Les sparse indexes DynamoDB
Un sparse index est un index secondaire qui ne contient que les items portant son attribut de clé — de sorte qu'un petit sous-ensemble chaud d'une table énorme devient sa propre collection pré-filtrée et prête à interroger.
Tu as des millions de lignes mais la requête que tu lances toute la journée ne touche qu'une tranche minuscule : les tickets de support ouverts, les factures impayées, les comptes signalés pour examen.
Filtrer cette tranche scanne quand même toute la table et te facture chaque lecture. Un sparse index rend l'index lui-même petit à la place.
Qu'est-ce qu'un sparse index dans DynamoDB ?
Un sparse index est un index secondaire qui ne contient que les items portant son attribut de clé. Parce que DynamoDB ignore tout item qui n'a pas cette clé, tu inventes une clé que seuls les items voulus écrivent — tickets ouverts, factures impayées — et l'index devient exactement ce sous-ensemble. Les requêtes ne lisent alors que lui, sans filtre, sans capacité de lecture gaspillée.
- Un index secondaire n'indexe que les items qui ont sa clé. Omets la clé sur un item et il n'entre jamais dans l'index — pas de placeholder, pas de ligne nulle.
- Donc tu inventes une clé que seuls les items voulus portent. Écris-la sur les items que tu interroges, retire-la sur les autres. L'index devient exactement ce sous-ensemble.
- La requête ne lit que le sous-ensemble, sans filtre. Sa taille suit le petit ensemble chaud, pas le total de la table.
REMOVEest le levier, pas le vidage. Une chaîne vide est quand même une valeur et reste indexée — tu dois supprimer l'attribut.
Le problème : filtrer n'économise pas de lectures
Venant de SQL, tu supposes qu'une clause WHERE réduit le travail. Le
FilterExpression de DynamoDB ne le fait pas. Il s'exécute après que les items
sont lus, pas avant.
D'après le AWS Developer Guide, filtrer « ne réduit pas la quantité de capacité de lecture consommée » — tu paies pour chaque item examiné, puis tu jettes ceux qui ne correspondent pas.
Donc si 50 de tes 5 millions de tickets sont ouverts, un Query/Scan filtré lit
des millions pour t'en remettre 50.
C'est l'arme à fragmentation derrière chaque fil « pourquoi mon scan est-il si coûteux » ; query vs. scan a le tableau de coûts complet.
Un sparse index la contourne en rendant l'index lui-même petit.
Comment fonctionne la parcimonie
Un index secondaire n'indexe que les items qui ont réellement les attributs de clé de l'index.
La doc AWS sur les global secondary indexes le dit clairement : « un global secondary index ne contient que les items qui ont les attributs de clé définis pour cet index ».
Manque la clé de partition (ou de tri) du GSI sur un item et DynamoDB ne l'écrit tout simplement pas dans l'index. Pas de placeholder, pas de ligne nulle — l'item est absent.
Cette « absence par défaut » est toute l'astuce. N'indexe pas un attribut status
que chaque item porte. Invente un attribut que seuls les items que tu veux
interroger portent.
L'index devient alors une liste nette de ces items précis, et un Query contre lui
ne lit qu'eux — pas de filtre, pas de capacité gaspillée.
Imagine la table de base alimentant l'index, où seuls les items portant la clé passent de l'autre côté :
Seuls les items clés (ouverts) se répliquent vers l'index ; les items fermés n'y entrent jamais.
C'est le même état d'esprit de façonnage des clés que le single-table design : les clés sont des outils que tu construis pour un motif d'accès précis, pas des miroirs fidèles de tes données.
Un exemple travaillé : « les tickets ouverts seulement »
Prends une table de tickets de support. La table de base est clée pour récupérer un ticket par id et lister les tickets d'un client :
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
Sur la durée de vie de la table, la plupart des tickets finissent fermés. Mais la requête de dashboard que tes agents frappent toute la journée est « montre-moi chaque ticket ouvert, du plus ancien au plus récent » — quelques centaines de lignes cachées dans des millions.
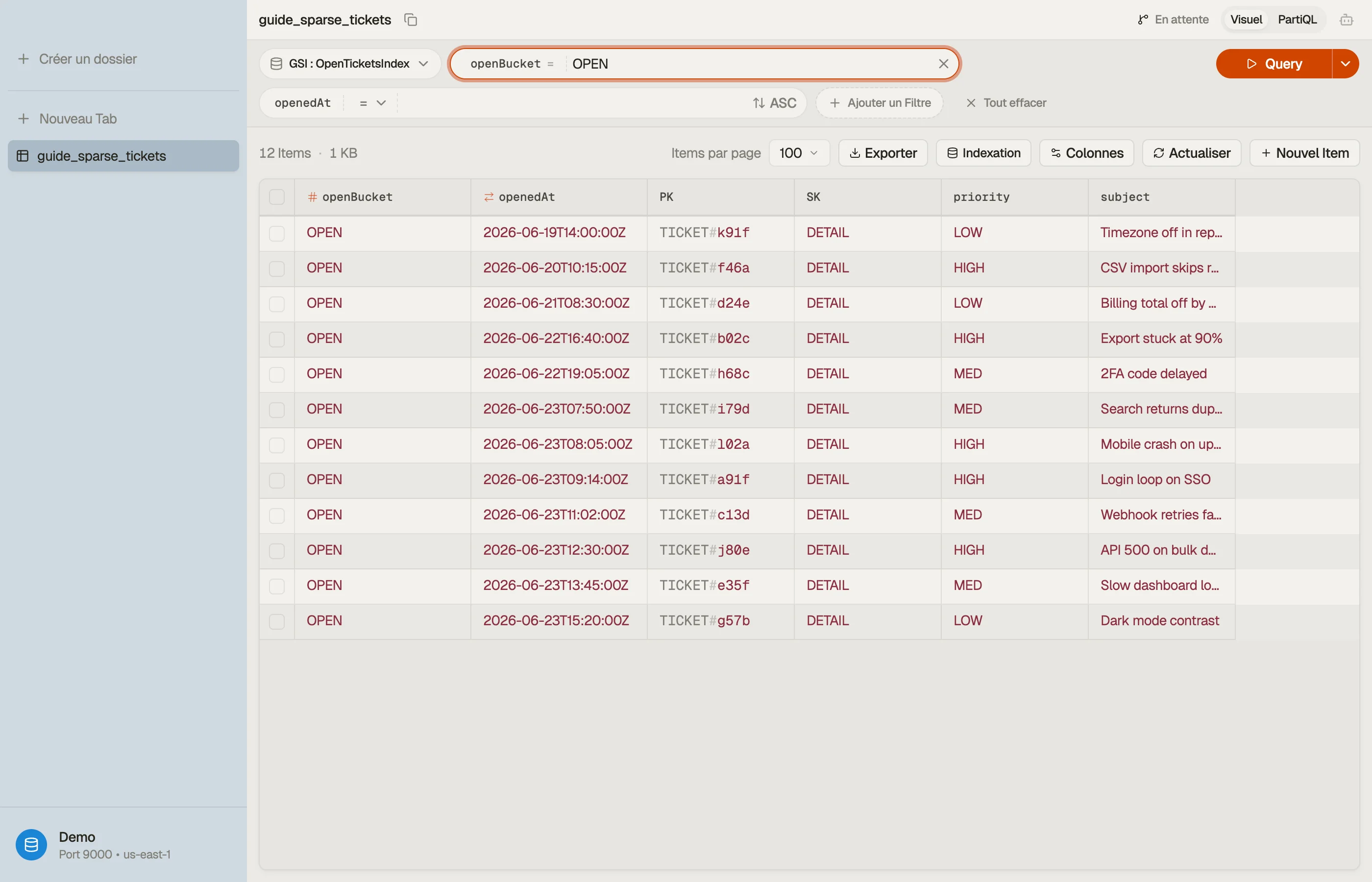
Le coup du sparse index : définis un GSI avec la clé de partition openBucket et la
clé de tri openedAt, et n'écris openBucket que sur les tickets ouverts.
Pose-le à la création du ticket ; fais REMOVE quand le ticket est résolu.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← ouvert : dans l'index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← ouvert : dans l'index |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← fermé : PAS dans l'index |
Les tickets a91f et b02c portent openBucket, donc ils vivent dans le GSI. Le
ticket 77de a été résolu et a eu openBucket retiré, donc il a discrètement
disparu. Le dashboard est maintenant une requête bon marché :
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstÇa ne lit que les tickets ouverts. À mesure que les tickets ferment, l'index rétrécit de lui-même — sa taille suit la population ouverte, jamais le total.
Une seule valeur de partition statique ("OPEN") convient ici précisément parce que
l'ensemble reste petit. Un énorme ensemble ouvert nécessiterait une clé de partition
découpée (sharded), mais l'index « petit sous-ensemble » est exactement l'endroit où
une seule valeur est le bon choix.
La transition qui fait fonctionner le tout est une seule update expression — supprimer l'attribut quand le ticket est résolu.
Prototype cette clause REMOVE et la condition de clé typée pour le côté lecture
dans le DynamoDB Expression Builder, au lieu
d'assembler à la main toi-même les ExpressionAttributeNames et les placeholders
:val.
Fais-le dans DynoTable
Le plus dur dans un sparse index n'est pas la lecture — c'est de voir quels items sont entrés dans l'index et lesquels sont discrètement tombés.
DynoTable te laisse basculer une vue table sur un index secondaire et voir
exactement le sous-ensemble peuplé. Tu peux ainsi confirmer qu'un ticket résolu a
vraiment quitté open-tickets-index au lieu de traîner avec une clé périmée.


Pièges et étapes suivantes
Quelques points à surveiller :
- Retire la clé, ne la vide pas. Une chaîne vide est quand même une valeur, et
DynamoDB indexera un item dont
openBucketvaut"". Pour retirer un item de l'index tu dois faireREMOVEsur l'attribut — le mettre à une valeur falsy le garde dedans. - L'index est à cohérence à terme. Les GSI se mettent à jour de façon asynchrone, donc un ticket tout juste résolu peut brièvement apparaître encore — les lectures de GSI ne supportent que la cohérence à terme. Ne t'y fie pas pour « ce ticket est-il ouvert en ce moment ».
- Attention aux attributs projetés. Un
Querysur l'index ne renvoie que les attributs qui y sont projetés. Si le dashboard a besoin du sujet et de la priorité, projette-les — ou paie unGetItemsupplémentaire pour l'item de base complet. - C'est une force du GSI, pas du LSI. Les local secondary indexes partagent la clé de partition de la table de base et ne peuvent pas exclure sélectivement des items de cette façon. GSI vs. LSI décortique le compromis.
Les sparse indexes sont l'une des plus vieilles idées du modèle. Le papier Amazon Dynamo de 2007 original a bâti le store autour du service à bas coût de motifs d'accès connus et à fort volume.
Un sparse index est exactement ça : façonne les clés pour que la requête courante ne lise rien dont elle n'a pas besoin.
Pour en construire et inspecter un pour de vrai, télécharge DynoTable, pointe-le vers ta table, et bascule la vue données vers ton sparse GSI — regarde le sous-ensemble se mettre à jour à mesure que les items gagnent et perdent la clé de l'index.