Chaves de Classificação com Zero-Padding no DynamoDB
Uma chave de classificação de string no DynamoDB ordena lexicograficamente — um
caractere por vez, da esquerda para a direita — não numericamente. Então "10" cai
antes de "2", porque "1" vem antes de "2". Fazer zero-padding até uma largura
fixa é como você faz a ordem de string corresponder à ordem numérica.
Por que "10" ordena antes de "2" em uma chave de classificação do DynamoDB?
Porque uma chave de classificação de string no DynamoDB é comparada lexicograficamente pela ordem de bytes UTF-8, não numericamente. O byte de "1" precede "2", então "10" cai antes de "2". Preencha cada número até uma largura fixa com zeros à esquerda — "2" vira "0000000002" — e a ordem de string passa a corresponder exatamente à ordem numérica.
- A cilada: números armazenados como strings ordenam como palavras.
"100","11","2"é a ordem que o DynamoDB te dá — não o que você quis dizer. - A correção: preencha cada número até uma largura fixa com zeros à esquerda, para
que
"2"vire"0000000002". Agora a ordem lexicográfica e a numérica concordam. - Escolha uma largura uma vez: dimensione-a para o maior valor que você jamais armazenará, depois adicione alguns dígitos. Mudar a largura depois significa reescrever toda chave.
- Descendente de graça: para ordenar do maior para o menor (o caso do leaderboard),
armazene
maxValue - value, também com zero-padding — o DynamoDB não tem direção de classificação por atributo.
Por que chaves de classificação de string te traem
Vindo do SQL, um ORDER BY score DESC sobre uma coluna inteira "simplesmente funciona"
— o engine sabe que a coluna é numérica. O DynamoDB não tem esse luxo para uma chave de
classificação que não seja do tipo Number.
O DynamoDB compara chaves de classificação de string (S) por ordem de bytes
UTF-8, conforme a
documentação de chave de classificação da AWS.
Bytes, não magnitude. "9" (0x39) supera "10" porque seu primeiro byte ganha de
"1" (0x31). O comprimento é irrelevante — só o primeiro byte diferente decide.
Essa é a cilada: no momento em que um número vive dentro de uma chave de classificação
de string, todo Query que percorre o intervalo retorna linhas em uma ordem que parece
embaralhada.
Construa uma chave de classificação de leaderboard
Pegue um leaderboard de arcade sazonal. Uma coleção de itens por temporada contém a corrida de cada jogador, e você quer os melhores scores primeiro.
Modele-o com uma chave composta em uma única coleção de itens:
leaderboardId(chave de partição) — ex.:SEASON#2026-SPRING.rankKey(chave de classificação) — o score com zero-padding mais um critério de desempate.
Uma primeira tentativa ingênua armazena o score cru como string:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "9" | quickdraw |
| SEASON#2026-SPRING | "10" | ace_pilot |
| SEASON#2026-SPRING | "1500" | nightowl |
| SEASON#2026-SPRING | "240" | bytecrash |
Um Query em SEASON#2026-SPRING os retorna nesta ordem de bytes:
"10", "1500", "240", "9". A corrida de 9 pontos fica em último e a de 1500
pontos está enterrada no meio. Inútil para um leaderboard.
Preencha até uma largura fixa
Escolha uma largura ampla o suficiente para o maior score que você jamais registrará, depois preencha à esquerda com zeros. Digamos que os scores cheguem a dez milhões — são oito dígitos, então use dez dígitos por folga:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "0000000009" | quickdraw |
| SEASON#2026-SPRING | "0000000010" | ace_pilot |
| SEASON#2026-SPRING | "0000000240" | bytecrash |
| SEASON#2026-SPRING | "0000001500" | nightowl |
Agora toda chave tem o mesmo comprimento, então a comparação byte a byte e a comparação
numérica produzem a ordem idêntica. Um Query ascendente dá 9, 10, 240, 1500. A
matemática finalmente corresponde aos bytes.
A largura é uma porta de mão única. Se você preenche até dez dígitos e um score depois
excede isso, um valor de 11 dígitos ordena antes de um de 10 dígitos — quebrando tudo
de novo — e consertar isso significa reescrever toda rankKey existente.
Superprovisione a largura; o custo é um punhado de bytes.
Ordenar descendente: armazene a diferença
Um leaderboard quer o score mais alto primeiro. O DynamoDB pode ler uma chave de
classificação para frente ou para trás com ScanIndexForward: false, então descendente
geralmente é uma flag em tempo de leitura — busque-a primeiro.
Mas quando uma coleção de itens precisa servir direções de classificação mistas, ou
você quer o melhor score fisicamente primeiro independentemente das flags de leitura,
inverta o próprio número. Armazene maxValue - score, com zero-padding na mesma
largura:
score inverted (9999999999 - score) rankKey
1500 9999998499 "9999998499"
240 9999999759 "9999999759"
10 9999999989 "9999999989"
9 9999999990 "9999999990"A ordem de bytes ascendente sobre o valor invertido agora produz os scores originais do
maior para o menor: 1500, 240, 10, 9. O truque está no espírito do
paper Amazon Dynamo de 2007
— chaves são bytes opacos, então você codifica a intenção dentro dos bytes.
Adicione um critério de desempate
Dois jogadores podem empatar. Um score preenchido sozinho colide na chave de classificação, e uma segunda escrita sobrescreveria a primeira (mesma PK + SK). Acrescente um sufixo único para que cada corrida seja um item distinto e os empates se resolvam deterministicamente:
rankKey = "<paddedScore>#<paddedTimestamp>#<playerId>"Por exemplo "0000001500#0000001719100800#p_8842". Mesmo score, timestamp mais cedo
ganha o slot mais alto — preencha o timestamp também, ou ele reintroduz exatamente o
bug que você acabou de consertar.
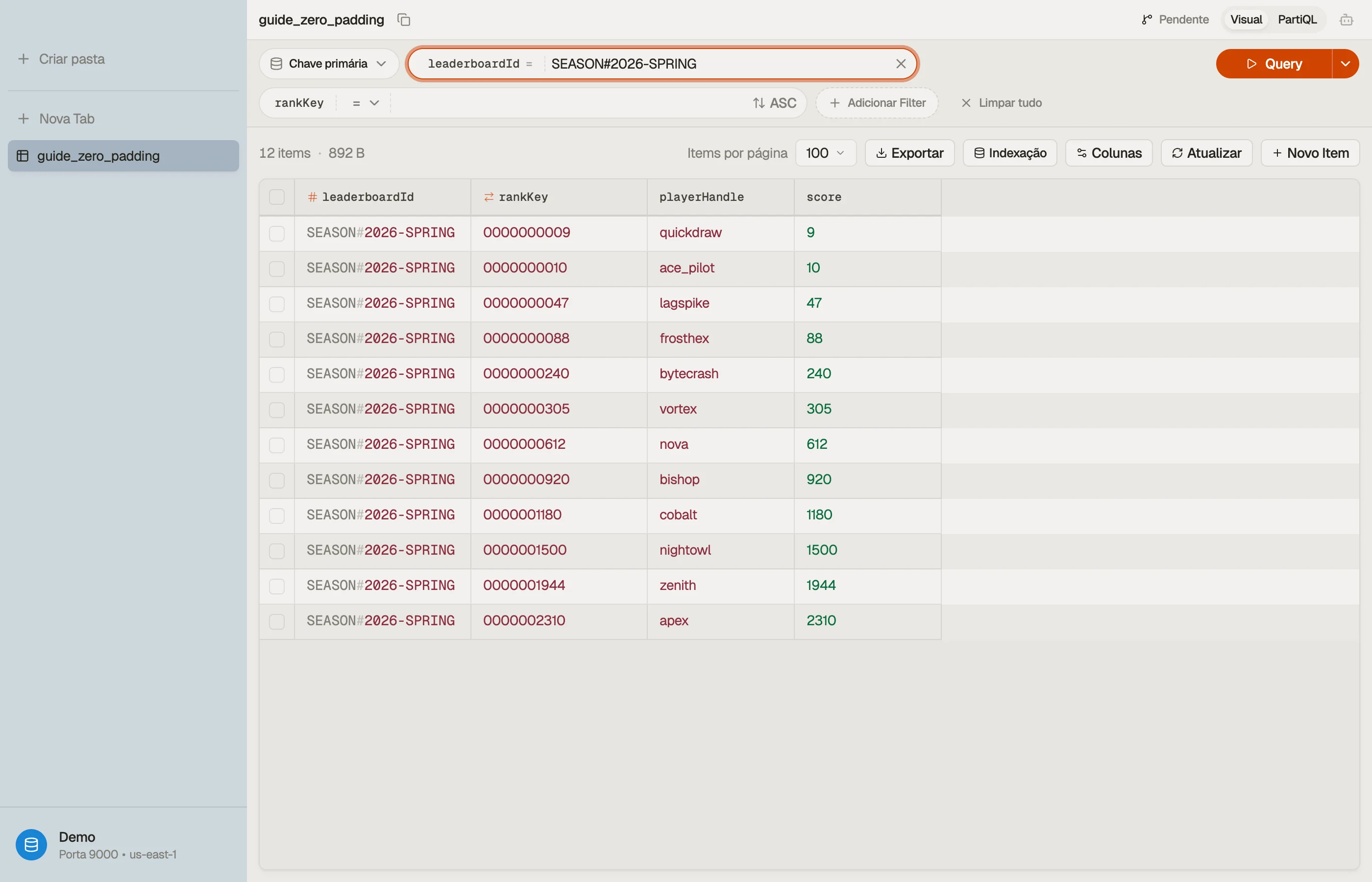
No DynoTable, você pode navegar pelo leaderboard da temporada ordenado pela rankKey
com zero-padding e observar os valores preenchidos alinhando as linhas corretamente —
prova de que as larguras estão certas antes de você colocar em produção.
Ao montar essa chave composta à mão é fácil errar uma largura. Gerar a
KeyConditionExpression para um Query de "topo da temporada" no
expression builder mantém a sintaxe
begins_with / between honesta enquanto você experimenta com larguras.


Ciladas a evitar
- Preencher estreito demais. O esquema todo desmorona na primeira vez que um valor estoura a largura. Dimensione para o pior caso, depois adicione dígitos.
- Esquecer a flag de leitura. Se você só lê descendente,
ScanIndexForward: falsepode ser tudo que você precisa — não recorra a chaves invertidas quando uma flag resolve. - Larguras mistas em uma coleção. Toda chave compartilhando um intervalo de classificação precisa usar a mesma largura. Uma migração que preenche linhas novas mas não as antigas as intercala de forma errada.
- Preencher o segmento errado. Em uma chave composta, preencha todo segmento numérico que participa da ordenação — score e timestamp, ambos, não só o score.
Próximos passos
Zero-padding é uma ferramenta no kit mais amplo de
design de chave de classificação; combine-o com
coleções de itens quando você sobrecarrega uma chave para servir
vários padrões, e apoie-se em um Query preciso em vez de um
Scan assim que a ordenação estiver certa.
Experimente o DynoTable para navegar em uma tabela real e ver suas chaves de classificação com zero-padding caírem em ordem numérica antes de você lançar o schema.