Das DynamoDB-Adjacency-List-Muster
Ein Graph ist nur Knoten und Kanten, und das Adjacency-List-Muster speichert
beide als einfache Items in einer Tabelle. Jede Kante wird zu einer Zeile, deren
Partition Key der Quellknoten und deren Sort Key das Ziel ist. Eine Partition
abzufragen listet jeden Nachbarn auf — der DynamoDB-Ersatz für einen JOIN über
eine Join-Tabelle.
Was ist das DynamoDB-Adjacency-List-Muster?
Das Adjacency-List-Muster modelliert einen Graphen als Edge-Items in einer Tabelle: Jede Beziehung (A folgt B) ist eine Zeile, die mit der Quelle auf dem Partition Key und dem Ziel auf dem Sort Key verschlüsselt ist. Eine Partition abzufragen listet jeden Nachbarn auf, und ein umgedrehter GSI kehrt die Beziehung um — keine Joins, keine Scans, beide Richtungen in einem einzigen Query.
- Kanten sind Items. Modelliere jede Beziehung (User A folgt User B) als eigenes Item, verschlüsselt mit der Quelle auf dem Partition Key, dem Ziel auf dem Sort Key.
- Eine Richtung ist kostenlos; die andere braucht einen GSI. Die Basistabelle beantwortet „wem folgt A?". Ein umgedrehter Index beantwortet „wer folgt A?".
- Keine Joins, keine Scans. Beide Richtungen sind ein einziger
Querygegen eine bekannte Partition — nie ein Full-Table-Scan. - Es ist das Many-to-Many-Primitiv. Follows, Mitgliedschaften, Likes, Freundschaften — jeder Graph, in dem eine Entität mit vielen anderen verbunden ist, passt in diese Form.
Rahme es als Zugriffsmuster
Aus SQL kommend ist ein Follow-Graph eine Join-Tabelle: follows(follower_id, followee_id). Um die Follower von jemandem aufzulisten, indexierst du eine Spalte;
um aufzulisten, wem sie folgen, indexierst du die andere. DynamoDB hat keine Joins,
also gestaltest du die Keys so, dass sie jeden Lesevorgang direkt bedienen.
Schreib zuerst die Lesevorgänge auf. Für einen sozialen Follow-Graphen:
- Wem folgt User A? (seine Following-Liste)
- Wer folgt User A? (seine Follower-Liste)
- Folgt A B? (ein einzelner Point-Lookup)
Die Keys existieren nur, um diese Liste zu beantworten. Mach sie richtig, und jeder
Lesevorgang ist ein Query oder GetItem.
Modelliere Kanten als Items
Verwende generische Key-Namen, damit die Tabelle mehr als einen Entitätstyp halten kann, und kodiere den Knotentyp in den Wert. Eine Follow-Kante sieht so aus:
| PK | SK | createdAt | edgeType |
|---|---|---|---|
| ACTOR#alice | TARGET#bob | 1718900000 | FOLLOWS |
| ACTOR#alice | TARGET#carol | 1718900100 | FOLLOWS |
| ACTOR#dave | TARGET#bob | 1718900200 | FOLLOWS |
PK = ACTOR#alice ist die Quelle der Kante; SK = TARGET#bob ist, wem sie folgt.
Ein Query PK = "ACTOR#alice" liefert jeden Account, dem Alice folgt, in einem
abgerechneten Lesevorgang — ihre gesamte Following-Liste, keine Joins.
Jede Kante wird einmal geschrieben, in der Richtung „wem ich folge". Die umgekehrte Richtung („wer folgt mir") ist der Teil, den die Basistabelle nicht beantworten kann — noch nicht.
Durchlaufe die andere Richtung mit einem GSI
Die Basistabelle ist quell-zuerst verschlüsselt, also kann sie „wer folgt Bob?" nicht beantworten, ohne zu scannen. Füge einen Global Secondary Index hinzu, der die Keys umdreht: Projiziere das Ziel auf den Partition Key des Index und die Quelle auf den Sort Key des Index.
| GSI1PK | GSI1SK | (base item) | |
|---|---|---|---|
| TARGET#bob | ACTOR#alice | ACTOR#alice → TARGET#bob | |
| TARGET#bob | ACTOR#dave | ACTOR#dave | → TARGET#bob |
| TARGET#carol | ACTOR#alice | ACTOR#alice → TARGET#carol |
Jetzt listet Query GSI1 WHERE GSI1PK = "TARGET#bob" alle auf, die Bob folgen —
alice und dave — in einem Lesevorgang. Dasselbe Edge-Item bedient beide
Richtungen: Die Basistabelle ist Following, der Index ist Follower. Du schreibst
jede Kante einmal und bekommst beide Queries kostenlos.
Das ist genau das Muster, das AWS in seinem DynamoDB-Best-Practices-Guide für die Modellierung von Many-to-Many-Beziehungen und Graphdaten dokumentiert — speichere Kanten als Items, dann nutze einen GSI, um die Beziehung umzukehren.
Prüfe eine einzelne Kante günstig
„Folgt Alice Bob?" braucht keine der beiden Listen. Weil die Kante mit
PK = ACTOR#alice, SK = TARGET#bob verschlüsselt ist, ist es ein direktes
GetItem — der günstigste Lesevorgang, den DynamoDB bietet, kein Query, kein
Index.
Um den Follow idempotent zu schreiben und Doppelzählung zu vermeiden, sichere das
PutItem mit einer Bedingung ab, dass die Kante noch nicht existiert:
attribute_not_exists(PK)Du kannst diese Bedingung — und die marshalled Key-Werte — mit dem
DynamoDB Expression Builder zusammensetzen,
statt die ConditionExpression und ExpressionAttributeValues von Hand zu
schreiben.
Mach es in DynoTable
Wenn du die Tabelle durchsuchst, stapeln sich die Kanten eines Akteurs unter einem einzigen Partition Key als eine Item Collection, und der Wechsel zur GSI-Ansicht zeigt die umgekehrte Follower-Liste — die beiden Hälften der Beziehung nebeneinander.

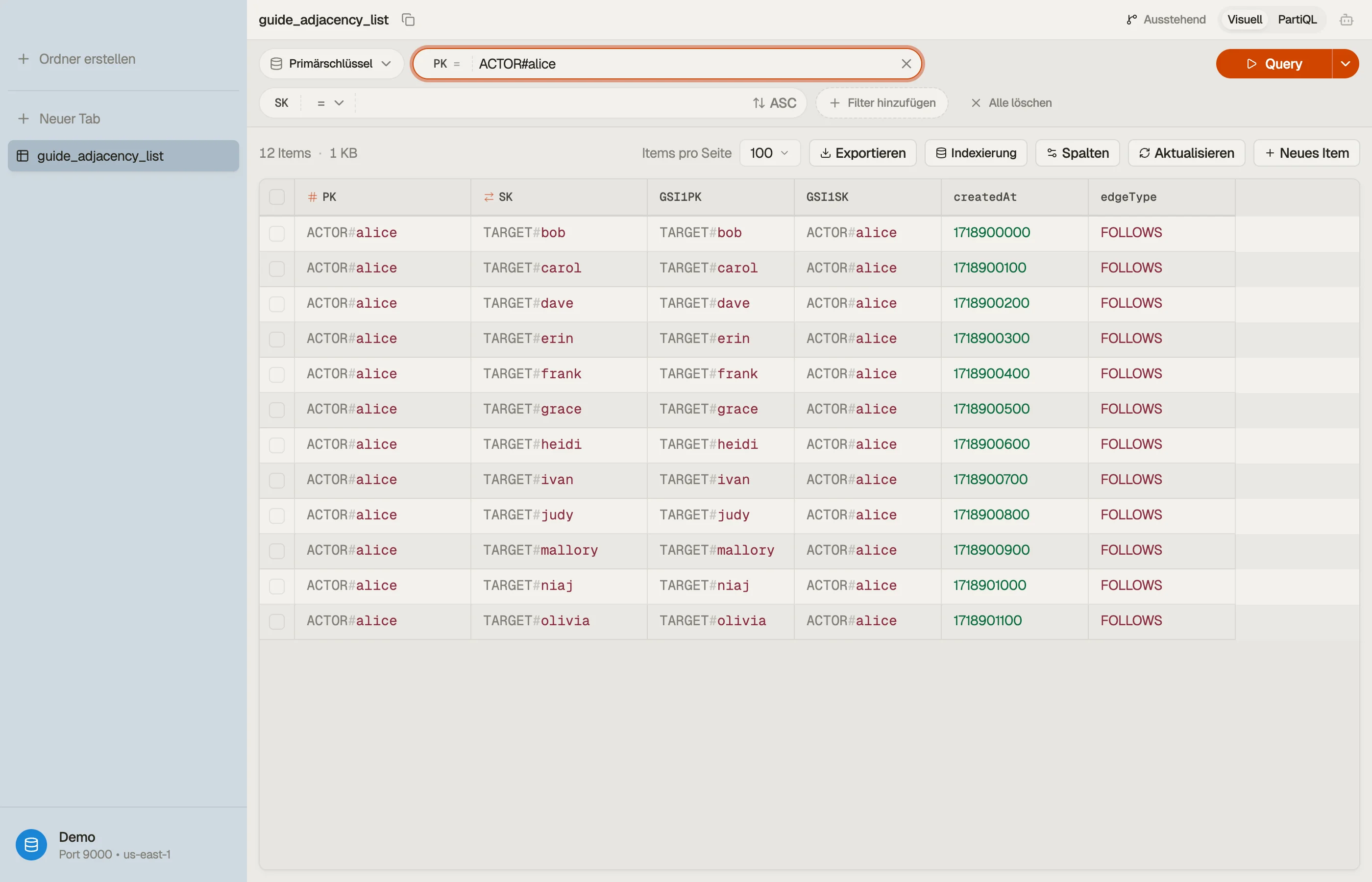

Fallstricke
Die Promi-Partition. Ein User mit Millionen von Followern konzentriert jede
Follower-Kante unter einer GSI1PK = TARGET#<star>-Partition. Lesevorgänge dieser
Collection sind paginiert und können heißlaufen. Für fan-out-lastige Graphen sharde
den Hot Key (z. B. TARGET#bob#0..N) oder denormalisiere Zähler, damit du nicht die
ganze Liste neu lesen musst.
Zähler auf der Kante speichern. Ein Follower-Zähler ist keine Kante — leite ihn nicht ab, indem du die ganze Partition bei jedem Profilaufruf liest und zählst. Halte ein Zähler-Attribut auf dem User-Item und aktualisiere es transaktional zusammen mit der Kante.
Vergiss nicht: Der Reverse-Write wird hier nicht gebraucht. Eine klassische Adjacency-List-Variante schreibt die Kante zweimal mit vertauschten IDs. Mit einem Flip-Key-GSI schreibst du sie einmal und lässt den Index die Umkehrung materialisieren — weniger Schreibvorgänge, keine Drift zwischen den beiden Kopien.
Nächste Schritte
Die Adjacency List ist der Beziehungs-Baustein des
Single-Table-Designs; der umkehrende Index ist ein
GSI, kein LSI, weil sich der Partition Key ändert. Und jeder
Lesevorgang hier ist ein Query oder GetItem auf einem bekannten Key — nie der
Scan-Footgun.
Baue die Bedingungs- und Key-Ausdrücke mit dem DynamoDB Expression Builder, und lade DynoTable herunter, um einen Follow-Graphen gegen deine eigene Tabelle zu modellieren und zu beobachten, wie sich beide Richtungen in einem Lesevorgang auflösen.