Coleções de Itens no DynamoDB
Uma coleção de itens é o conjunto de todos os itens de uma tabela (ou índice) que compartilham o mesmo valor de chave de partição. Não é um recurso que você liga — é uma propriedade emergente do seu esquema de chaves.
No momento em que dois itens carregam a mesma chave de partição, eles formam uma
coleção, e essa coleção se torna a unidade que o DynamoDB deixa você ler junto em um
único Query.
Acerte isso e suas leituras voltam em uma ida e volta. Erre e você fica preso a um
Scan.
O que é uma coleção de itens no DynamoDB?
Uma coleção de itens no DynamoDB é o conjunto de todos os itens que compartilham o mesmo valor de chave de partição, armazenados juntos e ordenados pela chave de ordenação. Não é um recurso que você ativa — ela emerge do seu esquema de chaves. A coleção é a unidade que um único Query lê de forma eficiente, enquanto um Scan percorre cada partição.
- Uma coleção é só "mesma chave de partição". Dois ou mais itens com o mesmo valor de chave de partição são armazenados juntos, ordenados pela chave de ordenação.
- É a unidade de um
Queryeficiente.Querylê uma coleção;Scanpercorre cada partição. Essa é toda a história de desempenho. - Sem chave de ordenação, sem coleção. Uma tabela só com chave de partição comporta um item por chave — nada para coletar.
- Dois limites mordem: o teto de 10 GB por coleção quando existe um LSI, e partições quentes vindas de chaves de baixa cardinalidade.
O problema: ler itens relacionados juntos
Digamos que você opere uma frota de veículos, cada um transmitindo telemetria —
velocidade, temperatura do líquido de arrefecimento, nível de combustível — a cada
poucos segundos. A leitura dominante é "me dê as leituras recentes do veículo
V-7741".
Vindo do SQL, você indexaria uma coluna vehicle_id e deixaria o planner fazer o
trabalho. Um armazenamento chave-valor puro não tem esse luxo.
Ele trata cada leitura como um registro isolado, então essa pergunta significa escanear a tabela inteira e filtrar. Lento, caro, e pior conforme a frota cresce.
A resposta do DynamoDB é fazer de "todas as leituras de um veículo" uma coisa agrupada fisicamente e endereçável diretamente. Esse agrupamento é a coleção de itens.
O que uma coleção realmente é
O DynamoDB armazena itens em partições, e roteia cada item para uma partição fazendo o hash da sua chave de partição. Todo item com o mesmo valor de chave de partição, portanto, cai na mesma partição, ordenado pela chave de ordenação.
O AWS Developer Guide nomeia isso exatamente: itens que compartilham um valor de chave de partição são uma coleção de itens, armazenados juntos e ordenados pela chave de ordenação.
Essa é a mesma ideia que o artigo Dynamo da Amazon de 2007 introduziu — hashing consistente para atribuir chaves a nós — estendida com uma dimensão de ordenação para que itens relacionados fiquem adjacentes em disco.
Como estão adjacentes e ordenados, o DynamoDB retorna uma sequência contígua deles
com um seek. É por isso que Query é barato e Scan não é: Query lê uma única
coleção; Scan percorre cada partição.
Para formar uma coleção você precisa de uma chave primária composta — uma chave de partição e uma chave de ordenação. Uma tabela chaveada só pela chave de partição tem exatamente um item por valor de chave, então não há nada para coletar.
Nosso exemplo prático: veículo → leituras de telemetria
Modele o fluxo de telemetria com uma chave composta. A chave de partição identifica o veículo; a chave de ordenação é o timestamp da leitura, o que mantém as leituras ordenadas da mais nova para a mais antiga dentro da coleção.
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPctDuas coleções vivem aqui — uma por veículo. O item META (metadados do veículo) e
todas as leituras de V-7741 formam uma coleção; os itens de V-7742 formam outra.
Note o truque: dê aos metadados uma chave de ordenação (META) que ordene antes de
qualquer valor TS#..., e um único Query em PK = "VEH#V-7741" retorna o perfil do
veículo e suas leituras juntos.
Esse é o padrão pai-e-filhos no cerne do single-table design.
Cada caixa tracejada é uma coleção de itens: mesma chave de partição, itens ordenados
pela chave de ordenação. Um Query lê exatamente uma caixa.
Consultando uma coleção
Como a coleção é ordenada pela chave de ordenação, você ganha leituras de intervalo de graça. Para puxar as leituras registradas em uma janela de dez minutos de um veículo, você limita a chave de ordenação:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest firstA condição de chave te restringe a uma coleção (vehicleId = :v) e depois a uma fatia
contígua dela (recordedAt BETWEEN ...). O DynamoDB lê apenas esses itens e cobra
apenas por eles. Quer só os metadados? recordedAt = "META" busca o único item META.
Construir essas condições de chave e expressões de projeção à mão é trabalhoso. O
DynamoDB Expression Builder gera a
KeyConditionExpression, os ExpressionAttributeNames e os
ExpressionAttributeValues para você, para que os detalhes de palavras reservadas e
placeholders não mordam.
Coleções em índices
Um índice secundário tem seu próprio esquema de chaves, então forma suas próprias coleções de itens.
Adicione um índice secundário global chaveado em depotCode (partição) e recordedAt
(ordenação), e "todas as leituras do depósito DEP-LON-3, da mais nova para a mais
antiga" vira um único Query contra a coleção desse índice — uma leitura que a tabela
base não consegue servir.
É por isso que o tipo de índice importa: ele governa quais coleções você pode formar e como elas se comportam. Veja GSI vs LSI para o trade-off.
Uma distinção afiada: um índice secundário local (LSI) compartilha a chave de partição da tabela base, então sua coleção está fisicamente atrelada à coleção de itens base — e esse vínculo cria um limite rígido, abaixo.
Os limites que mordem
Coleções de itens são poderosas, mas duas restrições decidem como você molda as chaves:
- O limite de 10 GB do LSI. Quando uma tabela tem um ou mais índices secundários
locais, uma única coleção de itens — os itens base mais suas projeções de LSI
para uma chave de partição — não pode exceder 10 GB. Exceda isso e as escritas
que fazem a coleção crescer começam a falhar com
ItemCollectionSizeLimitExceeded. Uma tabela sem LSI não tem esse teto por coleção. É exatamente por isso que um fluxo ilimitado e sempre crescente (telemetria que nunca para) é um mau encaixe para um LSI: a coleção só cresce. Um GSI ganha suas próprias partições, então contorna o limite. - Partições quentes. Uma coleção vive em uma partição, e uma única partição tem
throughput finito. Se um veículo (ou um
depotCode) atrai uma fatia desproporcionalmente grande do tráfego, você pode criar um hot-spot naquela partição mesmo enquanto a tabela como um todo está subprovisionada. A capacidade adaptativa — coberta nos deep-dives "Advanced Design Patterns for DynamoDB" da AWS no re:Invent — isola e turbina chaves quentes automaticamente, mas não consegue salvar uma chave sem espalhamento algum. Escolha chaves de partição com alta cardinalidade para que o tráfego se distribua por muitas coleções.
Veja no DynoTable
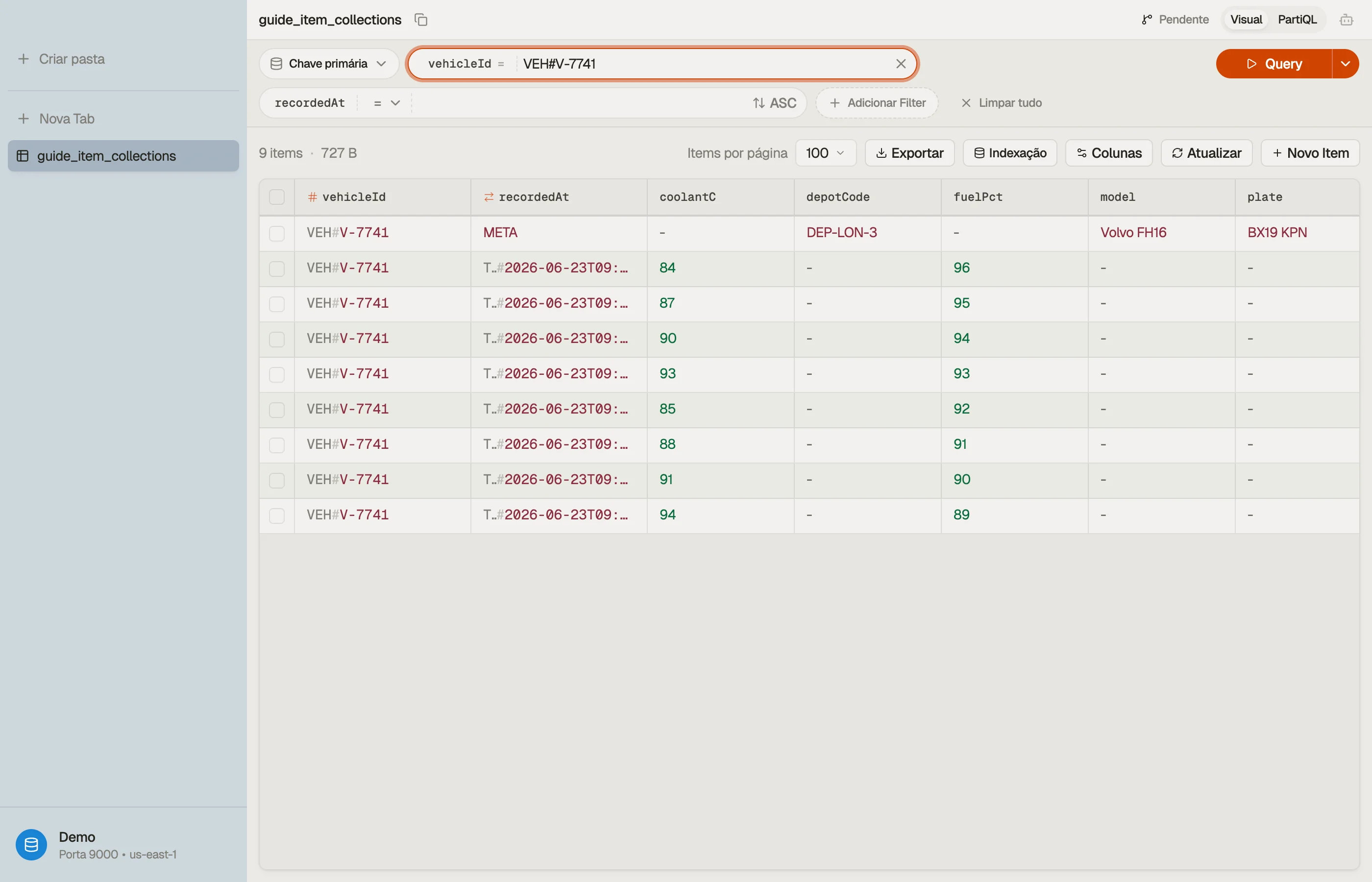
A forma mais rápida de construir intuição para coleções é olhar uma. No DynoTable,
consultar uma chave de partição renderiza a coleção inteira como uma lista contígua e
ordenada pela chave de ordenação — o item META fica logo à frente das suas leituras
com timestamp, na tela, sem reconstrução mental necessária.


Armadilhas e próximos passos
- Sem chave de ordenação, sem coleção. Uma tabela só com chave de partição não consegue agrupar itens relacionados. Se você precisa ler itens juntos, precisa de uma chave composta.
- Não deixe uma coleção de LSI crescer sem limite. Fluxos só de append pertencem a um GSI (ou a uma chave de partição com buckets temporais), não a um LSI, por causa do teto de 10 GB.
- Espalhe suas chaves de partição. Uma coleção só é tão escalável quanto a partição em que vive. Chaves de partição de baixa cardinalidade criam hot spots.
- Recorra a
Query, não aScan. Coleções existem para que você possa ler itens relacionados com um únicoQuerydirecionado; recorrer a umScanjoga essa vantagem fora — veja Query vs Scan.
Esboce seu próprio esquema de chaves, rode um Query contra uma chave de partição
real, e veja a coleção voltar ordenada. Baixe o DynoTable e explore as
coleções das suas tabelas diretamente.