1:n-Beziehungen in DynamoDB
Eine SaaS-Control-Plane hat fast immer eine Containment-Hierarchie: ein
Workspace besitzt viele Projekte. In SQL würdest du einen Fremdschlüssel
workspace_id auf die Projekttabelle legen und JOINen.
DynamoDB hat keine Joins und keine Fremdschlüssel, also muss die Beziehung im
Key-Schema selbst leben. Richtig gemacht, wird aus "lade einen Workspace und
jedes Projekt darin" eine einzige Query statt eines Lesevorgangs plus
nachgelagertem Scan.
Wie modellierst du eine 1:n-Beziehung in DynamoDB?
Gib dem Elternteil und allen seinen Kindern denselben , damit sie eine gemeinsame bilden, und differenziere sie dann über den Sort Key. DynamoDB hat keine Joins und keine Fremdschlüssel, also lebt die Beziehung im Key-Schema selbst. Das Laden eines Elternteils plus aller Kinder wird damit zu einer einzigen Query statt eines Joins.
- Modelliere die Reads, nicht die Entitäten. Die 1:n-Beziehung existiert nur, um "liste die Projekte eines Workspace" zu bedienen — forme die Keys um diese Query herum.
- Kodiere das Elternteil in den Partition Key des Kindes. Gib dem Workspace und all seinen Projekten denselben Partition-Key-Wert, damit sie in einer Item Collection landen.
- Dann ist der List-Read eine einzige
Query. Elternteil plus eine beliebige Anzahl Kinder kommen in einem einzigen abgerechneten Aufruf zurück — kein Join, kein zweiter Round Trip. - Achte auf die Hot Partition. Ein riesiger Tenant konzentriert seinen gesamten Traffic auf eine Partition; ein gigantischer Workspace braucht womöglich einen geshardeten Key und einen Fan-out-Read.
Zuerst das Zugriffsmuster
Modellierung in DynamoDB ist zugriffsmuster-first, nicht entitäts-first — dieselbe Disziplin hinter Single-Table Design. Bevor du irgendeinen Key wählst, schreib die Reads auf, die die App tatsächlich absetzt:
- Hol die Einstellungen eines Workspace.
- Liste jedes Projekt in einem Workspace, neueste zuerst.
- Hol ein bestimmtes Projekt per id.
Die Beziehung "ein Workspace, viele Projekte" zählt nur wegen Read #2. Müsstest du nie die Projekte eines Workspace zusammen auflisten, würdest du die Beziehung gar nicht modellieren — du würdest Projekte unabhängig speichern.
Die Frage lautet also nie abstrakt "wie repräsentiere ich 1:n?". Sie lautet "welche Queries muss diese Beziehung bedienen?". Beantworte das, dann forme die Keys darum herum.
Warum ein Fremdschlüssel hier nicht hilft
In DynamoDB zielt jedes GetItem und jede Query auf einen Partition Key,
und der Dienst hasht diesen Key, um die Partition mit dem Item zu finden.
AWS sagt es direkt in den Core-Components-Docs: Der Partition-Key-Wert ist die Eingabe einer internen Hashfunktion, die entscheidet, wo Daten liegen.
Diese hashbasierte Platzierung ist das Erbe des ursprünglichen Papers von 2007, Dynamo: Amazon's Highly Available Key-value Store, in dem Consistent Hashing Keys über Nodes verteilt.
Ein bloßes workspace_id-Attribut auf einem Projekt-Item ist für diese
Maschinerie unsichtbar — DynamoDB kann ihm nicht "folgen".
Um verwandte Items in einer Anfrage zu holen, muss die Identität des Elternteils
in den Partition Key des Projekts kodiert sein, sodass alle Items eines
Workspace auf dieselbe Partition hashen und eine Query sie durchstreifen kann.
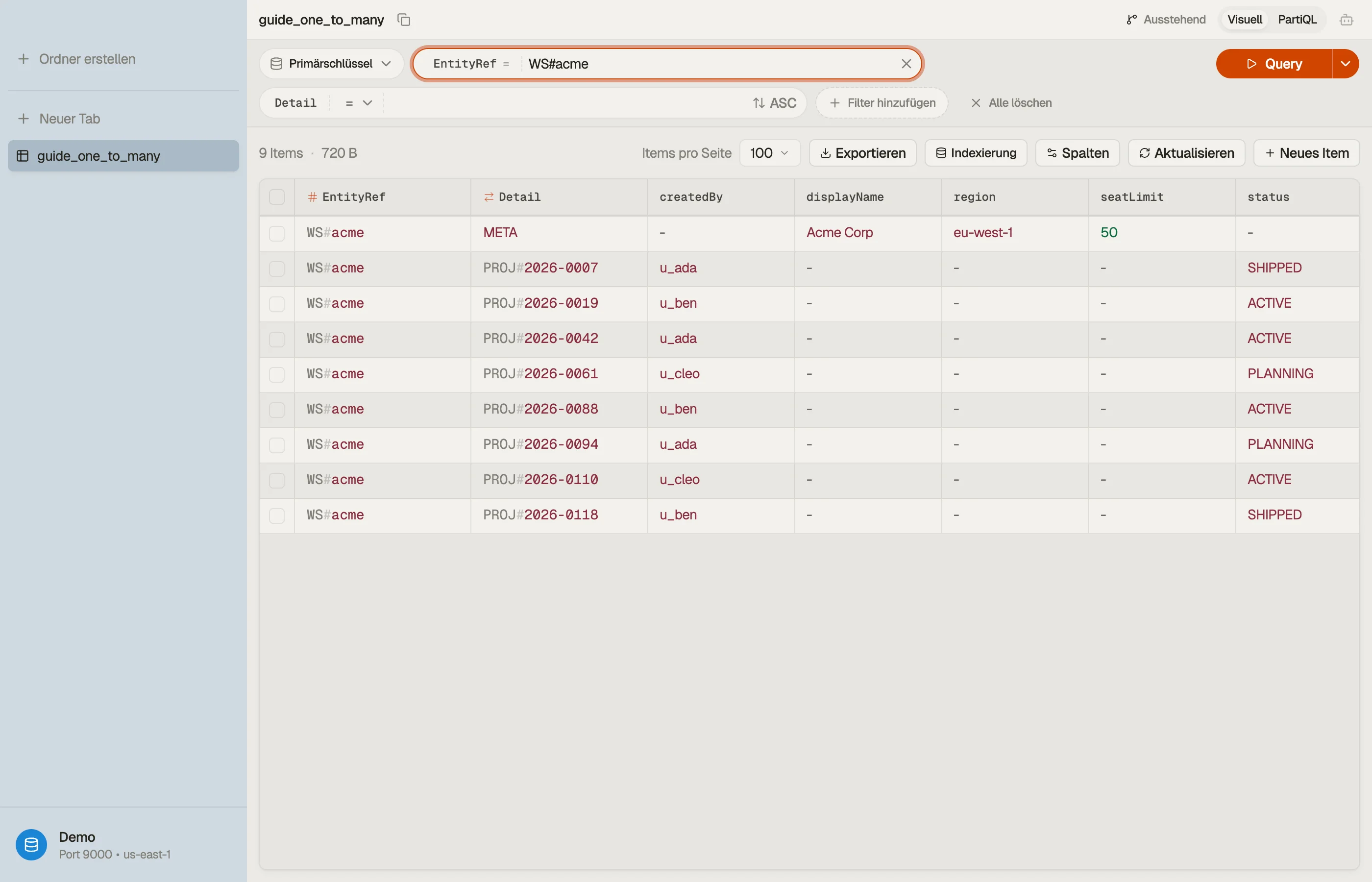
Durchgespieltes Beispiel: Workspaces und Projekte
Verwende ein generisches, überladenes Key-Schema. Nenne den Partition Key
EntityRef und den Sort Key Detail. Die Workspace-Identität wandert in
EntityRef für sowohl das Workspace-Item als auch jedes Projekt darunter:
| EntityRef | Detail | attributes |
|---|---|---|
| WS#acme | META | displayName, region, seatLimit |
| WS#acme | PROJ#2026-0007 | title, status, createdBy |
| WS#acme | PROJ#2026-0042 | title, status, createdBy |
| WS#acme | PROJ#2026-0118 | title, status, createdBy |
| WS#globex | META | displayName, region, seatLimit |
| WS#globex | PROJ#2026-0009 | title, status, createdBy |
Der Workspace und all seine Projekte teilen sich EntityRef = "WS#acme", also
bilden sie eine einzige Item Collection, die gemeinsam auf einer Partition
lebt.
Der Sort Key Detail trennt sie: META ist der Workspace-Datensatz, und jedes
Projekt trägt einen PROJ#-Präfix mit einer nullgepaddeten, zeitlich geordneten
id, damit Projekte natürlich sortieren.
Visuell stapeln sich Elternteil und Kinder innerhalb einer Partition, geordnet nach dem Sort Key:
Eine Query auf EntityRef = "WS#acme" streift den ganzen Stapel — Elternteil
plus jedes Kind — in einem einzigen Read.
Jetzt kollabiert jedes der drei Zugriffsmuster zu einem Aufruf:
- Workspace-Einstellungen —
GetItem(EntityRef="WS#acme", Detail="META"). - Projekte neueste-zuerst auflisten —
Query(EntityRef="WS#acme")mitDetail begins_with "PROJ#", absteigend ausgeführt (ScanIndexForward = false). - Ein Projekt —
GetItem(EntityRef="WS#acme", Detail="PROJ#2026-0042").
Das zweite ist der ganze Sinn: Elternteil und eine beliebige Anzahl Kinder kommen
in einer abgerechneten Query zurück, kein Join und kein zweiter Round Trip.
Das ist der Zug, den du mit einem Fremdschlüssel-Attribut und einem Scan nicht
machen kannst.
Diese begins_with-Bedingung von Hand zu schreiben ist fummelig — die Syntax von
Key-Condition und Projection-Expression beißt.
Der DynamoDB Expression Builder generiert
die KeyConditionExpression, die #name/:value-Platzhalter-Maps und ein
lauffertiges SDK-Snippet, damit du nicht mit der Grammatik kämpfst:
KeyConditionExpression "#er = :er AND begins_with(#d, :p)"
ExpressionAttributeNames { "#er": "EntityRef", "#d": "Detail" }
ExpressionAttributeValues { ":er": "WS#acme", ":p": "PROJ#" }Die Item Collection in DynoTable inspizieren
Der Lohn dieses Layouts ist visuell: jede Zeile, die sich ein EntityRef teilt,
ist der Workspace plus seine Kinder, direkt nebeneinander.
DynoTable gruppiert sie so, dass du die 1:n-Beziehung als einen zusammenhängenden Block siehst, statt sie dir über getrennte Tabellen hinweg zu erraten.


Fallstricke und die alternative Form
Ein paar Dinge, auf die du achten solltest:
- Hot Partitions. Jedes Item eines Workspace lebt auf einer Partition, also
konzentriert ein einzelner sehr großer oder sehr beschäftigter Tenant den
Traffic. Das von AWS beschriebene Verhalten der
Adaptive Capacity
fängt moderate Schieflage ab, aber ein Workspace mit Millionen Projekten braucht
womöglich einen geshardeten Key (z. B.
WS#acme#01 … #10) und einen Fan-out-Read. - Größe der Item Collection. Mit einem Local Secondary Index ist die Item Collection einer einzelnen Partition auf 10 GB gedeckelt; ohne LSI gibt es kein solches Limit. Wenn du hier zwischen Indextypen abwägst, siehe GSI vs. LSI.
- Greif zu
Query, nie zuScan. Das ganze Design existiert, damit du eine Partition mitQuerylesen kannst. Auf einen gefiltertenScanzurückzufallen, um "die Projekte eines Workspace zu finden", wirft das Modell weg und liest die ganze Tabelle — die Falle, behandelt in Query vs. Scan.
Wenn du wirklich Projekte über Workspaces hinweg auflisten musst (etwa alle
status = ACTIVE-Projekte global), kann die Basistabelle das nicht beantworten —
ihr Partition Key ist workspace-scoped.
Das ist ein Job für einen Secondary Index, der Projekte auf einem anderen Attribut neu partitioniert, nicht für das Umformen dieser Beziehung.
Nächste Schritte
Modelliere die Zugriffsmuster, kodiere das Elternteil in den Partition Key des
Kindes, und der 1:n-Read ist eine einzige Query. Baue und validiere die
Key-Condition mit dem
DynamoDB Expression Builder.
Dann lade DynoTable herunter, um dieses Schema zu laden, die Item Collection workspace→projects live zu durchstöbern und zu bestätigen, dass jede Query genau einen Read macht.