Projeções de Índice no DynamoDB: KEYS_ONLY, INCLUDE e ALL
Quando você cria um índice secundário, o DynamoDB não copia automaticamente o item inteiro para ele. Você escolhe o que é copiado — a projeção do índice. Escolha pouco demais e suas consultas pagam uma segunda leitura para buscar o resto; escolha tudo e você paga armazenamento e custo de escrita extras a cada atualização. É um trade-off que você define uma vez na criação do índice e convive com ele.
(Não confunda isso com uma projection expression, que enxuga os atributos que uma única leitura retorna. Esta página é sobre o que um índice armazena fisicamente — veja projection expressions para a outra.)
O que é uma projeção de índice no DynamoDB?
Uma projeção é o conjunto de atributos que o DynamoDB copia da tabela base para um índice secundário. Você escolhe um de três tipos: KEYS_ONLY (apenas as chaves), INCLUDE (as chaves mais uma lista nomeada de atributos) ou ALL (o item inteiro). Mais projeção significa menos buscas na tabela base, mas armazenamento e custo de escrita mais altos.
- Uma projeção é o conjunto de atributos copiados para um índice secundário.
KEYS_ONLY— apenas as chaves da tabela e do índice. A menor, a mais barata.INCLUDE— as chaves mais uma lista nomeada de atributos extras que você escolhe.ALL— todo atributo do item. A maior; consultas nunca precisam da tabela base.- Ler um atributo que não está projetado força uma busca na tabela base para um GSI — um custo extra silencioso. (Um LSI pode buscar atributos não projetados para você, com custo de leitura extra.)
- Mais projeção = mais armazenamento + mais custo de escrita, já que toda escrita na tabela base propaga para o índice.
O problema: o índice que faz você ler duas vezes
Digamos que você administra um suporte com um GSI que te deixa listar chamados abertos
por prioridade. Você projeta KEYS_ONLY para mantê-lo enxuto. A consulta retorna rápido —
mas só te dá os IDs dos chamados, e sua tela de fila precisa do assunto, do responsável e
da idade de cada chamado.
Então agora seu código faz uma segunda rodada de leituras contra a tabela base para hidratar cada resultado. A "uma consulta" que você projetou é na verdade uma consulta mais N gets, e a latência e o custo que você tentava economizar voltaram na hora. A projeção estava fina demais para o padrão de acesso.
O que cada tipo de projeção copia
KEYS_ONLYarmazena apenas a chave da tabela base e a chave do índice. Use-o quando a consulta só precisa saber quais itens correspondem e você buscará os detalhes em outro lugar — ou não buscará.INCLUDEarmazena as chaves mais uma lista fixa de atributos que você nomeia. O ponto ideal: projete exatamente os campos que sua consulta precisa renderizar, e nada mais.ALLcopia o item inteiro. As consultas são totalmente autossuficientes a partir do índice, ao custo de duplicar nele o armazenamento e o throughput de escrita do item inteiro.
Para a fila do suporte, INCLUDE com subject, assignee e age é a escolha certa — a
fila renderiza só a partir do índice, sem uma segunda busca e sem duplicar o grande body
do chamado no índice.
O custo que você está trocando
Todo atributo que você projeta é
armazenado uma segunda vez
e reescrito no índice sempre que o item base muda. Então uma projeção ALL generosa em
uma tabela atualizada com frequência multiplica tanto o armazenamento quanto a capacidade
de escrita. A disciplina é: projete o que a consulta lê, não "tudo, só por garantia".
Uma sutileza que vale conhecer: com um índice esparso, a projeção ainda só guarda os
itens que carregam a chave do índice — então INCLUDE/ALL em um
índice esparso permanece pequeno porque o índice em si é
pequeno. Pese o multiplicador de armazenamento e escrita da sua projeção com a
calculadora de preços do DynamoDB, e monte as
consultas do índice em si com o
construtor de expressões do DynamoDB.
Vendo uma projeção no DynoTable
O DynoTable lista cada um dos índices secundários de uma tabela e te deixa consultar direto por um deles. Rode o mesmo padrão de acesso contra a tabela base e contra um GSI e compare os resultados — os atributos ausentes no resultado do índice são exatamente os que ele não projeta, então o efeito de uma projeção fica visível sem reler a definição da tabela.

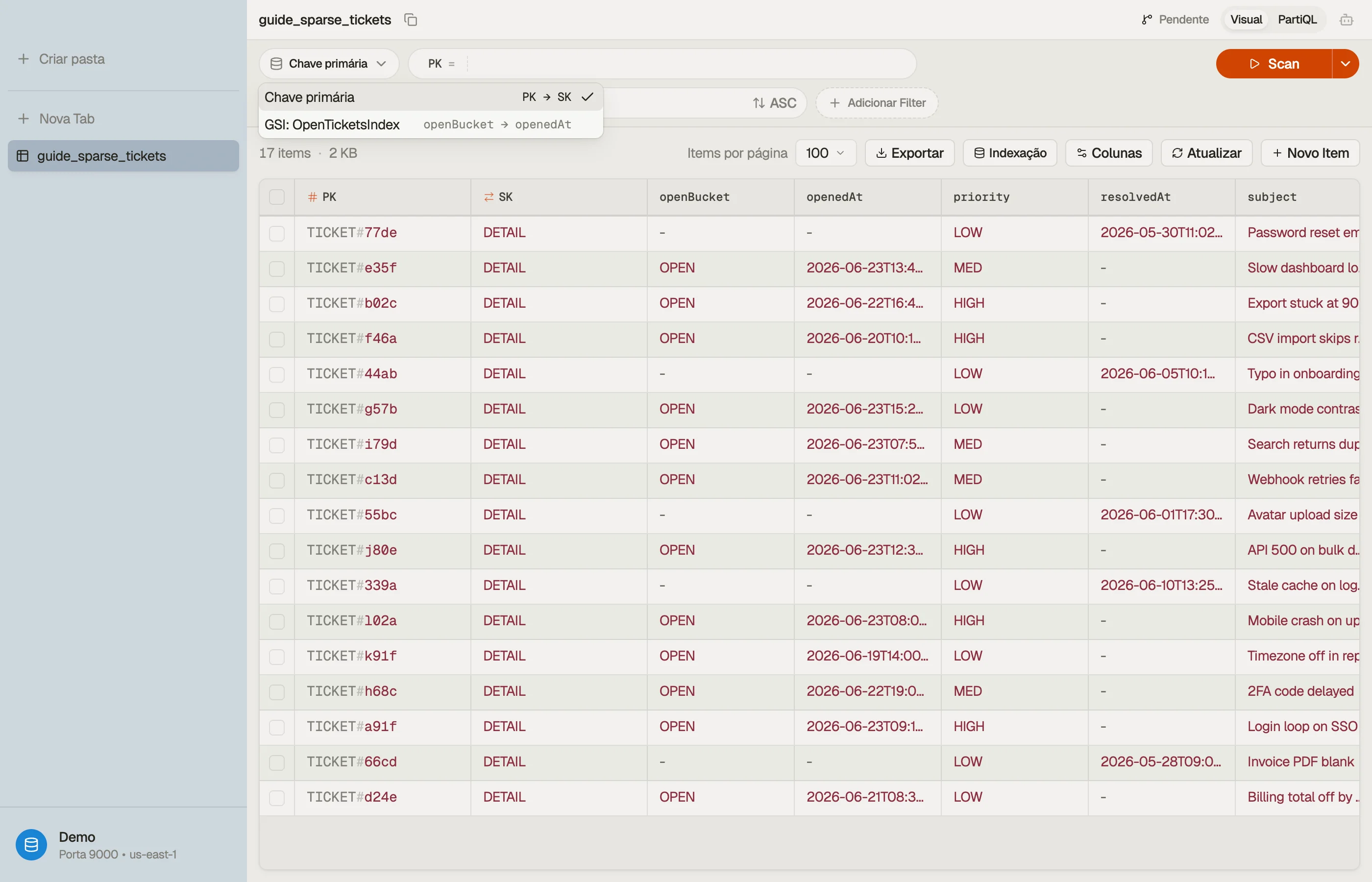

Ciladas e próximos passos
- Um atributo não projetado em um GSI significa uma busca na tabela base — projete a projeção em torno do que a consulta renderiza.
ALLraramente é de graça — duplica armazenamento e custo de escrita; useINCLUDEcomo padrão, a menos que o índice genuinamente precise de cada campo.- Projeções são em sua maioria fixas. Você não pode editar livremente a projeção de um GSI depois sem recriar o índice — escolha deliberadamente desde o início.
- Relacionado: GSI vs LSI e índices esparsos moldam quanto uma projeção realmente armazena.
Quer ver o que cada um dos seus índices realmente retorna antes de redesenhá-los? Baixe o DynoTable e consulte suas tabelas diretamente.