Sort-Key-Strategien für DynamoDB
Ein DynamoDB-Primary-Key ist ein oder zwei Attribute: ein Partition Key allein oder ein Partition Key plus ein Sort Key. Der Partition Key entscheidet, welche physische Partition ein Item hält.
Der Sort Key entscheidet die Reihenfolge der Items innerhalb dieser Partition
— und diese Reihenfolge ist es, die Query mächtig macht.
Wähle den falschen Sort Key, und du kannst trotzdem Daten schreiben, aber du verlierst Range-Reads, Ordnung und mehrere Zugriffsmuster aus einer Collection.
Aus SQL kommend würdest du nachträglich zu einem ORDER BY oder einem Secondary
Index greifen. In DynamoDB backst du die Ordnung von vornherein in den Key, oder
du bekommst sie nicht.
Wie funktionieren Sort Keys in DynamoDB?
Ein DynamoDB-Sort-Key ordnet Items innerhalb einer Partition, sodass Query Range-Reads durchführen kann — >=, between, begins_with — statt Items einzeln zu holen. Die Ordnung ist Byte-Ordnung auf dem kodierten Key; entwirf ihn (ein ISO-8601-Zeitstempel, eine nullgepaddete Zahl) so, dass Byte-Ordnung der Reihenfolge entspricht, die du lesen willst.
- Der Sort Key ist dein In-Partition-Index. Er ordnet die Item Collection auf
der Platte, sodass
QueryRange-Reads (>=,between,begins_with) statt eines einzelnenGetItemmachen kann. - Ordnung ist Byte-Ordnung auf dem kodierten Key. Entwirf den Key so, dass
Byte-Ordnung der Reihenfolge entspricht, die du lesen willst — ein
ISO-8601-Zeitstempel, eine nullgepaddete Zahl, nie eine rohe UUID oder
6/23/2026. - Ein gut geformter Sort Key bedient viele Zugriffsmuster. Ein zusammengesetzter
Key (
EVT#<timestamp>) ist Präfix und Range zugleich — kein GSI nötig. - Richtung ist gratis.
ScanIndexForward = falseliest neueste-zuerst zu denselben Kosten; speichere keine umgedrehten Zeitstempel, um das zu faken.
Warum der Sort Key der Hebel ist
Ohne Sort Key ist jedes Item in einer Partition nur über seinen vollen Primary Key
adressierbar — ein GetItem bestenfalls. Füge einen Sort Key hinzu, und DynamoDB
speichert Items innerhalb der Partition danach sortiert, was Query
freischaltet.
Das bedeutet Range-Bedingungen (>=, between), Präfix-Matching
(begins_with) und ein ScanIndexForward-Flag, um aufsteigend oder absteigend zu
lesen.
Laut AWS DynamoDB Developer Guide bilden alle Items, die sich einen Partition Key teilen, eine Item Collection, auf der Platte nach Sort Key geordnet.
Der Sort Key ist also nicht nur ein zweiter Identifier. Er ist der Index, gegen den du innerhalb einer Partition abfragst.
Diese Ordnung ist Byte-Ordnung auf dem kodierten Sort Key: Strings vergleichen nach UTF-8-Bytes, Zahlen vergleichen numerisch. Diese eine Tatsache treibt fast jede Strategie unten.
Wenn Range-Queries etwas bedeuten sollen, muss Byte-Ordnung der Reihenfolge entsprechen, die du lesen willst.
Strategie 1: mach den Sort Key sortierbar
Der häufigste Fehler ist ein Sort Key, der nicht sinnvoll geordnet ist. Eine zufällige UUID gibt dir Eindeutigkeit, aber keine nützliche Range-Query — "gib mir die letzten 20" wird unmöglich, weil Byte-Ordnung willkürlich ist.
Kodiere stattdessen den Wert, nach dem du sortierst und filterst, in den Sort Key, in einer Repräsentation, deren Byte-Ordnung ihrer logischen Ordnung entspricht. Für Zeitstempel heißt das ein lexikografisch sortierbares Format: ein ISO-8601-String oder ein nullgepaddetes Epoch.
ISO-8601 wurde so entworfen, dass String-Vergleich chronologischem Vergleich
entspricht — genau das, was eine Range-Query braucht. Vermeide Formate wie
6/23/2026; sie sortieren falsch, sobald der Monat umspringt.
Wenn du nach Zahlen sortierst (ein Versionszähler, ein Score), verwende DynamoDBs
nativen Number-Typ statt eines Strings, sodass 42 nach 9 sortiert statt
davor.
Wenn eine Zahl in einem zusammengesetzten String-Sort-Key leben muss, null-padde sie auf eine feste Breite.
Strategie 2: zusammengesetzte Sort Keys für Hierarchie
Ein Sort Key kann eine Hierarchie kodieren, indem er Segmente mit einem Trenner
verkettet, am häufigsten #. Eine begins_with-Bedingung wählt dann einen ganzen
Teilbaum:
| SK |
|---|
| EVENT#2026-06#01#login |
| EVENT#2026-06#03#export |
| EVENT#2026-07#02#login |
begins_with(SK, "EVENT#2026-06#") gibt nur die Events vom Juni zurück; das
breitere begins_with(SK, "EVENT#") gibt sie alle zurück.
Die Segment-Reihenfolge ist eine Design-Entscheidung. Grob-zu-fein (Jahr → Monat → Tag) hält verwandte Items zusammenhängend, sodass ein Range-Read eine billige Query bleibt statt einer Streuung über die Partition.
Strategie 3: Richtung mit ScanIndexForward steuern
DynamoDB speichert Items in aufsteigender Sort-Key-Reihenfolge und liest sie
standardmäßig so. Um neueste-zuerst zu lesen — die natürliche Reihenfolge für
einen Activity-Feed — setze ScanIndexForward = false auf der Query.
Das ist ein Lesezeit-Flag, keine Schema-Entscheidung: dieselbe Collection bedient beide Richtungen zu denselben Kosten. Invertiere deine Zeitstempel nicht (speichere kein "Reverse-Epoch") nur, um absteigende Reads zu bekommen.
Eine Item Collection, einmal in aufsteigender Reihenfolge gespeichert, in beide Richtungen gelesen:
Dieselben Items, dieselbe Partition, dieselben Kosten — nur die Leserichtung unterscheidet sich.
Die eine Ausnahme: wenn du speziell die absteigende Reihenfolge auch als die
Reihenfolge brauchst, in der ein Sparse Index oder ein Pagination-Cursor
voranschreitet. Abgesehen davon ist ScanIndexForward der einfachere Hebel.
Durchgespieltes Beispiel: ein actor-scoped Audit-Log
Angenommen, du zeichnest zeitgestempelte Events auf, die von Akteuren — Usern, Services, API-Keys — in einem SaaS-Produkt produziert werden, und du hast zwei Reads:
- Den Activity-Stream für einen Akteur, neuestes Event zuerst.
- Die Events eines Akteurs innerhalb eines Zeitfensters (z. B. "alles zwischen den beiden Deploys"), für eine Untersuchung.
Beide Reads sind auf einen einzelnen Akteur gescopet, also ist der Akteur der Partition Key und die Event-Zeit der Sort Key. Verwende generische Key-Namen, damit dieselbe Tabelle später andere Entitäten halten kann:
| PK | SK | attributes |
|---|---|---|
| ACTOR#u_8814 | EVT#2026-06-23T09:12:04Z | action=login, ip, ua |
| ACTOR#u_8814 | EVT#2026-06-23T14:05:11Z | action=export, target |
| ACTOR#u_8814 | EVT#2026-06-24T08:40:55Z | action=login, ip, ua |
| ACTOR#svc_billing | EVT#2026-06-23T00:00:00Z | action=invoice.run |
Der EVT#-Präfix plus ein ISO-8601-Zeitstempel ergibt einen sortierbaren Sort
Key. Read 1 ist Query PK = "ACTOR#u_8814" mit ScanIndexForward = false für
neueste-zuerst. Read 2 engt dieselbe Partition mit einer between-Bedingung auf
dem Sort Key ein:
Query
PK = "ACTOR#u_8814"
AND SK BETWEEN "EVT#2026-06-23T00:00:00Z"
AND "EVT#2026-06-23T23:59:59Z"Eine Collection, zwei Zugriffsmuster, kein GSI — weil der Sort Key sowohl ein
Präfix (EVT#) als auch eine Range (der Zeitstempel) ist. Der absteigende Read
und der Fenster-Read sind dieselben Items in derselben Reihenfolge; nur die
Parameter unterscheiden sich.
Diese Key-Condition von Hand zu bauen, ist es leicht, die between-Grenzen oder
das Reservierte-Wort-Escaping auf Attributnamen zu vermasseln.
Der DynamoDB Expression Builder
generiert die KeyConditionExpression, die ExpressionAttributeNames und die
ExpressionAttributeValues für eine begins_with- oder between-Sort-Key-Bedingung.
Kopiere ihn direkt in deinen SDK-Aufruf, statt Escaping zur Laufzeit zu debuggen.
Mach es in DynoTable
Einen Sort Key zu entwerfen ist iterativ: schreib ein paar repräsentative Items, führe die Range-Query aus und prüfe, dass die Zeilen in der erwarteten Reihenfolge zurückkommen. Das gegen eine Live-Tabelle in einer GUI zu machen, schlägt das Round-Tripping durch Code.

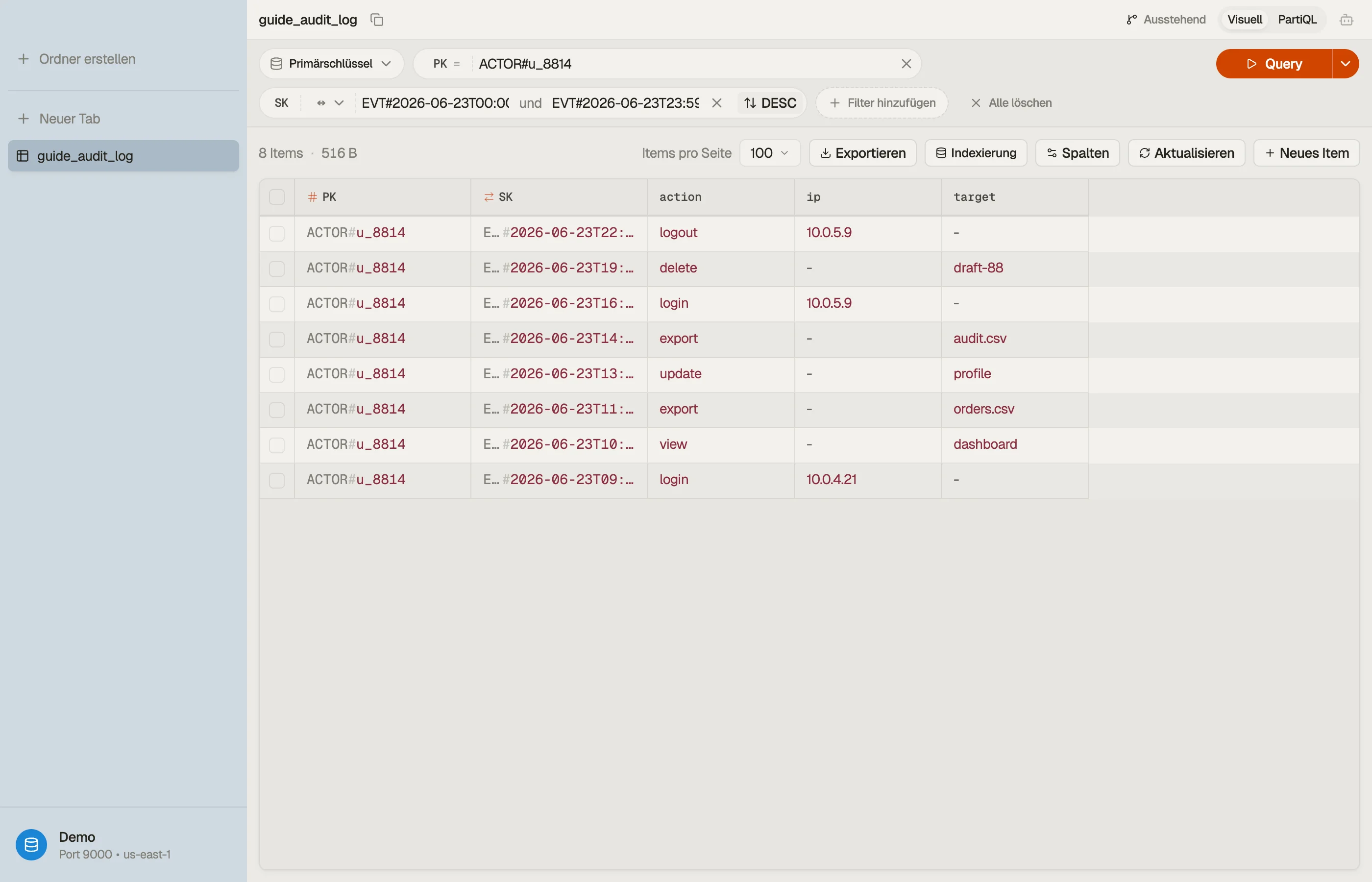

Dreh die Sortierrichtung um, zieh die between-Grenzen enger und sieh zu, wie sich
die zurückgegebene Collection ändert, ohne eine Zeile Code zu schreiben — der
schnellste Weg, ein Sort-Key-Design zu bestätigen, bevor du dich festlegst.
Fallstricke und nächste Schritte
- Sort Keys müssen innerhalb einer Partition eindeutig sein. Wenn zwei Events sich einen Zeitstempel teilen können, häng einen Disambiguator (eine Sequenznummer oder eine kurze id) an den Sort Key, damit das Composite eindeutig bleibt.
- Eine Hot Partition lässt sich nicht wegsortieren. Wenn ein Akteur weit mehr Events produziert als der Rest, rettet dich der Sort Key nicht — du brauchst ein Partition-Key-Design, das die Last streut. Siehe Single-Table Design.
- Eine zweite Sortierreihenfolge braucht einen zweiten Index. Der Sort Key der Basistabelle gibt eine Ordnung. Um dieselben Items anders zu ordnen (etwa nach Event-Typ), füge einen GSI mit einem anderen Sort Key hinzu — und wäge die Trade-offs von Local vs. Global Secondary Index ab.
- Greif nicht zu
Scan, um "später zu sortieren". Clientseitig nach einemScanzu sortieren liest die ganze Tabelle und wirft Ordnung weg; das ist die Scan-Falle. Drück die Ordnung stattdessen in den Sort Key.
Wenn die Key-Condition stimmt, probier DynoTable, um die Collection zu modellieren, die aufsteigenden und absteigenden Queries nebeneinander auszuführen und deine Sort-Key-Strategie gegen echte Daten zu verifizieren, bevor sie ausgeliefert wird.