O Limite de Tamanho de Item do DynamoDB (400 KB)
Um único item do DynamoDB pode conter no máximo 400 KB de dados. Vindo do MongoDB
(documentos de 16 MB) ou de uma linha relacional sem teto prático, esse limite parece
baixo — e você tende a descobri-lo do jeito difícil, quando uma escrita que funcionou
por meses subitamente falha com um ValidationException porque um item finalmente
cresceu demais.
O limite não é arbitrário, e não é uma cota que você possa aumentar. É uma restrição de modelagem, e os itens que batem nele geralmente estão te dizendo que os dados foram modelados de forma errada.
Qual é o tamanho máximo de item no DynamoDB?
O DynamoDB limita um único item a 400 KB — um limite rígido que você não pode aumentar. O tamanho conta os nomes de atributos mais os valores, juntos, incluindo cada elemento aninhado de lista, mapa e set. Os itens normalmente o atingem por crescimento ilimitado, como uma lista embutida que cresce sem parar; a correção é modelagem, dividir a coleção em itens separados, não compressão.
- 400 KB por item, teto rígido. Não ajustável, não é uma cota flexível.
- Tamanho = nomes de atributos + valores, juntos. Nomes de atributos longos contam, em cada item.
- Aninhamento e sets também contam. Listas, mapas e seus valores aninhados todos se somam.
- A causa usual é o crescimento ilimitado — embutir uma lista que cresce sem limite em um item pai.
- A correção é modelagem, não compressão. Divida a coleção crescente em seus próprios itens sob uma chave de partição compartilhada.
O problema: o item que cresce para sempre
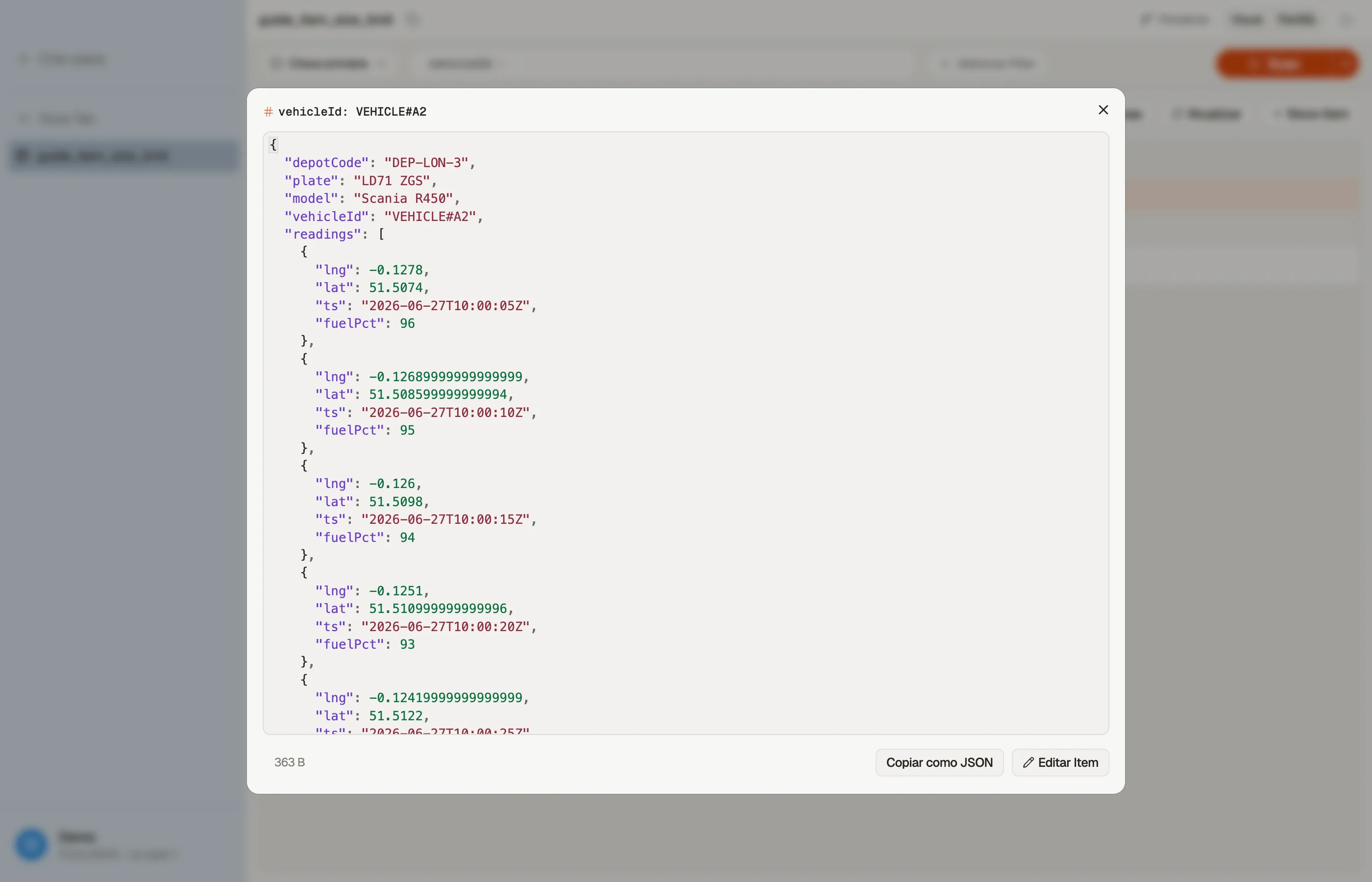
Digamos que você rastreie uma frota de veículos, e decide armazenar as leituras de telemetria de cada veículo como uma lista no item do veículo:
PK: VEHICLE#A1 readings: [ {ts, lat, lng, fuel}, {ts, lat, lng, fuel}, ... ]Por um dia ou dois está tudo bem. Mas as leituras chegam a cada poucos segundos e nunca param, então a lista cresce sem limite. Eventualmente um único item de veículo cruza os 400 KB e toda escrita nele falha — você não consegue mais registrar telemetria daquele veículo de jeito nenhum, porque cada atualização reescreve o item inteiro (agora superdimensionado).
O bug não é o limite de tamanho. É modelar um relacionamento um-para-muitos ilimitado como uma lista embutida. Isso só funciona quando o lado "muitos" é limitado e pequeno.
O que de fato conta para os 400 KB
O DynamoDB mede o tamanho total do item como a soma de:
- Cada nome de atributo, codificado em UTF-8. Um nome de 20 caracteres repetido por milhões de itens é tanto tamanho quanto armazenamento que você paga — é por isso que modeladores experientes mantêm os nomes de atributos curtos.
- Cada valor de atributo. Strings e binário pelo seu comprimento em bytes; números por uma codificação compacta; booleanos e nulos por um custo fixo minúsculo.
- Estrutura aninhada. Uma lista ou mapa conta seu próprio overhead mais o tamanho de cada elemento e chave dentro dela, até o fundo.
Não há um limite separado por atributo para planejar em torno — é o item inteiro contra a linha de 400 KB. As cotas de serviço da AWS detalham a contabilidade exata de bytes.
Por que o limite existe
Itens grandes são caros de mover. As leituras do DynamoDB são medidas em unidades de 4 KB, então um item de 400 KB custa 100 RCU para ler de forma forte — e leituras, escritas e replicação todas ficam mais lentas e mais caras conforme os itens crescem. O teto te empurra em direção a itens pequenos e direcionados, e para longe do anti-padrão "buscar um blob gigante" que iniciantes em NoSQL recorrem por hábito relacional.
Modelando em torno dele
Para o exemplo da frota, pare de embutir. Dê a cada leitura seu próprio item na mesma partição que o veículo, ordenado por timestamp na chave de ordenação:
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:05Z lat, lng, fuel
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:10Z lat, lng, fuelAgora nenhum item único cresce, as escritas nunca extrapolam o teto, e um único Query
em VEHICLE#A1 ainda traz de volta as leituras de um veículo como uma única
coleção de itens ordenada. Sub-listas limitadas (um
punhado de tags, um bloco de configuração fixo) são adequadas para embutir; as
ilimitadas viram itens.
Verificando o tamanho de item no DynoTable
Antes de se comprometer com um formato, pese um item representativo. No DynoTable, abra um no Quick View e ele mostra o tamanho em bytes do item junto com seus atributos — para que você pegue uma forma pesada demais enquanto navega dados reais, no momento do design em vez de na escrita que falhou.
Prefere ficar no navegador? A calculadora de tamanho de item do DynamoDB faz o mesmo a partir de uma amostra colada, relatando os KB exatos e a RCU/WCU que cada leitura e escrita vai custar.


Armadilhas e próximos passos
- Fique de olho em listas embutidas que crescem com o tráfego — elas são a clássica bomba-relógio de 400 KB. Limite-as ou separe-as.
- Encurte os nomes de atributos em itens de alta cardinalidade — é tamanho e armazenamento de volta de graça.
- Valores grandes pertencem ao S3. Armazene blobs grandes (imagens, documentos) no S3 e mantenha apenas a chave no item.
- Relacionado: desnormalização e relacionamentos um-para-muitos cobrem quando embutir vs separar.
Quer ver tamanhos de item reais por toda uma tabela de relance? Baixe o DynoTable e inspecione seus dados diretamente.