Opérations par lots DynamoDB : BatchGetItem & BatchWriteItem
Quand tu dois lire ou écrire beaucoup d'items d'un coup, déclencher un GetItem ou un
PutItem par item signifie un aller-retour réseau par item — lent, et bavard. Les API
par lots de DynamoDB replient de nombreuses opérations d'item en une seule requête :
BatchGetItem pour les lectures, BatchWriteItem pour les écritures.
C'est un gain de débit et de latence, pas une garantie de cohérence — et cette distinction est là où les gens se brûlent. Un lot n'est pas une transaction.
Que sont les opérations par lots DynamoDB ?
Les opérations par lots de DynamoDB replient de nombreuses lectures ou écritures d'items en une seule requête : BatchGetItem récupère jusqu'à 100 items, BatchWriteItem insère ou supprime jusqu'à 25, chacune plafonnée à 16 Mo. Elles économisent des allers-retours, pas de la capacité. Point crucial : un lot n'est pas une transaction — les items réussissent ou échouent indépendamment, sans rollback.
BatchGetItem— récupère jusqu'à 100 items (ou 16 Mo) à travers une ou plusieurs tables en un seul appel.BatchWriteItem— jusqu'à 25 opérations put/delete (ou 16 Mo) en un seul appel. Pas de mises à jour — puts et deletes uniquement.- Pas atomique. Des items individuels peuvent réussir pendant que d'autres échouent. Il n'y a pas de rollback.
- L'échec partiel est normal. Les items ralentis reviennent dans
UnprocessedItems/UnprocessedKeys— tu dois les réessayer toi-même, avec backoff. - Même coût de capacité que les appels individuels — le batching économise des allers-retours, pas des unités de capacité.
Le problème : beaucoup d'items, un aller-retour
Disons que tu gères un service de support. Un tableau de bord doit charger 50 tickets par ID pour afficher une file ; un job de nuit archive 1 000 tickets résolus. Le faire un item à la fois, c'est 50 (ou 1 000) allers-retours séquentiels — la latence s'empile et le job rampe.
Le batching réduit ça à une poignée d'appels. La lecture des 50 tickets devient un seul
BatchGetItem ; le job d'archivage devient un flux d'appels BatchWriteItem de 25
deletes chacun. Bien moins d'allers-retours, les mêmes données déplacées.
Comment fonctionnent les API par lots
BatchGetItem prend un ensemble de clés primaires (à travers une ou plusieurs
tables) et renvoie les items correspondants. Tu peux demander des lectures fortement
cohérentes par table. Tout ce qu'il n'a pas pu lire — généralement parce que la requête
a frôlé une limite de débit — revient dans UnprocessedKeys plutôt que de faire
échouer tout l'appel.
BatchWriteItem prend une liste d'opérations PutRequest / DeleteRequest. Note
ce qui manque : il n'y a pas d'update. Une écriture par lot remplace soit un item
entier (put) soit le supprime (delete) — pour modifier des attributs précis tu as
toujours besoin d'UpdateItem. Les items qu'il n'a pas pu écrire reviennent dans
UnprocessedItems.
Le modèle mental clé : un lot est un paquet d'opérations indépendantes, chacune réussissant ou échouant de son côté — pas une seule unité tout-ou-rien.
Les lots ne sont pas des transactions
C'est le piège. Si le lot de ton job d'archivage atteint une limite de débit à mi-chemin, certains tickets sont supprimés et d'autres non — et DynamoDB n'annule pas ceux qui sont passés. Pas de rollback, pas d'isolation, pas de « les 25 ou aucun ».
Si tu as besoin de sémantique tout-ou-rien — « déplace le ticket vers archivé et
décrémente le compteur de tickets ouverts, ou ne fais ni l'un ni l'autre » — c'est
TransactWriteItems, pas un lot. Les transactions
coûtent plus cher (chaque opération est facturée double) et plafonnent à 100 items, mais
elles te donnent l'atomicité que les lots ne délivrent délibérément pas.
Gérer les items non traités
Un appelant de lot correct vérifie toujours l'ensemble non traité et le réessaie.
DynamoDB renvoie UnprocessedItems/UnprocessedKeys chaque fois que la requête dans
son ensemble a été acceptée mais que certains items n'ont pas pu être servis —
typiquement du ralentissement transitoire.
Re-soumets seulement les items non traités, avec backoff exponentiel et jitter. Traiter un lot en mode « fire-and-forget » abandonne silencieusement des écritures — le genre de bug qui refait surface des mois plus tard sous forme de données manquantes.
Les écritures par lots dans DynoTable
Estime d'abord ce qu'un job en masse coûtera avec le calculateur de tarifs DynamoDB — un lot consomme la même capacité que les écritures individuelles qu'il regroupe, juste en moins de requêtes.
Dans DynoTable, tu mets tes modifications en attente localement et tu les révises avant de les valider sous forme d'écritures par lots efficaces — les changements en masse sur de nombreuses lignes partent en requêtes groupées plutôt qu'un appel API par changement, avec le réessai des items non traités géré pour toi.



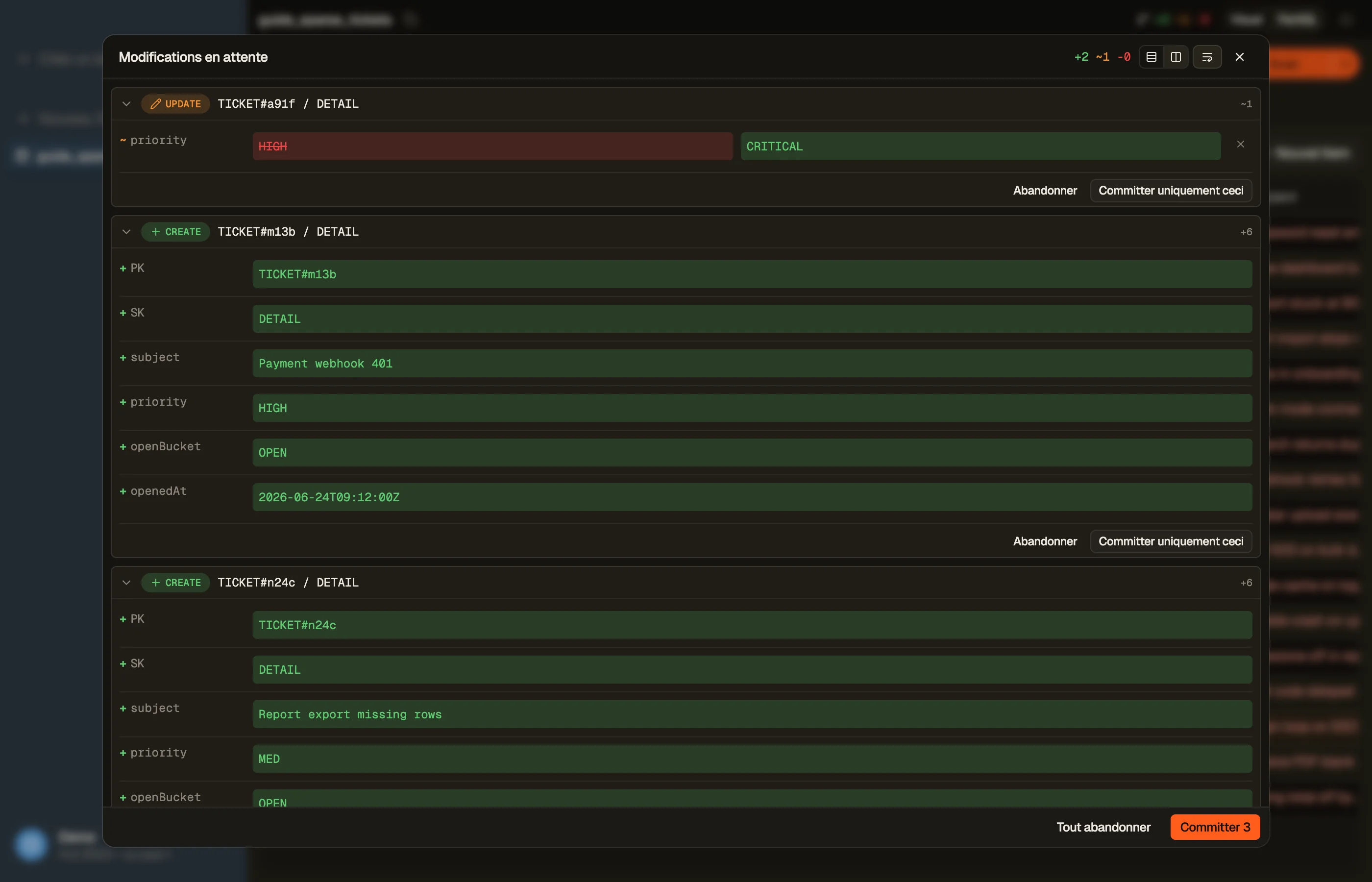
Pièges et étapes suivantes
- Réessaie toujours
UnprocessedItems/UnprocessedKeysavec backoff — ils sont attendus, pas exceptionnels. - Pas de rollback en cas d'échec partiel. Besoin d'atomicité ? Utilise les transactions.
- Pas d'update dans une écriture par lot —
BatchWriteItemest put/delete uniquement ; sorsUpdateItempour changer des attributs. - Attention aux plafonds par appel — 25 écritures / 100 lectures / 16 Mo. Pagine à travers les jobs plus gros ; voir la pagination.
Envie de lancer des lectures et écritures en masse sans scripter la boucle de réessai ? Télécharge DynoTable et édite tes tables directement.