Relacionamentos Muitos-para-Muitos no DynamoDB
Um aluno se matricula em muitos cursos; um curso comporta muitos alunos. No SQL,
você recorre a uma tabela de junção e a um JOIN de quatro vias.
O DynamoDB não tem joins, então o relacionamento precisa viver nas chaves — e o
truque é armazenar cada aresta de matrícula em uma forma que os dois lados possam
consultar com Query diretamente.
Este guia percorre o problema alunos ↔ cursos de ponta a ponta: os padrões de acesso, o padrão de lista de adjacência que os resolve, um esquema de chaves original que você pode copiar, e como ler os dois sentidos de volta sem nunca escanear a tabela.
Como modelar um relacionamento muitos-para-muitos no DynamoDB?
O DynamoDB não tem joins, então você modela um relacionamento muitos-para-muitos com o padrão de lista de adjacência: armazene cada vínculo como seu próprio item de aresta chaveado por um dos lados e, em seguida, adicione um GSI invertido que troca as chaves. Uma única aresta, escrita uma vez, responde consultas dos dois sentidos de forma eficiente.
- Armazene cada matrícula como seu próprio item de aresta, não como um atributo de lista em qualquer um dos lados.
- Chaveie a aresta pelo aluno (
PK = STU#…,SK = ENROLL#CRS#…) para que um únicoQueryretorne a lista de cursos inteira de um aluno. - Adicione um GSI invertido que troca os papéis (
GSI1PK = CRS#…) para que a mesma aresta também responda "quem está neste curso?". - Uma aresta, escrita uma vez, lida barato nos dois sentidos — esse é o jogo inteiro.
Enquadre os padrões de acesso primeiro
A modelagem no DynamoDB é orientada a padrões de acesso: você decide as leituras antes de escolher um único nome de atributo. Um relacionamento muitos-para-muitos quase sempre tem duas leituras simétricas mais os lookups de entidade:
- Obter o perfil de um aluno e listar todos os cursos em que esse aluno está matriculado.
- Obter os metadados de um curso e listar todos os alunos matriculados nesse curso.
- Buscar uma única aresta de matrícula — para atualizar uma nota ou trancar o curso.
A dor: as duas leituras de lista apontam em sentidos opostos sobre o mesmo conjunto
de arestas. Um design ingênuo serve uma de forma barata e força um Scan para a
outra — exatamente a cilada coberta em Query vs Scan.
A tarefa é tornar os dois sentidos um único Query.
Use o padrão de lista de adjacência
A própria orientação do DynamoDB para relacionamentos é a lista de adjacência: modele cada relacionamento como um item cuja chave de partição é um extremo e cuja chave de ordenação é o outro.
A AWS documenta isso na página Best Practices for Managing Many-to-Many Relationships do DynamoDB Developer Guide.
Por que chaves e não uma segunda tabela? Porque a primitiva que o DynamoDB te dá é
um Query contra uma única partição.
Um Query lê um intervalo contíguo de valores de chave de ordenação sob uma chave
de partição em uma única operação cobrada — esse é o único "join" que o motor
oferece.
Para conseguir um relacionamento que se lê barato dos dois lados, você duplica a aresta: escreve uma vez chaveada pelo aluno, depois usa um índice secundário para projetar a mesma aresta chaveada pelo curso.
Esse é o raciocínio de chave sobrecarregada do Single-Table Design, aplicado a um relacionamento em vez de a uma hierarquia pai-filho.
A forma é duas visões empilhadas da mesma aresta — a tabela base chaveada pelo aluno, o GSI invertido chaveado pelo curso:
Cada aresta é escrita uma vez na tabela base e projetada no GSI com suas chaves
trocadas, então um Query contra qualquer uma das partições lê o relacionamento
barato.
A linhagem remonta ao artigo Dynamo da Amazon de 2007: a chave de partição é a unidade de distribuição, e o acesso por chave única é o caminho rápido.
Relacionamentos no DynamoDB são um exercício de dobrar leituras muitos-para-muitos para dentro desse caminho rápido.
Trabalhe o exemplo: alunos ↔ cursos
Use uma tabela com chaves genéricas, PK e SK, e codifique o tipo de entidade no
valor. A aresta de matrícula é o coração de tudo:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Um único Query PK = "STU#a91" retorna o perfil do aluno e cada matrícula em
uma leitura. Estreite com SK begins_with "ENROLL#" para obter só as arestas de
curso. Isso resolve "listar os cursos de um aluno".
Mas "listar os alunos de um curso" aponta para o outro lado — e a tabela base não consegue respondê-la, porque o id do aluno está na chave de partição, não na de ordenação.
Adicione um índice secundário global invertido que troca os papéis. Dê aos itens
de aresta um par genérico GSI1PK/GSI1SK segurando o curso no lado da partição e o
aluno no lado da ordenação:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Agora Query GSI1 WHERE GSI1PK = "CRS#math204" lista cada aluno daquele curso — a
leitura que a tabela base não conseguia servir. Um item de aresta, escrito uma vez,
responde os dois sentidos.
Tem que ser um GSI, não um LSI: a partição do curso é inteiramente diferente da partição do aluno, e um LSI compartilha a chave de partição da tabela base.
O índice abrange várias partições, então precisa ser global — veja GSI vs LSI.
Um detalhe: GSIs no DynamoDB são populados de forma assíncrona. Uma matrícula
recém-criada pode levar um instante para aparecer no sentido CRS#….
Trate a leitura da lista de alunos do curso como eventualmente consistente — o que o Developer Guide aponta explicitamente para índices secundários globais.
Escreva e leia no DynoTable
Escrever a matrícula significa definir quatro atributos de chave mais os dados da
própria aresta. A condição que impede um aluno de se matricular duas vezes no mesmo
curso é uma guarda attribute_not_exists(PK) na chave composta.
Esse é exatamente o tipo de condição que você pode montar visualmente com o
DynamoDB Expression Builder, em vez de escrever
à mão os ExpressionAttributeNames e os valores de placeholder.
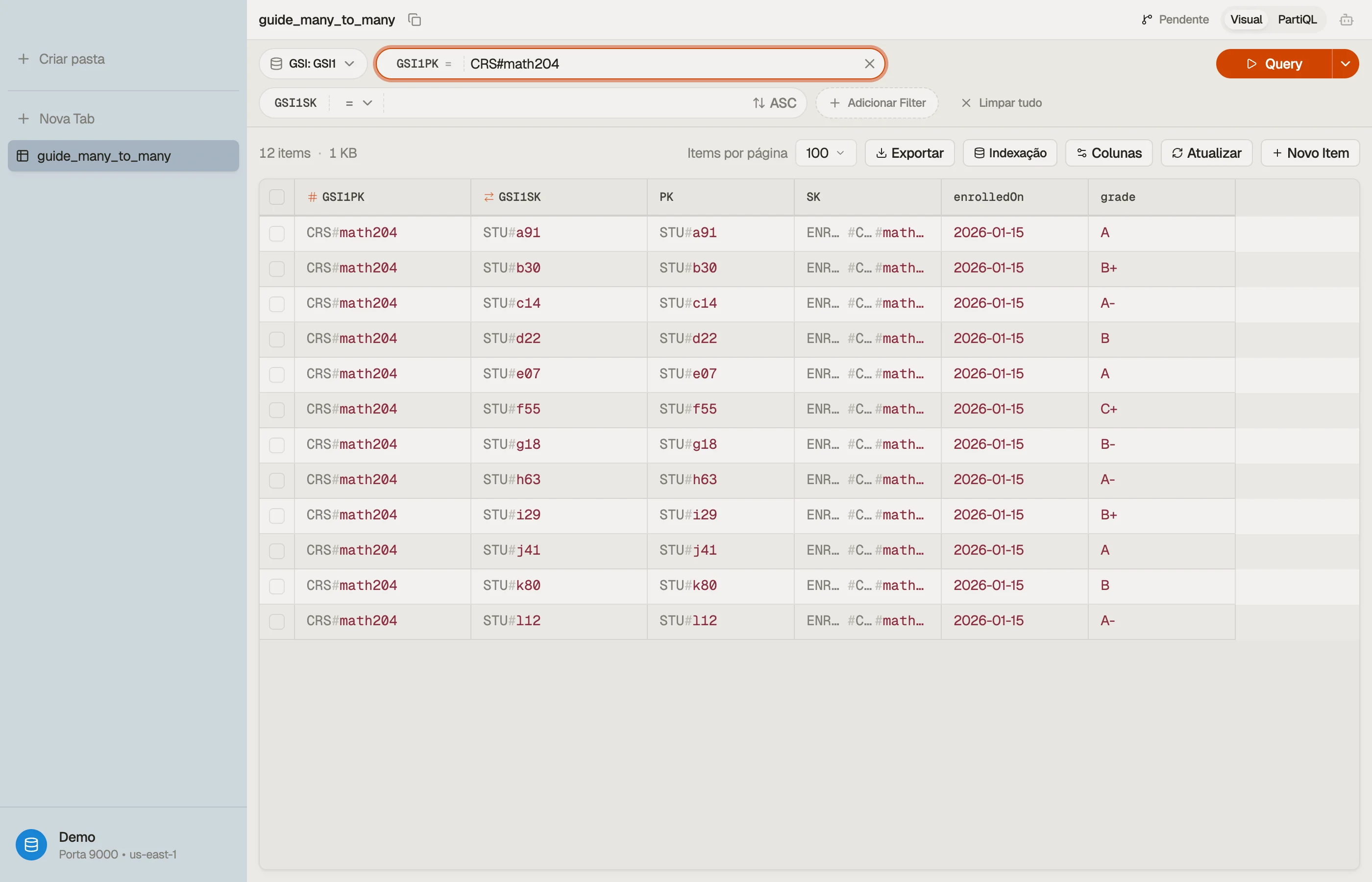
No DynoTable você aponta um Query para o GSI1, define GSI1PK = "CRS#math204", e
a lista de alunos volta como uma tabela que você pode ler, ordenar e editar no lugar —
os dois sentidos do relacionamento navegáveis a partir de um esquema.


Armadilhas e próximos passos
- Não armazene um lado como atributo de lista. Um array
courseIdsno item do aluno parece organizado até um curso precisar da sua lista de alunos, o array bater no teto de 400 KB por item, ou duas matrículas competirem e se sobrescreverem. Itens de aresta discretos escalam e se atualizam de forma independente. - Mantenha os dados da aresta na aresta. A
gradee oenrolledOnda matrícula pertencem ao item de aresta, não duplicados no aluno ou no curso — há exatamente uma linha por par (aluno, curso) para atualizar. - Atente para a propagação do GSI. O sentido do índice invertido é eventualmente consistente, então uma leitura imediatamente após uma matrícula pode atrasar uma fração de segundo.
- Projete só o que a lista de alunos precisa. Uma projeção
KEYS_ONLYou estreita mantém o GSI pequeno quando a visão de lista só precisa de ids.
Para se aprofundar nos padrões ao redor, leia Single-Table Design para chaves sobrecarregadas e GSI vs LSI para quando o índice invertido tem que ser global.
Depois baixe o DynoTable para modelar o esquema alunos ↔ cursos de verdade — escreva as arestas, construa a condição com o Expression Builder, e consulte os dois sentidos do relacionamento sem um único scan.