Chaves de Classificação Compostas no DynamoDB
Uma chave primária composta é uma chave de partição mais uma chave de
classificação. O truque que a torna poderosa é o que você coloca dentro da chave de
classificação: codifique uma hierarquia como uma única string delimitada, e um único
Query lê uma subárvore inteira em ordem de classificação — sem joins, sem recursão,
sem segunda ida e volta.
Como funcionam as chaves de classificação compostas no DynamoDB?
Uma chave de classificação composta empacota uma hierarquia em uma única string delimitada — root/photos/2026/ — que o DynamoDB armazena em ordem de bytes UTF-8. Como o layout já corresponde à árvore, um único Query com begins_with(SK, "root/photos/") lê uma subárvore inteira em ordem de caminho. Sem joins, sem recursão, sem segunda ida e volta — apenas um scan de prefixo sobre uma fatia contígua.
- A chave de classificação é uma string ordenável, não só um ID. Empacote um
caminho nela —
root/photos/2026/— e o DynamoDB armazena os itens da partição em ordem de bytes UTF-8 automaticamente. - Um delimitador transforma correspondências de prefixo em leituras de subárvore.
begins_with(SK, "root/photos/")retorna todo descendente daquela pasta em uma consulta. - Chaves de classificação suportam condições de intervalo, não filtros arbitrários.
Você tem
begins_with,between,>,<— projete a chave para que a leitura que você precisa seja um prefixo ou um intervalo, não umScan. - O delimitador é estrutural. Escolha um que não possa aparecer em um segmento de caminho, ou dois ramos sem relação colidem.
Por que a chave de classificação é o jogo inteiro
Vindo do SQL, você modelaria uma árvore de pastas com um self-join parent_id e a
percorreria recursivamente — uma consulta por nível. No DynamoDB isso é uma cilada N+1
contra um armazenamento chave-valor que não tem joins.
O DynamoDB armazena cada item sob uma chave de partição ordenada por sua chave de classificação, em ordem de bytes UTF-8 para strings (AWS: condições de chave do Query). Então se a sua chave de classificação é o caminho, o layout físico já corresponde à árvore. Uma leitura vira um scan de prefixo sobre uma fatia contígua — não uma travessia de grafo.
Essa é a virada: a chave de classificação não é um identificador que você compara exatamente. É um endereço ordenável. Projete-a e a consulta cai no seu colo de graça.
Modele uma árvore de sistema de arquivos
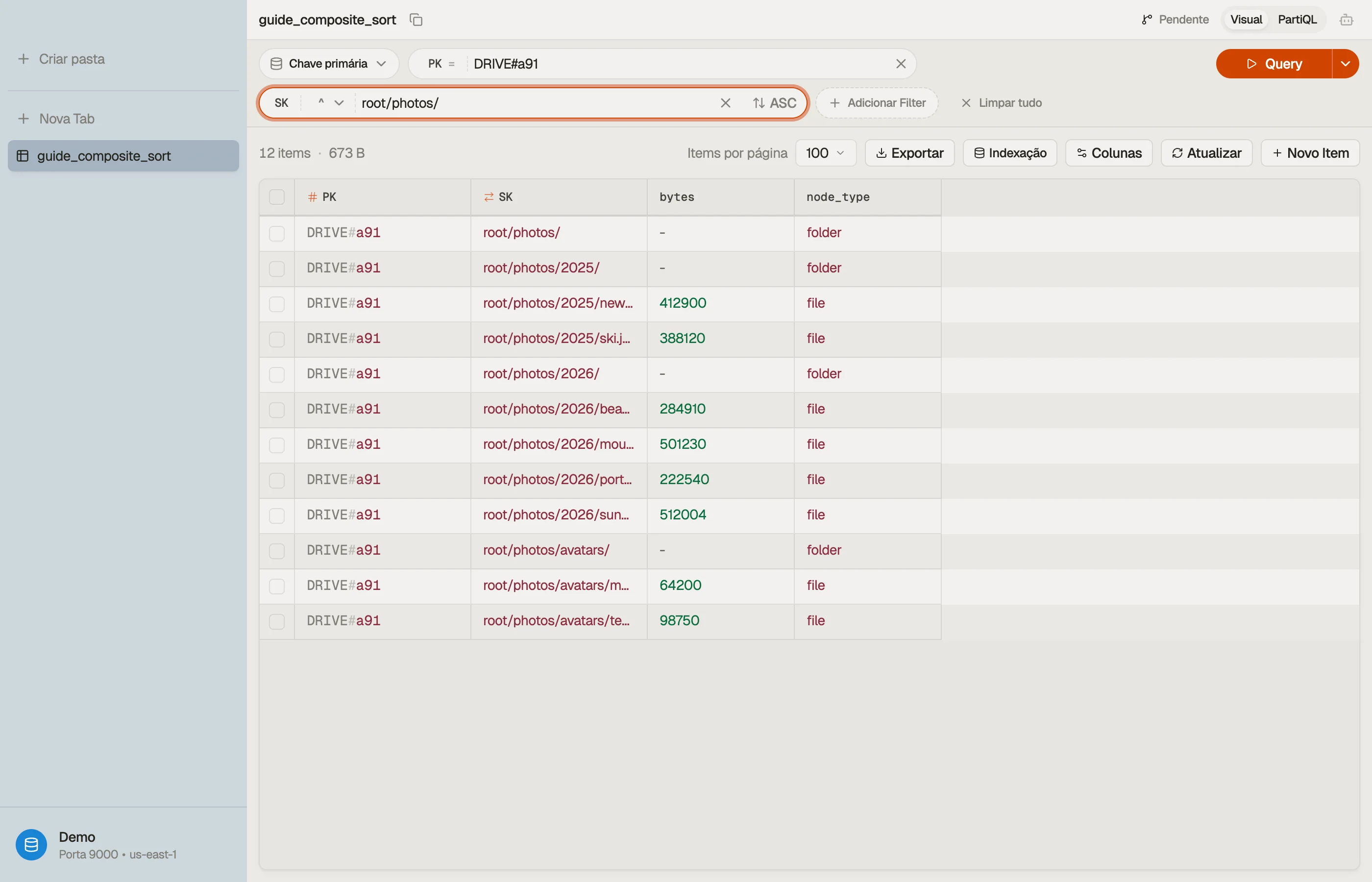
Digamos que você esteja armazenando árvores de arquivos por conta. Um drive por conta é a partição natural; o caminho dentro dele é a chave de classificação.
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
Duas convenções originais fazendo o trabalho aqui:
PK = DRIVE#<account>mantém a árvore inteira de uma conta em uma única coleção de itens, então qualquer leitura de subárvore é umQueryde partição única.SKé o caminho completo com uma/final nas pastas. A barra final é deliberada — faz uma pasta ser classificada antes dos próprios filhos e mantémroot/photos/distinto de um arquivo irmão chamadoroot/photos.
Leia uma subárvore em uma consulta
Liste tudo sob root/photos/ — pasta, subpastas e arquivos, recursivamente:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"Isso retorna root/photos/, root/photos/2026/, beach.jpg e sunset.jpg — em
ordem de caminho, em uma leitura cobrada. Você paga apenas pelos itens daquela fatia,
não pelo drive inteiro.
No DynoTable, você executa exatamente esta consulta begins_with contra a chave de
classificação de caminho e a pasta junto com seus descendentes volta em ordem de caminho —
sem precisar escrever à mão a sintaxe de placeholder.
Precisa do KeyConditionExpression bruto (nomes, valores e begins_with) para o seu
próprio código? Monte e copie no
DynamoDB Expression Builder.


Liste um nível, não a subárvore inteira
begins_with te dá a leitura recursiva. Para uma listagem de diretório não
recursiva — os filhos imediatos de root/photos/ e nada mais profundo — armazene um
atributo de profundidade e adicione um intervalo de chave de classificação mais um
filtro, ou divida o caminho em um GSI parent. A versão mais simples: mantenha um
atributo parent (root/photos/) e um GSI chaveado nele.
O ponto: uma chave de classificação responde perguntas de prefixo e intervalo
de forma barata. "Apenas filhos diretos" é uma pergunta diferente — modele-a
explicitamente em vez de torcer para que uma FilterExpression a torne eficiente. Um
filtro roda depois da leitura e você paga por cada item que ele descarta.
Escolha o delimitador com cuidado
O delimitador é parte do seu contrato de dados. Duas regras:
- Ele nunca pode aparecer dentro de um segmento de caminho. Se nomes de arquivo
puderem conter
/,/é o delimitador errado — um arquivo chamadoa/bé indistinguível de uma pastaacontendob. Escolha um byte reservado (alguns times usam#ou um caractere de controle) e proíba-o nos segmentos. - Atente para a ordem de classificação nos limites.
/(0x2F) é classificado antes de dígitos e letras, o que geralmente é o que você quer para ordem de árvore. Mude o delimitador e você muda a ordenação — verifique contra dados reais.
Chave de classificação composta vs. um atributo de classificação separado
Chave de classificação composta (root/photos/2026/x) | Chave de classificação de ID simples + atributo parent | |
|---|---|---|
| Leitura de subárvore | Uma consulta begins_with | Consultas recursivas (N+1) ou travessia de GSI |
| Ordenação | Ordem de caminho, grátis | É preciso adicionar um atributo de classificação explícito |
| Mover / renomear | Reescrever todos os descendentes | Atualizar um ponteiro parent |
| Listagem de filhos diretos | Precisa de atributo de profundidade ou GSI | Natural (parent = x) |
Chaves compostas vencem quando as leituras têm forma de subárvore e a ordenação importa; o modelo de ID plano vence quando a árvore muda constantemente. A maioria das hierarquias com leituras pesadas — árvores de arquivos, árvores de categorias, organogramas — tendem ao composto.
Ciladas e próximos passos
- Não superlote a chave. Tudo que você codifica é imutável e indexado apenas por prefixo. Atributos que você consulta por igualdade pertencem aos próprios campos ou a um GSI, não enfiados na chave de classificação.
- Uma chave de classificação não faz
WHEREarbitrário. Apenasbegins_with,betweene comparações. Se você se pegar buscando umaFilterExpression, provavelmente modelou a chave errado — veja Query vs. Scan. - Aprofundando no design de chaves vive em single-table design; para quando uma leitura de subárvore precisa de um índice em vez da tabela base, veja GSI vs. LSI.
Monte a condição de chave begins_with com o
Expression Builder, depois
baixe o DynoTable para rodar essas consultas de prefixo contra suas
próprias tabelas e ver uma subárvore voltar em ordem de caminho.