Operações em Lote no DynamoDB: BatchGetItem & BatchWriteItem
Quando você precisa ler ou escrever muitos itens de uma vez, disparar um GetItem ou
PutItem por item significa uma ida e volta de rede por item — lento e tagarela. As
APIs de lote do DynamoDB dobram muitas operações de item em uma única requisição:
BatchGetItem para leituras, BatchWriteItem para escritas.
Elas são um ganho de throughput e latência, não uma garantia de consistência — e essa distinção é onde as pessoas se queimam. Um batch não é uma transação.
O que são operações em lote no DynamoDB?
As operações em lote do DynamoDB dobram muitas leituras ou escritas de itens em uma única requisição: o BatchGetItem busca até 100 itens, o BatchWriteItem insere ou exclui até 25, cada um limitado a 16 MB. Elas economizam idas e voltas, não capacidade. O ponto crítico: um batch não é uma transação — os itens têm sucesso ou falham de forma independente, sem rollback.
BatchGetItem— busca até 100 itens (ou 16 MB) em uma ou mais tabelas em uma chamada.BatchWriteItem— até 25 operações de put/delete (ou 16 MB) em uma chamada. Sem updates — apenas puts e deletes.- Não atômico. Itens individuais podem ter sucesso enquanto outros falham. Não há rollback.
- Falha parcial é normal. Itens com throttling voltam em
UnprocessedItems/UnprocessedKeys— você precisa tentar de novo por conta própria, com backoff. - Mesmo custo de capacidade das chamadas individuais — agrupar economiza idas e voltas, não unidades de capacidade.
O problema: muitos itens, uma ida e volta
Digamos que você opere um balcão de suporte. Um dashboard precisa carregar 50 tickets por ID para renderizar uma fila; um job noturno arquiva 1.000 tickets resolvidos. Fazer isso um item por vez são 50 (ou 1.000) idas e voltas sequenciais — a latência se acumula e o job se arrasta.
Agrupar colapsa isso em um punhado de chamadas. A leitura de 50 tickets vira um único
BatchGetItem; o job de arquivamento vira um fluxo de chamadas BatchWriteItem de 25
deletes cada. Bem menos idas e voltas, os mesmos dados movidos.
Como as APIs de lote funcionam
O BatchGetItem recebe um conjunto de chaves primárias (em uma ou mais tabelas) e
retorna os itens correspondentes. Você pode solicitar leituras fortemente consistentes
por tabela. Qualquer coisa que ele não conseguiu ler — geralmente porque a requisição
roçou um limite de throughput — volta em UnprocessedKeys em vez de falhar a
chamada inteira.
O BatchWriteItem recebe uma lista de operações PutRequest / DeleteRequest.
Note o que está faltando: não há update. Uma escrita em lote ou substitui um item
inteiro (put) ou o remove (delete) — para modificar atributos específicos você ainda
precisa de UpdateItem. Os itens que ele não conseguiu escrever voltam em
UnprocessedItems.
O modelo mental chave: um batch é um pacote de operações independentes, cada uma tendo sucesso ou falhando por conta própria — não uma unidade tudo-ou-nada.
Batches não são transações
Essa é a cilada. Se o batch do seu job de arquivamento bate em um limite de throughput na metade, alguns tickets são deletados e outros não — e o DynamoDB não desfaz os que passaram. Não há rollback, sem isolamento, sem "todos os 25 ou nenhum".
Se você precisa de semântica tudo-ou-nada — "mova o ticket para arquivado e
decremente o contador de tickets abertos, ou não faça nenhum dos dois" — isso é
TransactWriteItems, não um batch. Transações custam
mais (cada operação é cobrada em dobro) e limitam em 100 itens, mas te dão a atomicidade
que os batches deliberadamente não entregam.
Lidando com itens não processados
Um chamador de batch correto sempre verifica o conjunto não processado e tenta de
novo. O DynamoDB retorna UnprocessedItems/UnprocessedKeys sempre que a requisição
como um todo foi aceita mas alguns itens não puderam ser servidos — tipicamente
throttling transitório.
Reenvie apenas os itens não processados, com backoff exponencial e jitter. Tratar um batch como fire-and-forget silenciosamente descarta escritas — o tipo de bug que aparece meses depois como dados faltando.
Escritas em lote no DynoTable
Estime primeiro quanto um job em massa vai custar com a calculadora de preços do DynamoDB — um batch consome a mesma capacidade que as escritas individuais que ele agrupa, só em menos requisições.
No DynoTable, você prepara suas edições localmente e as revisa antes de commitá-las como escritas em lote eficientes — mudanças em massa por muitas linhas saem em requisições agrupadas em vez de uma chamada de API por mudança, com a tentativa-de-novo de itens não processados tratada para você.

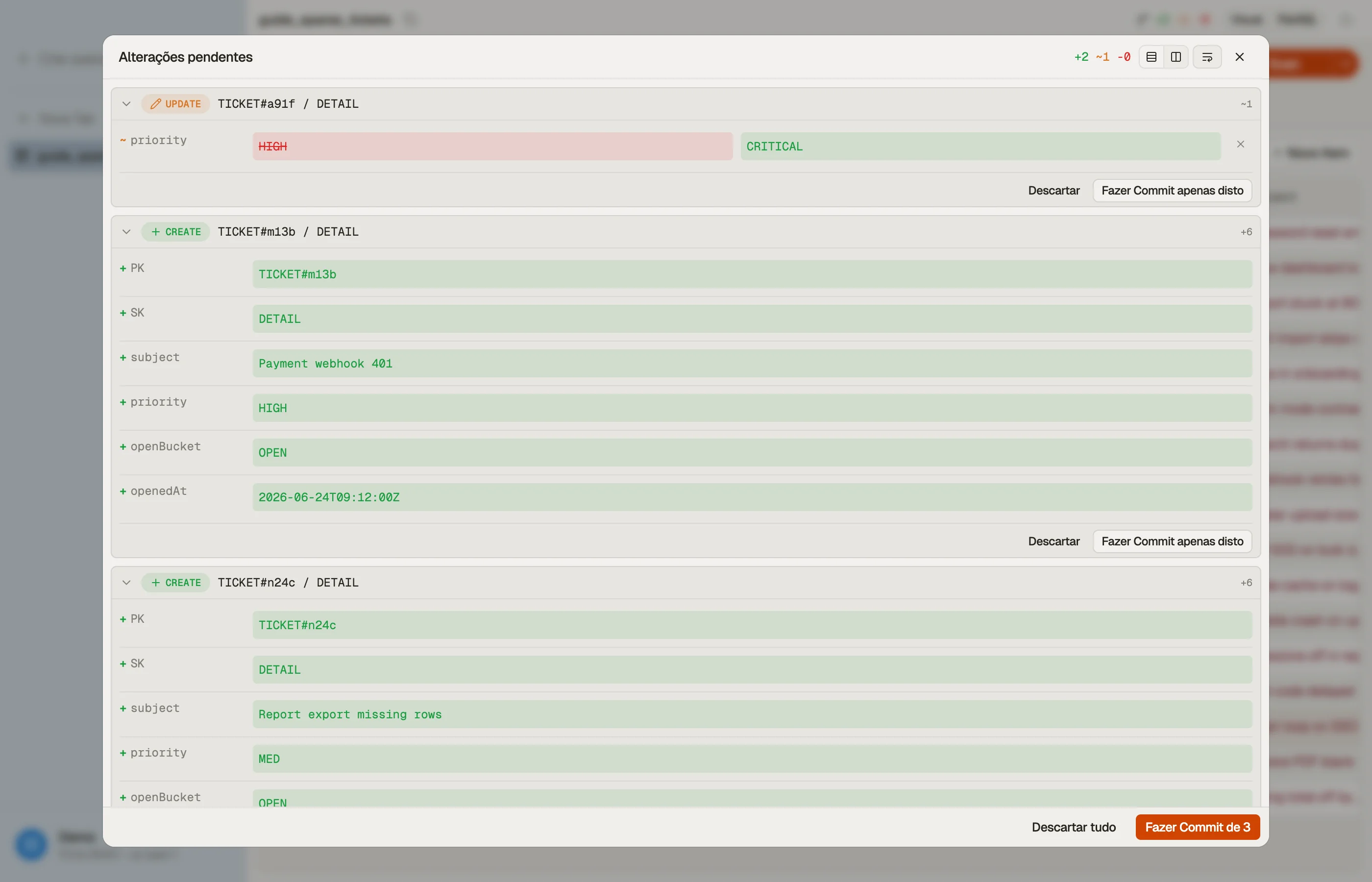

Armadilhas e próximos passos
- Sempre tente de novo
UnprocessedItems/UnprocessedKeyscom backoff — eles são esperados, não excepcionais. - Sem rollback de falha parcial. Precisa de atomicidade? Use transações.
- Sem updates em uma escrita em lote —
BatchWriteItemé só put/delete; recorra aUpdateItempara mudar atributos. - Atenção aos limites por chamada — 25 escritas / 100 leituras / 16 MB. Pagine jobs maiores; veja paginação.
Quer rodar leituras e escritas em massa sem programar o loop de tentativa-de-novo? Baixe o DynoTable e edite suas tabelas diretamente.