Índices Esparsos no DynamoDB
Um índice esparso é um índice secundário que contém só os itens que carregam seu atributo de chave — então um subconjunto pequeno e quente de uma tabela enorme vira sua própria coleção pré-filtrada e pronta para consultar.
Você tem milhões de linhas, mas a consulta que você roda o dia todo toca uma fatia minúscula: os tickets de suporte abertos, as faturas não pagas, as contas marcadas para revisão.
Filtrar essa fatia ainda escaneia a tabela inteira e te cobra por cada leitura. Um índice esparso torna o próprio índice pequeno.
O que é um índice esparso no DynamoDB?
Um índice esparso é um índice secundário que contém apenas os itens que carregam seu atributo de chave. Como o DynamoDB ignora qualquer item sem essa chave, você inventa uma chave que só os itens desejados escrevem — tickets abertos, faturas não pagas — e o índice se torna exatamente esse subconjunto. As consultas então leem só ele, sem filtro, sem capacidade de leitura desperdiçada.
- Um índice secundário só indexa itens que têm sua chave. Omita a chave em um item e ele nunca entra no índice — sem placeholder, sem linha nula.
- Então você inventa uma chave que só os itens desejados carregam. Escreva-a nos itens que você consulta, remova-a no resto. O índice se torna exatamente esse subconjunto.
- A consulta lê só o subconjunto, sem filtro. Seu tamanho acompanha o conjunto quente pequeno, não o total da tabela.
REMOVEé a alavanca, não esvaziar. Uma string vazia ainda é um valor e ainda é indexada — você precisa deletar o atributo.
O problema: filtrar não economiza leituras
Vindo do SQL, você assume que uma cláusula WHERE estreita o trabalho. A
FilterExpression do DynamoDB não faz isso. Ela roda depois que os itens são
lidos, não antes.
Conforme o AWS Developer Guide, filtrar "não reduz a quantidade de capacidade de leitura consumida" — você paga por cada item examinado e depois joga fora os que não correspondem.
Então se 50 dos seus 5 milhões de tickets estão abertos, um Query/Scan filtrado lê
milhões para te entregar esses 50.
Essa é a cilada por trás de todo tópico "por que meu scan é tão caro"; query vs. scan tem o quadro completo de custo.
Um índice esparso a contorna tornando o próprio índice pequeno.
Como a esparsidade funciona
Um índice secundário só indexa itens que de fato têm os atributos de chave do índice.
A documentação da AWS sobre índices secundários globais diz claramente: "um índice secundário global contém apenas itens que têm os atributos de chave definidos para esse índice".
Falte a chave de partição (ou de ordenação) do GSI em um item e o DynamoDB simplesmente não o escreve no índice. Sem placeholder, sem linha nula — o item está ausente.
Essa "ausência por padrão" é o truque inteiro. Não indexe um atributo status que
todo item carrega. Invente um atributo que só os itens que você quer consultar
carregam.
O índice então se torna uma lista limpa de exatamente esses itens, e um Query contra
ele lê só eles — sem filtro, sem capacidade desperdiçada.
Imagine a tabela base alimentando o índice, onde só os itens que carregam a chave atravessam:
Só os itens com chave (abertos) replicam para o índice; itens fechados nunca entram nele.
Essa é a mesma mentalidade de modelagem de chaves do single-table design: chaves são ferramentas que você constrói para um padrão de acesso específico, não espelhos fiéis dos seus dados.
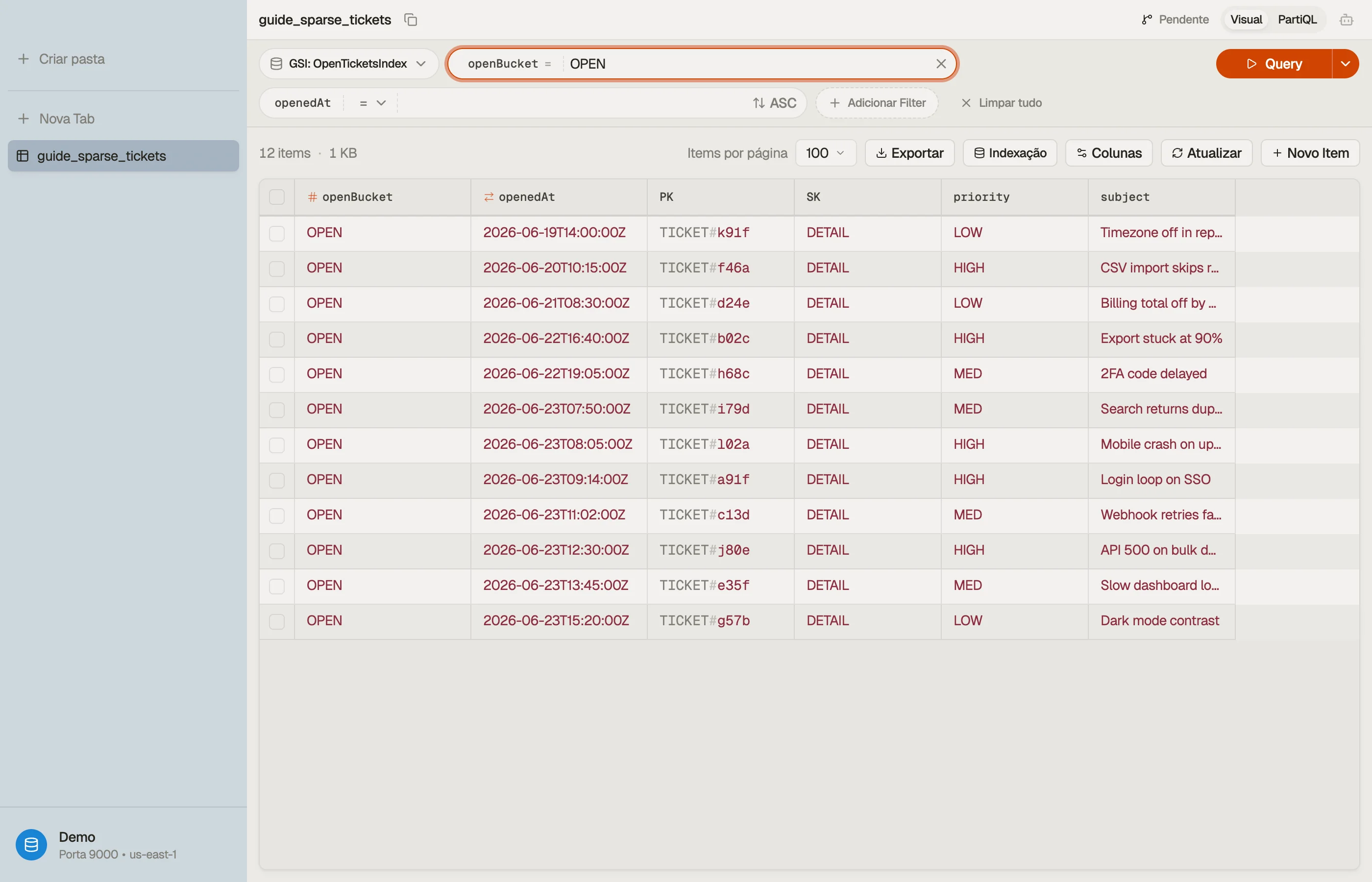
Um exemplo prático: "só tickets abertos"
Pegue uma tabela de tickets de suporte. A tabela base é chaveada para buscar um ticket por id e listar os tickets de um cliente:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
Ao longo da vida da tabela, a maioria dos tickets acaba fechada. Mas a consulta de dashboard que seus agentes batem o dia todo é "me mostre todo ticket aberto, do mais antigo primeiro" — algumas centenas de linhas escondidas dentro de milhões.
A jogada do índice esparso: defina um GSI com chave de partição openBucket e chave de
ordenação openedAt, e só escreva openBucket em tickets abertos. Defina-o quando
o ticket é criado; faça REMOVE quando o ticket é resolvido.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← open: in the index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← open: in the index |
| TICKET#77de | DETAIL | (absent) | 2026-05-30T11:02:00Z | ← closed: NOT in the index |
Os tickets a91f e b02c carregam openBucket, então vivem no GSI. O ticket 77de
foi resolvido e teve openBucket removido, então saiu silenciosamente. O dashboard
agora é uma consulta barata:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstIsso lê só os tickets abertos. Conforme os tickets fecham, o índice encolhe sozinho — seu tamanho acompanha a população aberta, nunca o total.
Um único valor estático de partição ("OPEN") está bem aqui precisamente porque o
conjunto permanece pequeno. Um conjunto aberto enorme precisaria de uma chave de
partição fragmentada, mas o índice de "subconjunto pequeno" é exatamente onde um valor
é a escolha certa.
A transição que faz funcionar é uma única update expression — removendo o atributo quando o ticket é resolvido.
Prototipe essa cláusula REMOVE e a condição de chave tipada para o lado da leitura no
DynamoDB Expression Builder, em vez de montar à
mão os ExpressionAttributeNames e os placeholders :val você mesmo.
Faça no DynoTable
A parte difícil de um índice esparso não é a leitura — é ver quais itens entraram no índice versus quais saíram silenciosamente.
O DynoTable te deixa trocar uma visão de tabela para um índice secundário e ver
exatamente o subconjunto populado. Assim você pode confirmar que um ticket resolvido
realmente saiu de open-tickets-index em vez de permanecer com uma chave obsoleta.


Armadilhas e próximos passos
Algumas coisas para observar:
- Remova a chave, não a esvazie. Uma string vazia ainda é um valor, e o DynamoDB
vai indexar um item cujo
openBucketé"". Para tirar um item do índice você precisa fazerREMOVEno atributo — defini-lo como um valor falsy o mantém dentro. - O índice é eventualmente consistente. GSIs atualizam de forma assíncrona, então um ticket recém-resolvido pode brevemente ainda aparecer — leituras de GSI suportam apenas consistência eventual. Não confie nele para "este ticket está aberto agora mesmo".
- Atente para atributos projetados. Um
Queryno índice retorna só os atributos projetados nele. Se o dashboard precisa de subject e priority, projete-os — ou pague umGetItemextra pelo item base completo. - Isso é uma força do GSI, não do LSI. Índices secundários locais compartilham a chave de partição da tabela base e não conseguem descartar itens seletivamente desse jeito. GSI vs. LSI destrincha o trade-off.
Índices esparsos são uma das ideias mais antigas do modelo. O artigo Dynamo original da Amazon de 2007 construiu o armazenamento em torno de servir padrões de acesso conhecidos e de alto volume de forma barata.
Um índice esparso é exatamente isso: molde as chaves para que a consulta comum não leia nada de que não precisa.
Para construir e inspecionar um de verdade, baixe o DynoTable, aponte-o para sua tabela, e troque a visão de dados para o seu GSI esparso — veja o subconjunto atualizar conforme os itens ganham e perdem a chave do índice.