Estratégias de Chave de Ordenação no DynamoDB
Uma chave primária do DynamoDB é um ou dois atributos: uma chave de partição sozinha, ou uma chave de partição mais uma chave de ordenação. A chave de partição decide qual partição física contém um item.
A chave de ordenação decide a ordem dos itens dentro dessa partição — e essa
ordenação é o que torna o Query poderoso.
Escolha a chave de ordenação errada e você ainda consegue escrever dados, mas perde leituras de intervalo, ordenação e vários padrões de acesso de uma coleção.
Vindo do SQL, você recorreria a um ORDER BY ou a um índice secundário depois do
fato. No DynamoDB você assa a ordem na chave de antemão, ou não a tem.
Como funcionam as chaves de ordenação do DynamoDB?
A chave de ordenação do DynamoDB ordena os itens dentro de uma partição, para que o Query possa fazer leituras de intervalo — >=, between, begins_with — em vez de buscar um item por vez. A ordenação é a ordem de bytes na chave codificada, então projete-a (um timestamp ISO-8601, um número preenchido com zeros) para que a ordem de bytes seja igual à ordem que você quer ler.
- A chave de ordenação é o seu índice dentro da partição. Ela ordena a coleção de
itens em disco, então o
Querypode fazer leituras de intervalo (>=,between,begins_with) em vez de um únicoGetItem. - A ordenação é a ordem de bytes na chave codificada. Projete a chave para que a
ordem de bytes seja igual à ordem que você quer ler — um timestamp ISO-8601, um
número preenchido com zeros, nunca um UUID cru ou
6/23/2026. - Uma chave de ordenação bem moldada serve muitos padrões de acesso. Uma chave
composta (
EVT#<timestamp>) é um prefixo e um intervalo ao mesmo tempo — sem GSI necessário. - Direção é de graça.
ScanIndexForward = falselê do mais novo primeiro pelo mesmo custo; não armazene timestamps invertidos para simular isso.
Por que a chave de ordenação é a alavanca
Sem uma chave de ordenação, todo item em uma partição é endereçável apenas pela sua
chave primária completa — um GetItem no melhor caso. Adicione uma chave de ordenação
e o DynamoDB armazena os itens ordenados por ela dentro da partição, o que libera o
Query.
Isso significa condições de intervalo (>=, between), correspondência de prefixo
(begins_with), e uma flag ScanIndexForward para ler em ordem crescente ou
decrescente.
Conforme o AWS DynamoDB Developer Guide, todos os itens que compartilham uma chave de partição formam uma coleção de itens, ordenada em disco pela chave de ordenação.
Então a chave de ordenação não é só um segundo identificador. É o índice contra o qual você consulta dentro de uma partição.
Essa ordenação é a ordem de bytes na chave de ordenação codificada: strings comparam por bytes UTF-8, números comparam numericamente. Esse único fato guia quase toda estratégia abaixo.
Se você quer que consultas de intervalo signifiquem algo, a ordem de bytes tem que corresponder à ordem que você quer ler.
Estratégia 1: torne a chave de ordenação ordenável
O erro mais comum é uma chave de ordenação que não está ordenada de forma significativa. Um UUID aleatório te dá unicidade, mas nenhuma consulta de intervalo útil — "me dê os últimos 20" se torna impossível porque a ordem de bytes é arbitrária.
Em vez disso, codifique o valor pelo qual você ordena e filtra dentro da chave de ordenação, em uma representação cuja ordem de bytes seja igual à sua ordem lógica. Para timestamps, isso significa um formato ordenável lexicograficamente: uma string ISO-8601 ou um epoch preenchido com zeros.
O ISO-8601 foi projetado para que a comparação de strings seja igual à comparação
cronológica — exatamente o que uma consulta de intervalo precisa. Evite formatos como
6/23/2026; eles ordenam errado no instante em que o mês vira.
Se você ordena por números (um contador de versão, uma pontuação), use o tipo
Number nativo do DynamoDB em vez de uma string, para que 42 ordene depois de 9
em vez de antes.
Se um número precisa viver dentro de uma chave de ordenação string composta, preencha-o com zeros até uma largura fixa.
Estratégia 2: chaves de ordenação compostas para hierarquia
Uma chave de ordenação pode codificar uma hierarquia concatenando segmentos com um
delimitador, mais comumente #. Uma condição begins_with então seleciona uma
sub-árvore inteira:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") retorna só os eventos de junho; o mais amplo
begins_with(SK, "EVENT#") retorna todos eles.
A ordem dos segmentos é uma decisão de design. Do grosso para o fino (ano → mês → dia) mantém itens relacionados contíguos, então uma leitura de intervalo permanece uma consulta barata em vez de uma dispersão pela partição.
Estratégia 3: controle a direção com ScanIndexForward
O DynamoDB armazena itens em ordem crescente de chave de ordenação e os lê assim
por padrão. Para ler do mais novo primeiro — a ordem natural para um feed de atividade
— defina ScanIndexForward = false no Query.
Essa é uma flag de tempo de leitura, não uma decisão de esquema: a mesma coleção serve os dois sentidos pelo mesmo custo. Não inverta seus timestamps (armazenando um "epoch reverso") só para conseguir leituras decrescentes.
Uma coleção de itens, armazenada uma vez em ordem crescente, lida de qualquer jeito:
Mesmos itens, mesma partição, mesmo custo — só a direção de leitura difere.
A única exceção: se você especificamente precisa que a ordem decrescente também seja a
ordem em que um índice esparso ou um cursor de paginação avança. Fora isso,
ScanIndexForward é a alavanca mais simples.
Exemplo prático: um log de auditoria com escopo de ator
Suponha que você registre eventos com timestamp produzidos por atores — usuários, serviços, chaves de API — em um produto SaaS, e tenha duas leituras:
- O fluxo de atividade de um ator, do evento mais novo primeiro.
- Os eventos de um ator dentro de uma janela de tempo (ex.: "tudo entre os dois deploys"), para uma investigação.
As duas leituras têm escopo de um único ator, então o ator é a chave de partição e o horário do evento é a chave de ordenação. Use nomes de chave genéricos para que a mesma tabela possa comportar outras entidades depois:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
O prefixo EVT# mais um timestamp ISO-8601 dá uma chave de ordenação ordenável. A
leitura 1 é Query PK = "ACTOR#u_8814" com ScanIndexForward = false para o mais novo
primeiro. A leitura 2 estreita a mesma partição com uma condição between na chave de
ordenação:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"Uma coleção, dois padrões de acesso, sem GSI — porque a chave de ordenação é tanto um
prefixo (EVT#) quanto um intervalo (o timestamp). A leitura decrescente e a leitura
de janela são os mesmos itens na mesma ordem; só os parâmetros diferem.
Construindo essa condição de chave à mão, é fácil tropeçar nos limites do between ou
no escape de palavras reservadas em nomes de atributo.
O DynamoDB Expression Builder
gera a KeyConditionExpression, os ExpressionAttributeNames e os
ExpressionAttributeValues para uma condição de chave de ordenação begins_with ou
between.
Copie-a direto para a sua chamada de SDK em vez de depurar escaping em tempo de execução.
Faça no DynoTable
Projetar uma chave de ordenação é iterativo: escreva alguns itens representativos, rode a consulta de intervalo, e verifique se as linhas voltam na ordem que você espera. Fazer isso contra uma tabela ao vivo em uma GUI bate ficar indo e voltando pelo código.

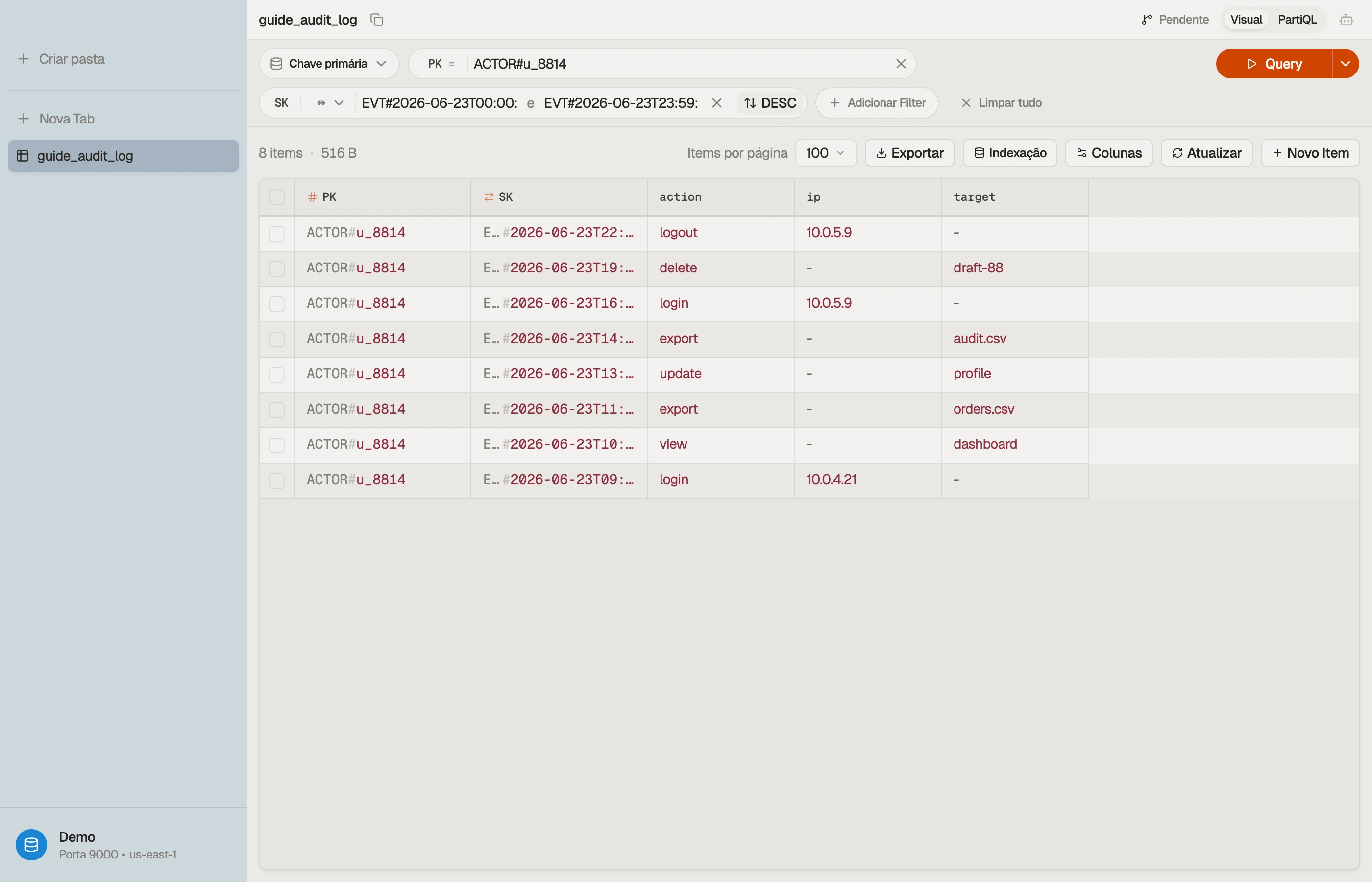

Inverta a direção de ordenação, aperte os limites do between, e veja a coleção
retornada mudar sem escrever uma linha de código — a forma mais rápida de confirmar um
design de chave de ordenação antes de comprometê-lo.
Armadilhas e próximos passos
- Chaves de ordenação devem ser únicas dentro de uma partição. Se dois eventos podem compartilhar um timestamp, anexe um desambiguador (um número de sequência ou id curto) à chave de ordenação para que a composta permaneça única.
- Uma partição quente não pode ser contornada por ordenação. Se um ator produz muito mais eventos que o resto, a chave de ordenação não te salvará — você precisa de um design de chave de partição que espalhe a carga. Veja single-table design.
- Uma segunda ordem de ordenação precisa de um segundo índice. A chave de ordenação da tabela base dá uma ordenação. Para ordenar os mesmos itens de forma diferente (por tipo de evento, digamos), adicione um GSI com uma chave de ordenação diferente — pesando os trade-offs de índice secundário local vs global.
- Não recorra a
Scanpara "ordenar depois". Ordenar no lado do cliente após umScanlê a tabela inteira e joga a ordenação fora; essa é a cilada do Scan. Empurre a ordem para a chave de ordenação em vez disso.
Quando a condição de chave estiver certa, experimente o DynoTable para modelar a coleção, rodar as consultas crescente e decrescente lado a lado, e verificar sua estratégia de chave de ordenação contra dados reais antes de ela ir para produção.