O Padrão de Lista de Adjacência no DynamoDB
Um grafo é só nós e arestas, e o padrão de lista de adjacência armazena ambos como
itens comuns em uma tabela. Cada aresta vira uma linha cuja chave de partição é o nó de
origem e cuja chave de classificação é o destino. Consultar uma partição lista todo
vizinho — o substituto do DynamoDB para um JOIN em uma tabela de junção.
O que é o padrão de lista de adjacência no DynamoDB?
O padrão de lista de adjacência modela um grafo como itens de aresta em uma única tabela: cada relacionamento (A segue B) é uma linha chaveada pela origem na chave de partição e pelo destino na chave de classificação. Consultar uma partição lista todo vizinho, e um GSI invertido inverte o relacionamento — sem joins, sem scans, ambas as direções em um único Query.
- Arestas são itens. Modele cada relacionamento (o usuário A segue o usuário B) como seu próprio item, chaveado pela origem na chave de partição e pelo destino na chave de classificação.
- Uma direção é grátis; a outra precisa de um GSI. A tabela base responde "quem A segue?". Um índice invertido responde "quem segue A?".
- Sem joins, sem scans. Ambas as direções são um único
Querycontra uma partição conhecida — nunca umScande tabela inteira. - É a primitiva muitos-para-muitos. Follows, associações, curtidas, amizades — qualquer grafo onde uma entidade se conecta a muitas outras se encaixa nessa forma.
Enquadre como padrões de acesso
Vindo do SQL, um grafo de follows é uma tabela de junção: follows(follower_id, followee_id). Para listar os seguidores de alguém você indexa uma coluna; para listar
quem segue você indexa a outra. O DynamoDB não tem joins, então você projeta as chaves
para servir cada leitura diretamente.
Anote as leituras primeiro. Para um grafo de follows social:
- Quem o usuário A segue? (sua lista de seguindo)
- Quem segue o usuário A? (sua lista de seguidores)
- A segue B? (um único point lookup)
As chaves existem só para responder essa lista. Acerte-as e toda leitura é um Query
ou um GetItem.
Modele arestas como itens
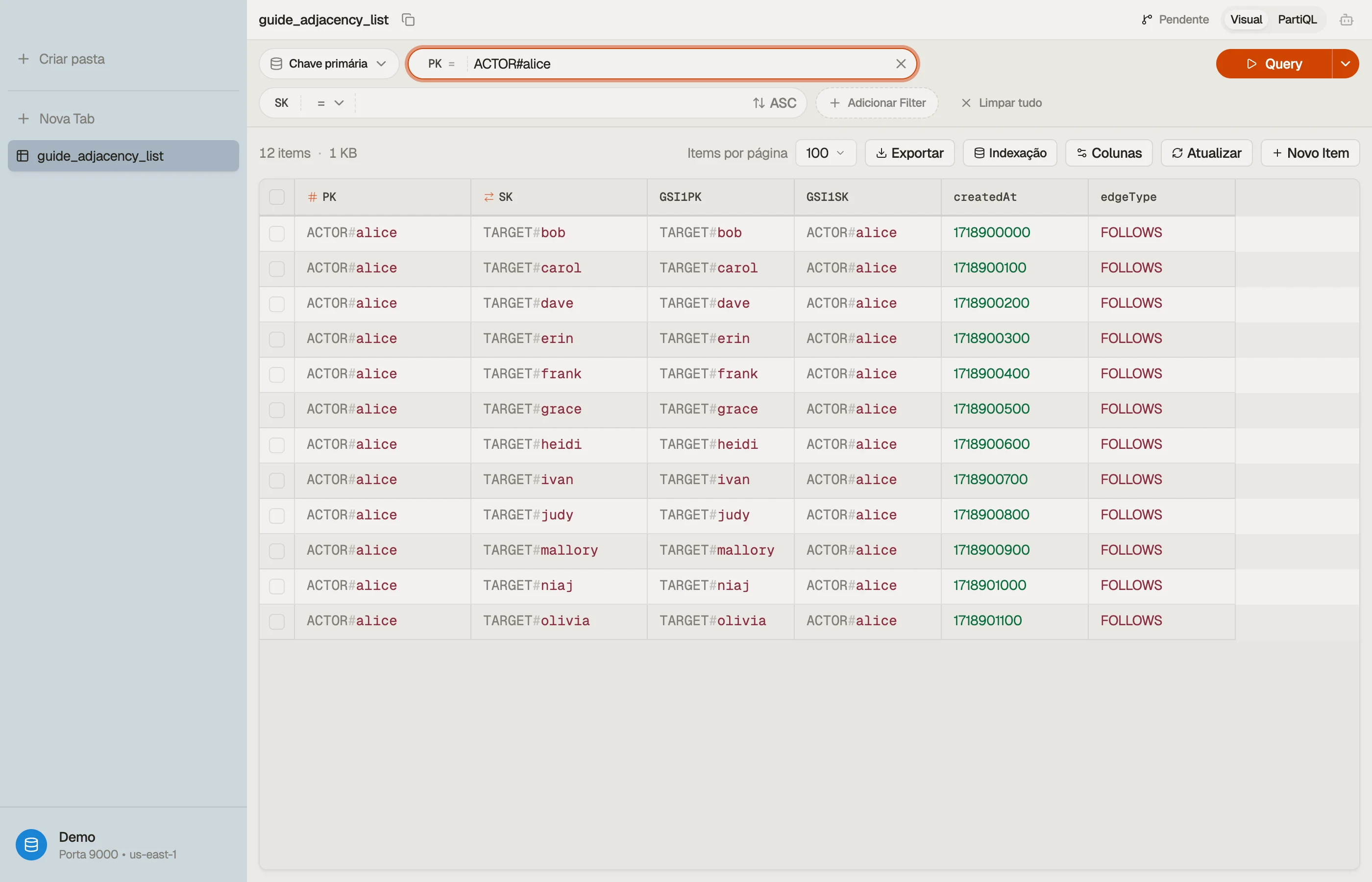
Use nomes de chave genéricos para que a tabela possa conter mais de um tipo de entidade, e codifique o tipo do nó no valor. Uma aresta de follow se parece com isto:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice é a origem da aresta; SK = TARGET#bob é quem ela segue. Um
Query PK = "ACTOR#alice" retorna toda conta que Alice segue em uma única leitura
cobrada — sua lista inteira de seguindo, sem joins.
Cada aresta é escrita uma vez, na direção "quem eu sigo". A direção reversa ("quem me segue") é a parte que a tabela base não consegue responder — ainda.
Percorra a outra direção com um GSI
A tabela base é chaveada origem-primeiro, então não consegue responder "quem segue Bob?" sem fazer scan. Adicione um global secondary index que inverte as chaves: projete o destino na chave de partição do índice e a origem na chave de classificação do índice.
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
Agora Query GSI1 WHERE GSI1PK = "TARGET#bob" lista todo mundo que segue Bob —
alice e dave — em uma leitura. O mesmo item de aresta serve ambas as direções: a
tabela base é seguindo, o índice é seguidores. Você escreve cada aresta uma vez e
ganha ambas as consultas de graça.
Esse é exatamente o padrão que a AWS documenta em seu guia de boas práticas do DynamoDB para modelar relacionamentos muitos-para-muitos e dados de grafo — armazene arestas como itens, depois use um GSI para inverter o relacionamento.
Verifique uma única aresta de forma barata
"Alice segue Bob?" não precisa de nenhuma das listas. Como a aresta é chaveada
PK = ACTOR#alice, SK = TARGET#bob, é um GetItem direto — a leitura mais barata
que o DynamoDB oferece, sem Query, sem índice.
Para escrever o follow de forma idempotente e evitar contagem dupla, proteja o
PutItem com uma condição de que a aresta ainda não exista:
attribute_not_exists(PK)Você pode montar essa condição — e os valores de chave marshalled — com o
DynamoDB expression builder em vez de escrever à
mão a ConditionExpression e os ExpressionAttributeValues.
Faça isso no DynoTable
Quando você navega na tabela, as arestas de um ator se empilham sob uma única chave de partição como uma coleção de itens, e alternar para a visão do GSI mostra a lista invertida de seguidores — as duas metades do relacionamento lado a lado.


Ciladas
A partição celebridade. Um usuário com milhões de seguidores concentra toda aresta
de seguidor sob uma partição GSI1PK = TARGET#<star>. Leituras dessa coleção são
paginadas e podem ficar quentes. Para grafos com fan-out pesado, faça sharding da chave
quente (ex.: TARGET#bob#0..N) ou desnormalize contagens para não reler a lista
inteira.
Armazenar contagens na aresta. Uma contagem de seguidores não é uma aresta — não a derive lendo e contando a partição inteira a cada visualização de perfil. Mantenha um atributo contador no item do usuário e atualize-o transacionalmente com a aresta.
Esquecer que a escrita reversa não é necessária aqui. Uma variante clássica de lista de adjacência escreve a aresta duas vezes com os ids trocados. Com um GSI de chave invertida você a escreve uma vez e deixa o índice materializar a reversa — menos escritas, sem defasagem entre as duas cópias.
Próximos passos
A lista de adjacência é o bloco de construção de relacionamentos do
single-table design; o índice invertido é um
GSI, não um LSI, porque a chave de partição muda. E toda leitura
aqui é um Query ou GetItem em uma chave conhecida — nunca a
cilada do Scan.
Monte as expressões de condição e chave com o DynamoDB expression builder, e baixe o DynoTable para modelar um grafo de follows contra sua própria tabela e ver ambas as direções resolverem em uma leitura.