Como Modelar Dados no DynamoDB
No SQL você modela entidades e relacionamentos primeiro, depois confia no query planner para montar o que você pedir mais tarde. O DynamoDB inverte isso. Você modela as leituras que já sabe que fará, e as chaves existem para servi-las.
Não há motor de join nem planner escolhendo uma estratégia em tempo de execução. Um Query lê uma partição ao longo de uma chave, e esse é todo o contrato de desempenho. Então você projeta chaves para padrões de acesso conhecidos, não para um esquema arrumadinho.
A AWS diz claramente no seu guia de boas práticas: "você não deveria começar a projetar seu esquema até saber as perguntas que ele precisará responder".
Este guia percorre o processo inteiro em um domínio: um placar de jogo multiplayer acompanhando jogadores, as partidas que eles jogam e seu ranking por temporada. Vamos de uma lista de perguntas a um esquema de chaves funcional.
Como modelar dados no DynamoDB?
Modele as leituras primeiro, não as tabelas. Liste cada consulta que o app faz, depois projete uma e uma para que cada pergunta resolva para um único Query ou GetItem. Co-localize itens que são lidos juntos, use o valor da chave de ordenação para intervalos e adicione um GSI para qualquer padrão de acesso que a tabela base não consiga atender.
- Liste as leituras primeiro, não as tabelas. As perguntas são a especificação; os substantivos são uma distração.
- Cada pergunta deve ser um
QueryouGetItem. Se uma pergunta precisa de umScan, o modelo está errado. - Itens co-localizados compartilham uma chave de partição; qualquer coisa sobre a qual você faz intervalo vai na chave de ordenação.
- Uma pergunta que a tabela base não consegue responder ganha um GSI — nunca um
Scancom filtro.
Passo 1 — Enquadre o problema como perguntas, não tabelas
Resista ao impulso de desenhar tabelas players, matches e scores. Esse instinto é o hábito do SQL, e aqui ele está errado. Em vez disso, anote toda leitura que o app de fato realiza. Para o nosso placar:
- Buscar o perfil de um jogador por id.
- Listar as partidas recentes de um jogador, da mais nova primeiro.
- Mostrar os N melhores jogadores de uma dada temporada, ranqueados por rating.
- Buscar um jogador pelo seu handle público (ex.: para uma URL de perfil).
Essas quatro perguntas — não os substantivos — são a especificação. Cada uma deve resolver para um único Query (ou GetItem), porque essa é a única forma de acesso que o DynamoDB serve barato em escala.
Se uma pergunta só puder ser respondida escaneando a tabela, o modelo está errado, e você vai sentir isso em latência e custo — veja Query vs Scan para entender por que um Scan é a cilada a evitar.
O método inteiro é um pipeline curto e ordenado que você roda uma vez por domínio:
Cada passo abaixo mapeia para uma caixa: listar, enumerar, projetar chaves, adicionar índices para o resto, depois validar.
Passo 2 — Entenda as primitivas com que você está modelando
Uma tabela tem uma chave de partição (PK) que escolhe em qual partição física um item vive, e uma chave de ordenação (SK) opcional que ordena os itens dentro dessa partição.
A documentação de componentes principais da AWS chama o par de chave primária do item. Um Query sempre mira exatamente um valor de PK e pode fazer range-scan ou filtrar a SK — esse é todo o kit de ferramentas.
Esse design de partição única é o que deixa o DynamoDB entregar as leituras previsíveis, de baixa latência e horizontalmente particionadas descritas pela primeira vez no artigo Dynamo da Amazon de 2007.
Duas consequências guiam toda decisão abaixo:
- Itens lidos juntos devem compartilhar uma chave de partição para que um
Queryos retorne em uma única requisição cobrada. - Qualquer coisa sobre a qual você quer fazer intervalo (partidas recentes, melhores ratings) deve viver na chave de ordenação, porque esse é o único atributo que o
Queryconsegue ordenar e limitar.
Quando uma pergunta precisa de uma forma de acesso diferente da que a tabela base oferece, você adiciona um Índice Secundário Global — uma reprojeção da tabela sob uma PK/SK diferente.
(Para GSI versus Índice Secundário Local, veja GSI vs LSI.)
Passo 3 — Projete as chaves, uma pergunta de cada vez
Usamos uma única tabela com atributos de chave genéricos e sobrecarregados — a abordagem single-table — porque um jogador e suas partidas são lidos juntos.
Invente seus próprios prefixos; aqui PLAYER#, MATCH# e SEASON# marcam o tipo de entidade dentro de chaves de resto genéricas.
As perguntas 1 e 2 (perfil + partidas recentes) compartilham uma partição, então as duas pendem da mesma PK:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" retorna o perfil e cada partida em uma leitura. Para só o perfil, GetItem.
Para partidas recentes, rangeId begins_with "MATCH#" com ScanIndexForward = false as percorre da mais nova primeiro — o timestamp na chave de ordenação faz a ordenação de graça.
As perguntas 3 e 4 não podem ser respondidas a partir daquela partição — elas pivotam no rank da temporada e no handle, nenhum dos quais é a PK base. Cada uma ganha um GSI.
Adicionamos dois atributos de índice genéricos, gsiPartition / gsiSort, e deixamos cada item populá-los com o que aquele índice precisar:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Agora Query no índice de temporada WHERE gsiPartition = "SEASON#2026-Q2" com ScanIndexForward = false retorna os jogadores ranqueados por rating — esse é o placar.
Um segundo índice chaveado em HANDLE#… resolve um handle público para um id de jogador em uma leitura. Uma tabela física, quatro padrões de acesso de Query único.
Uma nota sobre preenchimento com zeros em
RATING#1842: o DynamoDB ordena chaves de ordenação lexicograficamente, não numericamente, então um rating deve ser preenchido com zeros até uma largura fixa (RATING#01842) ou9ordenaria depois de1000. Essa é uma cilada clássica de modelagem que vale acertar de cara.
Passo 4 — Valide o modelo no DynoTable
Um esquema de chaves só ganha confiança quando você vê um Query real retornar exatamente os itens que você esperava e nada mais.
Abra a tabela no DynoTable, rode a consulta do placar contra o índice de temporada, e confirme que a partição volta ranqueada e limitada — sem Scan, sem ordenação no lado do cliente.

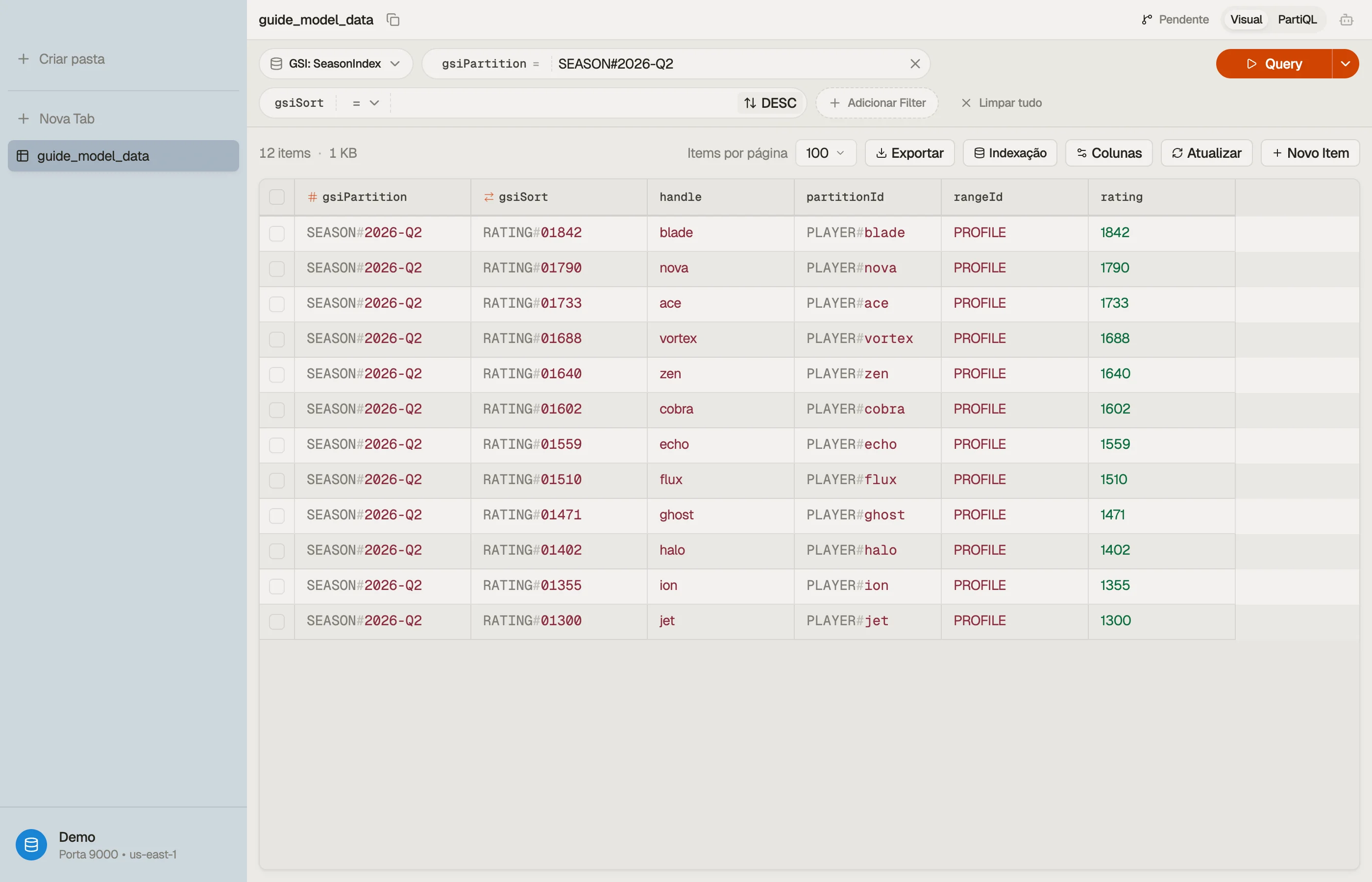

Quando você constrói as expressões de condição para essas consultas — o begins_with, o gsiPartition = :p, o binding do placeholder :p — deixe o DynamoDB Expression Builder fazer isso.
Ele gera a KeyConditionExpression, os ExpressionAttributeNames e os ExpressionAttributeValues, para que uma palavra reservada como result ou um placeholder com erro de digitação nunca quebre uma leitura silenciosamente.
Passo 5 — Armadilhas e próximos passos
Algumas ciladas para checar antes de entregar o modelo:
- Não modele relacionamentos que você nunca lê juntos. Um GSI por pergunta é barato; um GSI desperdiçado é custo recorrente. Adicione índices a partir da lista de perguntas, não especulativamente.
- Observe o calor da partição. Se uma PK (um jogador celebridade, uma única temporada quente) absorve a maior parte do tráfego, essa partição pode sofrer throttling. Espalhe escritas com um shard de sufixo quando uma chave é comprovadamente quente — a AWS cobre isso em partition-key design.
- Preencha com zeros e use ISO-8601 em tudo que for numérico ou temporal em uma chave de ordenação, para que a ordenação lexicográfica corresponda à ordem que você quer.
- Uma nova pergunta = uma nova chave ou índice, nunca um
Scan. Quando um padrão de acesso genuinamente novo aparecer mais tarde, estenda as chaves; não disfarce com um filtro.
Modele as perguntas primeiro, projete chaves para que cada uma seja um único Query, depois prove isso.
Experimente o DynoTable para navegar pela sua tabela, rodar essas consultas contra a tabela base e os GSIs lado a lado, e ver os padrões de acesso que você projetou retornarem exatamente o que você planejou.