Relacionamentos Um-para-Muitos no DynamoDB
Um control plane de SaaS quase sempre tem uma hierarquia de contenção: um
workspace é dono de muitos projetos. No SQL, você colocaria uma chave
estrangeira workspace_id na tabela de projetos e faria um JOIN.
O DynamoDB não tem joins nem chaves estrangeiras, então o relacionamento precisa
viver no esquema de chaves em si. Feito do jeito certo, "carregar um workspace
e todos os projetos dentro dele" vira um único Query em vez de uma leitura mais
um scan de acompanhamento.
Como modelar um relacionamento um-para-muitos no DynamoDB?
Dê ao pai e a todos os seus filhos a mesma chave de partição para que compartilhem uma única coleção de itens e, em seguida, diferencie-os pela chave de classificação. O DynamoDB não tem joins nem chaves estrangeiras, então o relacionamento vive no próprio esquema de chaves. Assim, carregar o pai mais todos os filhos se torna um único Query em vez de um join.
- Modele as leituras, não as entidades. O relacionamento um-para-muitos só existe para servir "listar os projetos de um workspace" — molde as chaves em torno dessa consulta.
- Codifique o pai na chave de partição do filho. Dê ao workspace e a todos os seus projetos o mesmo valor de chave de partição para que caiam em uma única coleção de itens.
- Aí a leitura da lista é um único
Query. O pai mais um número arbitrário de filhos voltam em uma única chamada cobrada — sem join, sem segunda ida e volta. - Cuidado com a partição quente. Um único tenant gigante concentra todo o seu tráfego em uma partição; um workspace enorme pode precisar de uma chave fragmentada e uma leitura em fan-out.
O padrão de acesso, primeiro
A modelagem no DynamoDB é orientada a padrões de acesso, não a entidades — a mesma disciplina por trás do single-table design. Antes de escolher qualquer chave, anote as leituras que o app realmente faz:
- Obter as configurações de um workspace.
- Listar todos os projetos de um workspace, do mais novo ao mais antigo.
- Obter um projeto específico por id.
O relacionamento "um workspace, muitos projetos" só importa por causa da leitura #2. Se você nunca precisasse listar os projetos de um workspace juntos, não modelaria o relacionamento de jeito nenhum — você armazenaria os projetos de forma independente.
Então a pergunta nunca é "como represento um-para-muitos?" no abstrato. É "quais consultas esse relacionamento precisa servir?" Responda isso e depois molde as chaves em torno disso.
Por que uma chave estrangeira não ajuda aqui
No DynamoDB, todo GetItem e Query mira uma chave de partição, e o serviço
faz o hash dessa chave para localizar a partição que contém o item.
A AWS diz isso diretamente na documentação de Componentes principais: o valor da chave de partição é a entrada de uma função de hash interna que decide onde os dados ficam.
Esse posicionamento baseado em hash é a herança do artigo original de 2007 Dynamo: Amazon's Highly Available Key-value Store, em que o hashing consistente distribui chaves entre os nós.
Um mero atributo workspace_id em um item de projeto é invisível para esse
maquinário — o DynamoDB não consegue "seguir" esse atributo.
Para buscar itens relacionados em uma única requisição, a identidade do pai precisa
estar codificada na chave de partição do projeto, para que todos os itens de um
workspace façam hash para a mesma partição e um único Query possa varrê-los.
Exemplo prático: workspaces e projetos
Use um esquema de chaves genérico e sobrecarregado. Chame a chave de partição de
EntityRef e a chave de ordenação de Detail. A identidade do workspace vai para
EntityRef tanto no item do workspace quanto em cada projeto sob ele:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
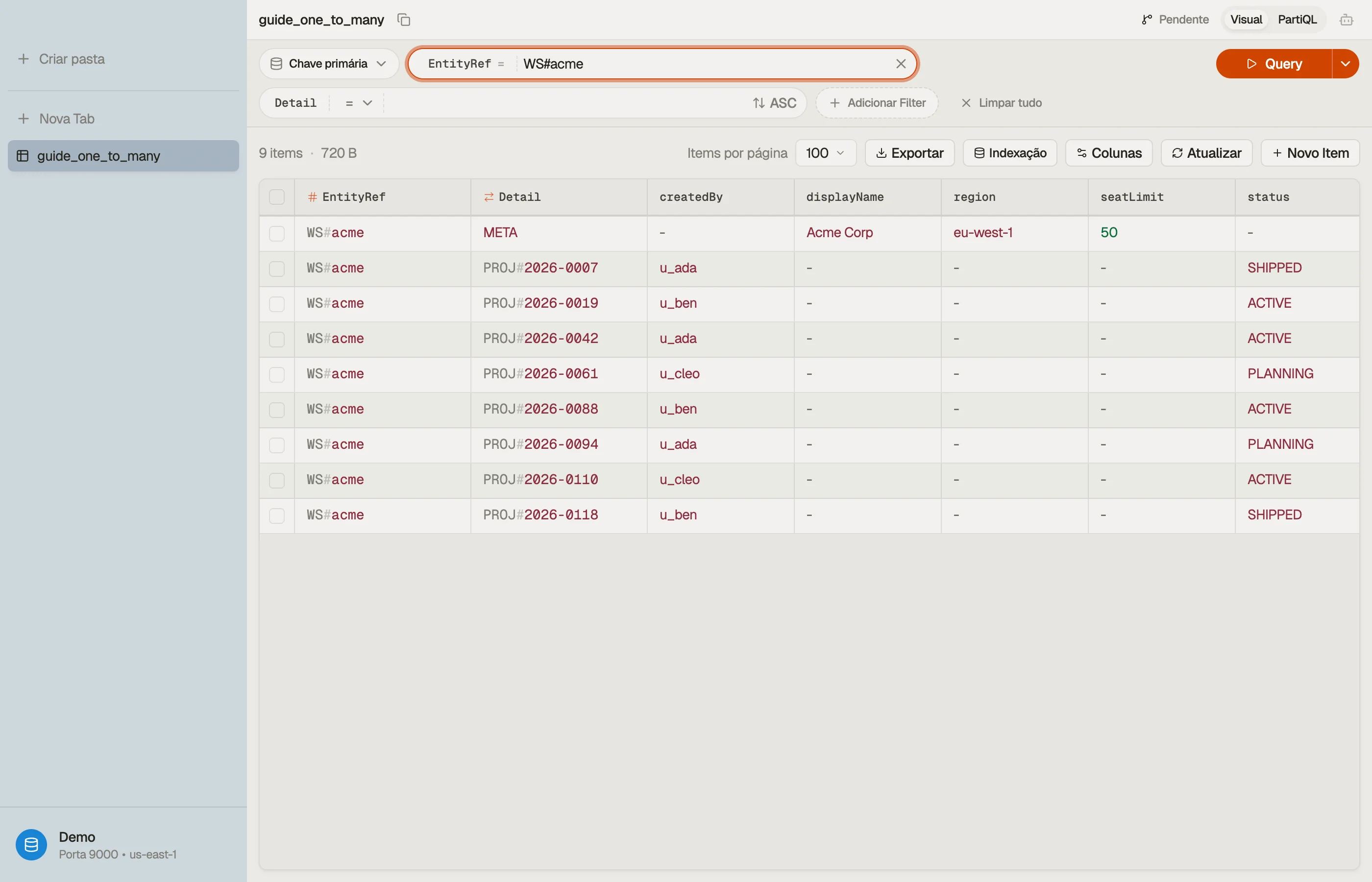
O workspace e todos os seus projetos compartilham EntityRef = "WS#acme", então
formam uma única coleção de itens vivendo juntos em uma partição.
A chave de ordenação Detail os separa: META é o registro do workspace, e cada
projeto carrega um prefixo PROJ# com um id ordenado por tempo e preenchido com
zeros, de modo que os projetos se ordenam naturalmente.
Visualmente, o pai e seus filhos se empilham dentro de uma partição, ordenados pela chave de ordenação:
Um único Query em EntityRef = "WS#acme" varre a pilha inteira — pai mais todos
os filhos — em uma única leitura.
Agora os três padrões de acesso cada um colapsa em uma chamada:
- Configurações do workspace —
GetItem(EntityRef="WS#acme", Detail="META"). - Listar projetos do mais novo ao mais antigo —
Query(EntityRef="WS#acme")comDetail begins_with "PROJ#", executado em ordem decrescente (ScanIndexForward = false). - Um projeto —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
A segunda é o ponto principal: o pai e um número arbitrário de filhos voltam em
um Query cobrado, sem join e sem segunda ida e volta. É a jogada que você não
consegue fazer com um atributo de chave estrangeira e um Scan.
Escrever aquela condição begins_with à mão é trabalhoso — a sintaxe de
key-condition e projection-expression morde.
O DynamoDB Expression Builder gera a
KeyConditionExpression, os mapas de placeholders #name/:value e um snippet de
SDK pronto para rodar, para você não brigar com a gramática:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Inspecione a coleção de itens no DynoTable
O ganho desse layout é visual: cada linha que compartilha um EntityRef é o
workspace mais seus filhos, lado a lado.
O DynoTable os agrupa para que você veja o relacionamento um-para-muitos como um bloco contíguo, em vez de adivinhá-lo espalhado por tabelas separadas.


Armadilhas e a forma alternativa
Algumas coisas para observar:
- Partições quentes. Todo item de um workspace vive em uma partição, então um
único tenant muito grande ou muito ocupado concentra tráfego. O comportamento de
capacidade adaptativa
que a AWS descreve absorve uma assimetria moderada, mas um workspace com milhões
de projetos pode precisar de uma chave fragmentada (ex.:
WS#acme#01 … #10) e uma leitura em fan-out. - Tamanho da coleção de itens. Com um índice secundário local, a coleção de itens de uma única partição é limitada a 10 GB; sem um LSI não há esse limite. Se você está pesando os tipos de índice aqui, veja GSI vs LSI.
- Recorra a
Query, nunca aScan. Todo o design existe para que você possaQueryem uma partição. Recorrer a umScanfiltrado para "achar os projetos de um workspace" joga o modelo fora e lê a tabela inteira — a armadilha coberta em Query vs Scan.
Se você realmente precisa listar projetos entre workspaces (digamos, todos os
projetos status = ACTIVE globalmente), a tabela base não consegue responder isso —
sua chave de partição tem escopo de workspace.
Esse é um trabalho para um índice secundário que reparticiona os projetos por um atributo diferente, não para remodelar esse relacionamento.
Próximos passos
Modele os padrões de acesso, codifique o pai na chave de partição do filho, e a
leitura um-para-muitos é um único Query. Construa e valide a condição de chave com
o DynamoDB Expression Builder.
Depois baixe o DynoTable para carregar esse esquema, navegar pela coleção de itens workspace → projetos ao vivo e confirmar que cada consulta faz exatamente uma leitura.