Sobrecarga de Chaves no DynamoDB
Vindo do SQL, uma coluna significa uma coisa para sempre: orders.created_at é sempre
uma data, users.email é sempre um email. A sobrecarga de chaves joga isso fora.
Você dá às chaves de partição e classificação nomes genéricos — pk, sk — e deixa
cada tipo de item despejar um significado diferente nelas. Uma tabela, muitas
entidades, uma forma.
O que é sobrecarga de chaves no DynamoDB?
A sobrecarga de chaves consiste em armazenar muitos tipos de entidade em uma só tabela sob nomes genéricos de chave como pk/sk, codificando o tipo no valor (USER#u_3001, INVOICE#2026-0014). O nome do atributo permanece neutro para que usuários, faturas e eventos compartilhem uma mesma partição; o valor carrega o tipo, e um prefixo na chave de classificação permite que um único Query filtre cada entidade via begins_with.
- Nomes de chave genéricos, valores tipados. Nomeie suas chaves
pk/ske coloque o tipo da entidade no valor:pk = "TENANT#acme",sk = "USER#u_3001". O nome é burro; o valor carrega o tipo. - É o que faz o single-table design funcionar. Sem sobrecarga, uma tabela
compartilhada é só uma gaveta de bagunça. Com ela, toda entidade fica em uma partição
que você pode dar
Query. begins_withé o ganho. Um prefixo de tipo na chave de classificação deixa umQuerypuxar uma entidade inteira, ou uma fatia dela, semScane sem filtro.- O custo: legibilidade. Um dump cru de
pk/sknão te diz nada. Você precisa de um visualizador que decodifique os prefixos, ou vai ficar apertando os olhos para strings.
Por que nomes genéricos vencem os reais
O DynamoDB tem exatamente dois atributos de chave por tabela, e um Query só pode
mirar uma única chave de partição. Então se você nomeia sua chave userId, só itens de
usuário podem viver naquela tabela de forma limpa — todo o resto tem que fingir um
userId ou mudar para sua própria tabela.
A sobrecarga contorna isso. Um nome neutro como pk não se compromete com nenhuma
entidade, então um usuário, uma fatura e um evento de auditoria podem todos
compartilhar o mesmo atributo de chave e a mesma tabela. O valor, não o nome do
atributo, diz o que o item é.
Esse é o movimento que transforma o single-table design de teoria em algo que você de fato pode consultar. A tabela compartilhada é o contêiner; a sobrecarga é o que deixa entidades distintas coexistirem dentro dele.
Um exemplo multi-tenant
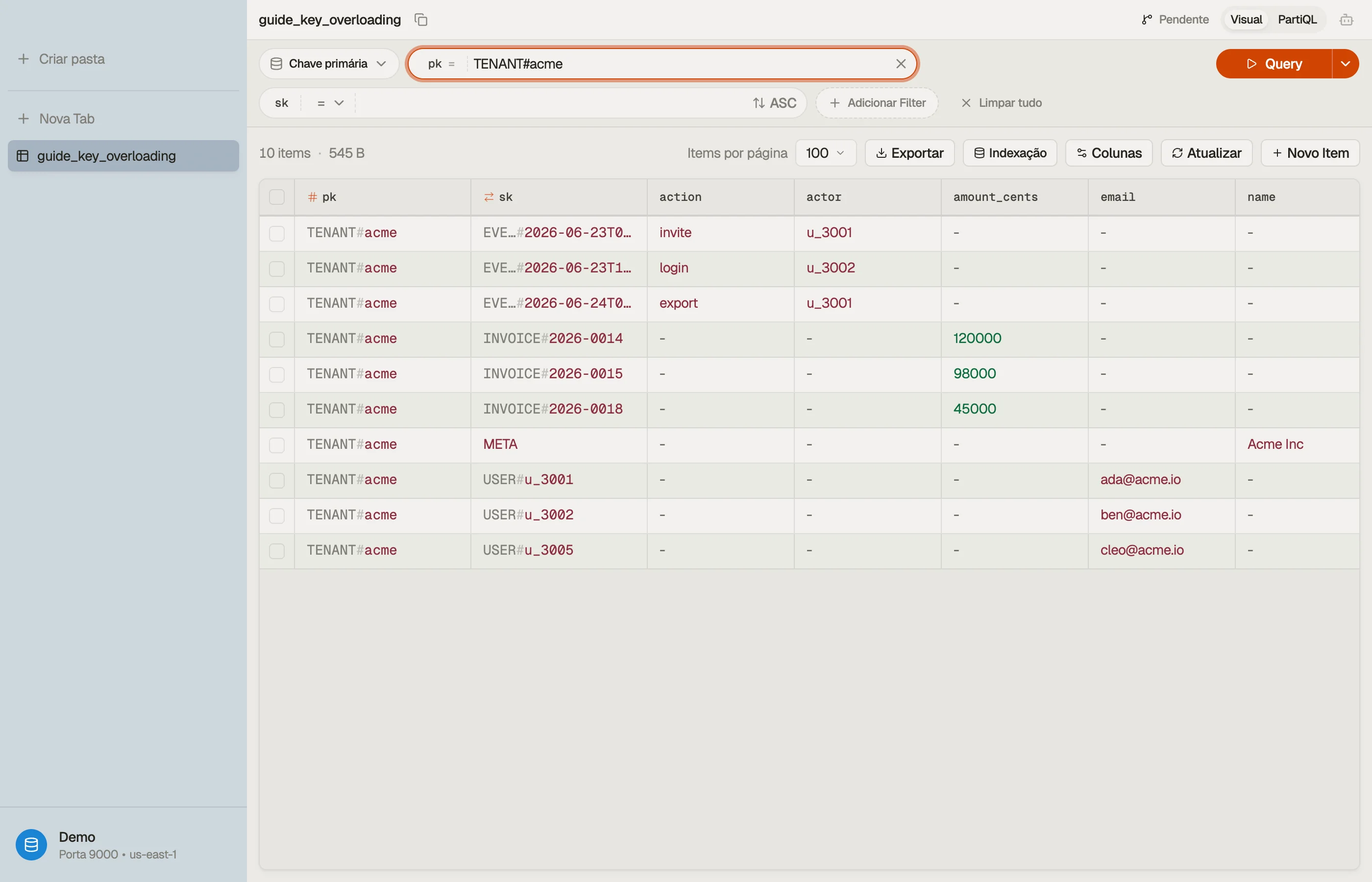
Digamos que você administre um produto SaaS de billing. Cada tenant tem membros, faturas e uma trilha de auditoria. Em vez de três tabelas, coloque tudo em uma e sobrecarregue as chaves:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
Toda linha compartilha pk = "TENANT#acme", então formam uma coleção de itens —
todas colocalizadas, todas alcançáveis em uma leitura de partição.
O prefixo da chave de classificação está fazendo o trabalho de verdade. Ele agrupa entidades e as ordena.
Consulte a coleção sobrecarregada
Como o tipo vive no prefixo da chave de classificação, begins_with fatia a partição
por entidade sem fazer scan em nada:
Query pk = "TENANT#acme" -- o tenant inteiro, todo tipo
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- só membros
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- só faturasVocê paga apenas pelos itens que a condição corresponde, não pela partição inteira — o
oposto de um Scan filtrado, onde você paga para ler linhas
que depois joga fora. A AWS chama isso de condição de chave; ela roda nas chaves
antes de qualquer dado deixar a partição.
Se você montar essa condição begins_with à mão, acerte as tags de tipo — um
USERS# perdido em vez de USER# retorna nada, silenciosamente. O
expression builder gera a
KeyConditionExpression e o mapa ExpressionAttributeValues para que os prefixos
correspondam ao que você realmente escreveu.
Sobrecarregue o índice também
O mesmo truque se aplica a um GSI. Dê a ele nomes de chave genéricos — gsi1pk,
gsi1sk — e deixe cada entidade escrever o que precisar. Um índice então responde
padrões que a tabela base não consegue.
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
Agora Query gsi1 WHERE gsi1pk = "STATUS#open" lista toda fatura aberta em todos os
tenants, ordenada por data de vencimento — uma visão cross-partition que as chaves da
tabela base, escopadas por tenant, jamais poderiam servir. Uma entidade diferente pode
reusar gsi1 com seu próprio significado (digamos gsi1pk = "ROLE#admin"), então um
índice cobre várias leituras. Só lembre que um GSI é
eventualmente consistente — suas escritas atrasam em relação à
tabela base.
Faça isso no DynoTable
Chaves sobrecarregadas cruas são hostis à leitura: INVOICE#2026-0015 e
EVENT#2026-06-23T09:12Z se borram em uma lista plana. Um visualizador que agrupa por
partição e expõe os prefixos transforma a gaveta de bagunça de volta em entidades.


Ciladas
- Escolha delimitadores uma vez e nunca os mude.
#é a convenção. Misturar#e:entre entidades quebrabegins_withde jeitos que nada te avisa. - Não sobrecarregue valores que precisam de matemática de intervalo. Uma chave de
classificação de
INVOICE#2026-0015ordena lexicamente, não numericamente — faça zero-padding nos ids e use datas ISO-8601 para que a ordem de string corresponda à ordem que você quer. - Reserve o namespace de prefixos. Dois tipos de entidade que começam ambos com
USER(digamosUSER#eUSERGROUP#) vão colidir sobbegins_with(sk, "USER"). Torne os prefixos inequívocos a partir do primeiro caractere. - Planeje a leitura antes das chaves. A sobrecarga serve padrões de acesso que você enumerou. Se você ainda não conhece suas leituras, veja single-table design primeiro — as chaves são derivadas das consultas.
Mapeie uma partição, depois baixe o DynoTable para navegar nas suas
próprias chaves sobrecarregadas e ver um Query puxar um tenant inteiro de uma vez.