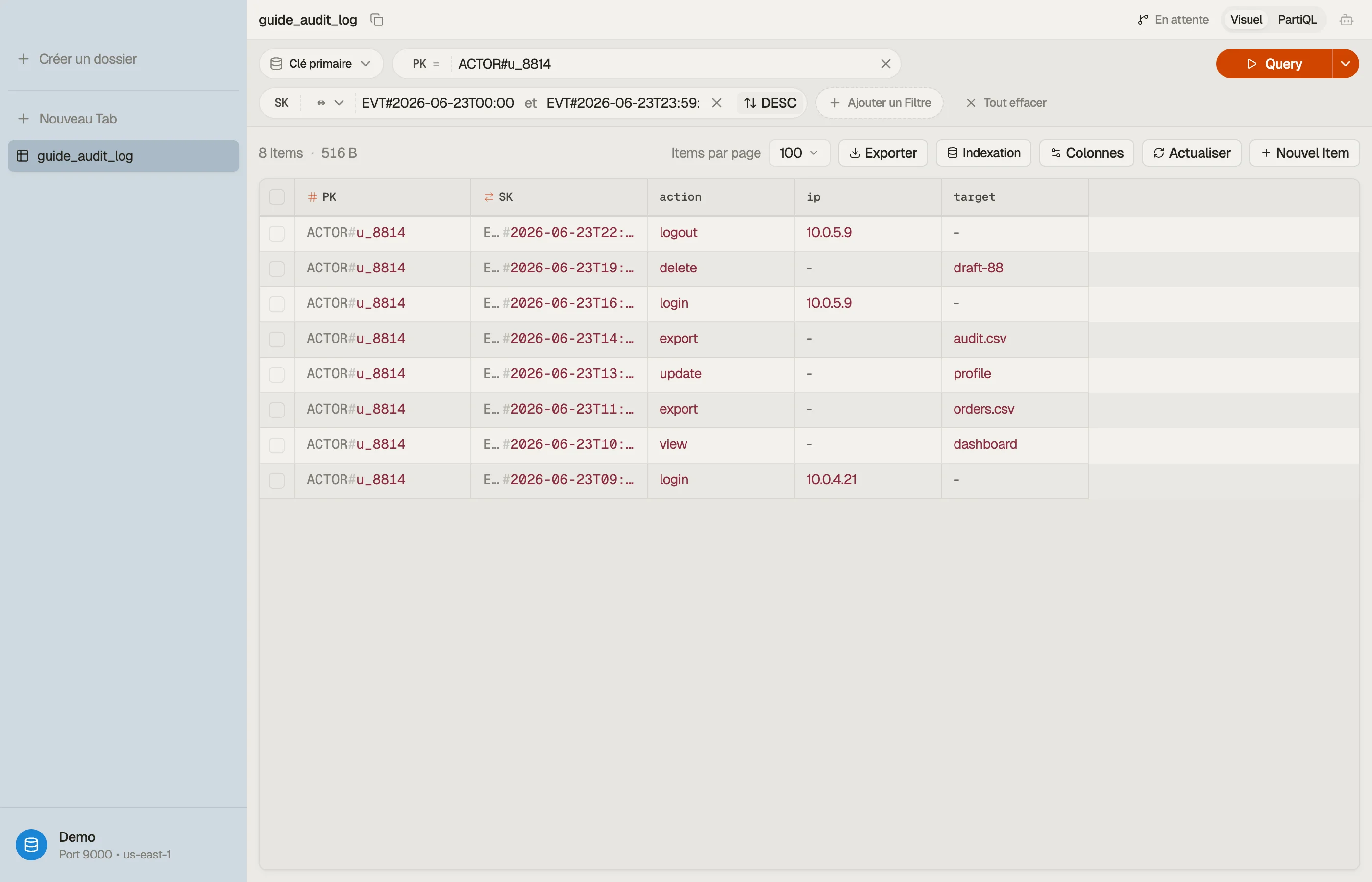

Inverse le sens de tri, resserre les bornes du between, et regarde la collection
renvoyée changer sans écrire une ligne de code — le moyen le plus rapide de confirmer
une conception de clé de tri avant de la valider.
Pièges et étapes suivantes
- Les clés de tri doivent être uniques au sein d'une partition. Si deux événements peuvent partager un horodatage, ajoute un désambiguïsateur (un numéro de séquence ou un id court) à la clé de tri pour que la composite reste unique.
- On ne peut pas contourner une partition chaude par le tri. Si un acteur produit bien plus d'événements que les autres, la clé de tri ne te sauvera pas — il te faut une conception de clé de partition qui répartit la charge. Vois single-table design.
- Un second ordre de tri nécessite un second index. La clé de tri de la table de base donne un seul ordonnancement. Pour ordonner les mêmes items différemment (par type d'événement, disons), ajoute un GSI avec une autre clé de tri — en pesant les compromis local vs global secondary index.
- Ne sors pas un
Scanpour « trier plus tard ». Trier côté client après unScanlit toute la table et jette l'ordonnancement ; c'est l'arme à fragmentation du Scan. Pousse plutôt l'ordre dans la clé de tri.
Une fois la condition de clé correcte, essaie DynoTable pour modéliser la collection, lancer côte à côte les requêtes croissantes et décroissantes, et vérifier ta stratégie de clé de tri contre de vraies données avant qu'elle ne parte en production.