Das DynamoDB-Item-Größenlimit (400 KB)
Ein einzelnes DynamoDB-Item kann höchstens 400 KB an Daten halten. Kommst du von
MongoDB (16-MB-Dokumente) oder einer relationalen Zeile ohne praktisches Limit, wirkt
diese Decke niedrig — und du entdeckst sie meist auf die harte Tour, wenn ein Write,
der monatelang funktionierte, plötzlich mit einer ValidationException scheitert,
weil ein Item endlich zu groß wurde.
Das Limit ist nicht willkürlich, und es ist kein Kontingent, das du anheben kannst. Es ist eine Modellierungs-Beschränkung, und die Items, die es treffen, sagen dir meist, dass die Daten falsch modelliert wurden.
Wie groß darf ein Item in DynamoDB maximal sein?
DynamoDB begrenzt ein einzelnes Item auf 400 KB — ein hartes Limit, das du nicht anheben kannst. Die Größe zählt Attributnamen und Werte zusammen, einschließlich jedes verschachtelten Listen-, Map- und Set-Elements. Items erreichen es meist durch unbegrenztes Wachstum, etwa eine ständig wachsende eingebettete Liste; der Fix ist Modellierung, das Aufspalten der Collection in eigene Items, nicht Kompression.
- 400 KB pro Item, hartes Limit. Nicht anpassbar, kein weiches Kontingent.
- Größe = Attributnamen + Werte, zusammen. Lange Attributnamen zählen, auf jedem Item.
- Verschachtelung und Sets zählen auch. Listen, Maps und ihre verschachtelten Werte summieren sich alle.
- Die übliche Ursache ist unbegrenztes Wachstum — eine Liste, die ohne Grenze auf einem Eltern-Item wächst, einzubetten.
- Der Fix ist Modellierung, nicht Kompression. Spalte die wachsende Collection in eigene Items unter einem gemeinsamen Partition Key auf.
Das Problem: das Item, das ewig wächst
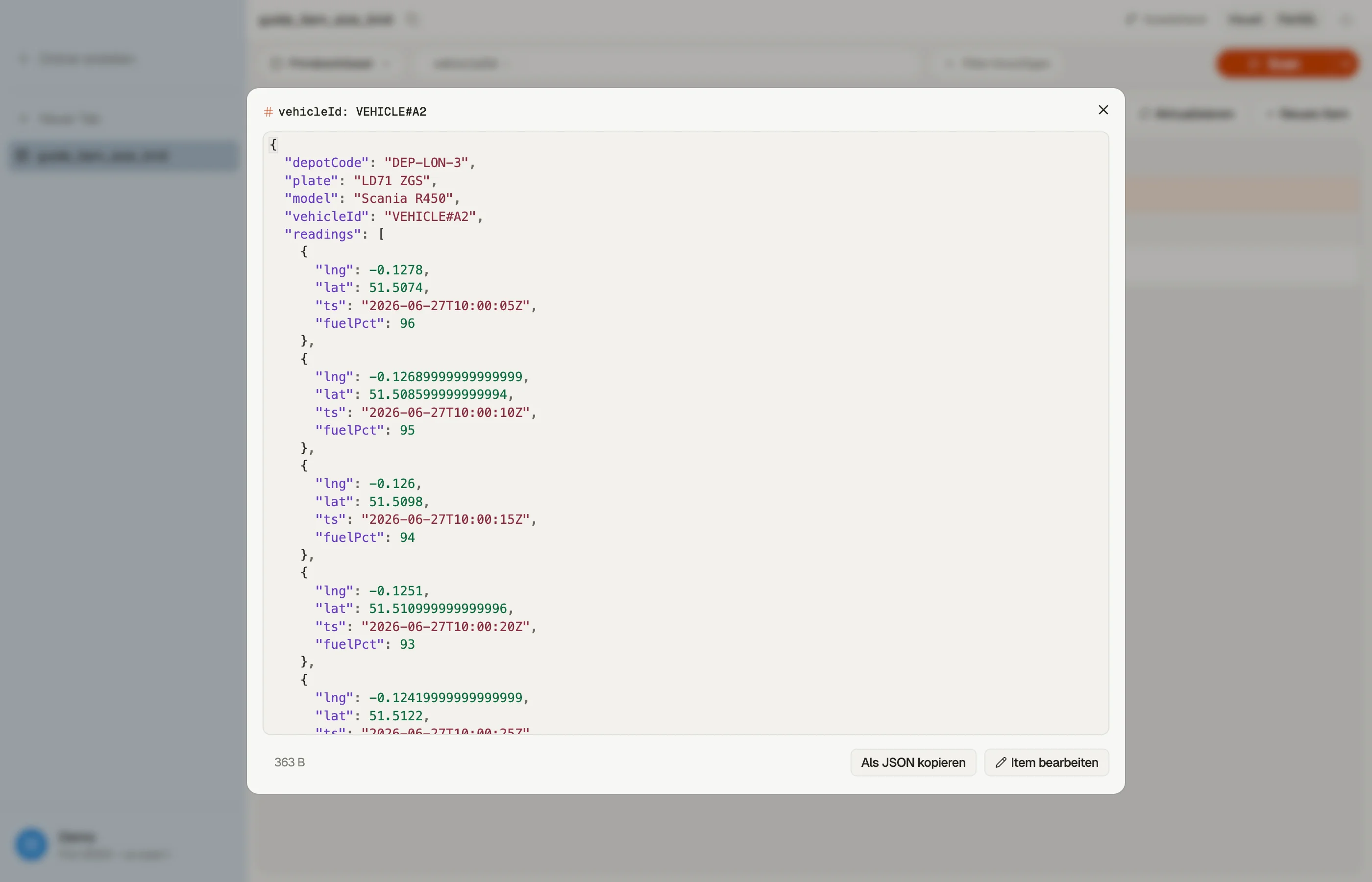
Sagen wir, du verfolgst eine Fahrzeugflotte und entscheidest, die Telemetrie-Messwerte jedes Fahrzeugs als Liste auf dem Fahrzeug-Item zu speichern:
PK: VEHICLE#A1 readings: [ {ts, lat, lng, fuel}, {ts, lat, lng, fuel}, ... ]Ein, zwei Tage lang ist das in Ordnung. Aber die Messwerte treffen alle paar Sekunden ein und hören nie auf, also wächst die Liste unbegrenzt. Irgendwann überschreitet ein einzelnes Fahrzeug-Item 400 KB und jeder Write darauf scheitert — du kannst für dieses Fahrzeug überhaupt keine Telemetrie mehr aufzeichnen, weil jedes Update das gesamte (nun übergroße) Item neu schreibt.
Der Bug ist nicht das Größenlimit. Es ist, eine unbegrenzte Eins-zu-viele-Beziehung als eingebettete Liste zu modellieren. Das funktioniert nur, wenn die "viele"-Seite begrenzt und klein ist.
Was tatsächlich auf die 400 KB zählt
DynamoDB misst die Gesamtgröße des Items als Summe aus:
- Jedem Attributnamen, UTF-8-kodiert. Ein 20 Zeichen langer Name, über Millionen von Items wiederholt, ist sowohl Größe als auch Speicher, den du bezahlst — deshalb halten erfahrene Modellierer Attributnamen kurz.
- Jedem Attributwert. Strings und Binärdaten nach ihrer Byte-Länge; Zahlen nach einer kompakten Kodierung; Booleans und Nulls nach einem winzigen Fixkosten-Anteil.
- Der verschachtelten Struktur. Eine Liste oder Map zählt ihren eigenen Overhead plus die Größe jedes Elements und Keys darin, bis ganz nach unten.
Es gibt kein separates Limit pro Attribut, um das herum du planen müsstest — es ist das ganze Item gegen die 400-KB-Linie. Die AWS Service Quotas schreiben die genaue Byte-Abrechnung aus.
Warum das Limit existiert
Große Items sind teuer zu bewegen. DynamoDB-Reads werden in 4-KB-Einheiten gemessen, ein 400-KB-Item kostet also 100 RCU, um es strong zu lesen — und Reads, Writes und Replikation werden alle langsamer und teurer, je größer Items werden. Das Limit drängt dich zu kleinen, gezielten Items und weg vom "einen riesigen Blob holen"-Anti-Pattern, zu dem NoSQL-Anfänger aus relationaler Gewohnheit greifen.
Darum herum modellieren
Für das Flotten-Beispiel: hör auf einzubetten. Gib jedem Messwert sein eigenes Item in derselben Partition wie das Fahrzeug, geordnet nach Timestamp auf dem Sort Key:
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:05Z lat, lng, fuel
PK: VEHICLE#A1 SK: READING#2026-06-27T10:00:10Z lat, lng, fuelJetzt wächst kein einzelnes Item, Writes wachsen nie über das Limit hinaus, und eine
einzige Query auf VEHICLE#A1 holt die Messwerte eines Fahrzeugs immer noch als eine
sortierte Item Collection zurück. Begrenzte
Sub-Listen (eine Handvoll Tags, ein fester Config-Block) sind in Ordnung einzubetten;
unbegrenzte werden zu Items.
Item-Größe in DynoTable prüfen
Bevor du dich auf eine Form festlegst, wiege ein repräsentatives Item. Öffne in DynoTable ein Item in der Quick View, und es zeigt dir die Byte-Größe des Items zusammen mit seinen Attributen — so erkennst du beim Durchstöbern echter Daten ein zu schweres Item zur Designzeit statt beim gescheiterten Write.
Lieber im Browser bleiben? Der DynamoDB Item Size Calculator macht dasselbe aus einer eingefügten Probe und gibt die exakten KB sowie die RCU/WCU aus, die jeder Read und Write kostet.


Fallstricke und nächste Schritte
- Achte auf eingebettete Listen, die mit dem Traffic wachsen — sie sind die klassische 400-KB-Zeitbombe. Begrenze sie oder spalte sie aus.
- Kürze Attributnamen auf Items mit hoher Kardinalität — das gibt dir gratis Größe und Speicher zurück.
- Große Werte gehören in S3. Speichere große Blobs (Bilder, Dokumente) in S3 und halte nur den Key auf dem Item.
- Verwandt: Denormalisierung und Eins-zu-viele-Beziehungen behandeln, wann eingebettet vs. aufgespalten wird.
Willst du auf einen Blick echte Item-Größen über eine Tabelle hinweg sehen? DynoTable herunterladen und deine Daten direkt inspizieren.