Sparse Indexes in DynamoDB
Ein Sparse Index ist ein Secondary Index, der nur die Items hält, die sein Key-Attribut tragen — sodass eine kleine, heiße Teilmenge einer riesigen Tabelle zu ihrer eigenen vorgefilterten, abfragefertigen Collection wird.
Du hast Millionen Zeilen, aber die Query, die du den ganzen Tag ausführst, berührt eine winzige Scheibe: die offenen Support-Tickets, die unbezahlten Rechnungen, die zur Prüfung markierten Konten.
Diese Scheibe zu filtern scannt trotzdem die ganze Tabelle und rechnet dir jeden Read ab. Ein Sparse Index macht stattdessen den Index selbst klein.
Was ist ein Sparse Index in DynamoDB?
Ein Sparse Index ist ein Secondary Index, der nur die Items hält, die sein Key-Attribut tragen. Da DynamoDB jedes Item überspringt, dem dieser Key fehlt, erfindest du einen Key, den nur die gewünschten Items schreiben — offene Tickets, unbezahlte Rechnungen — und der Index wird genau diese Teilmenge. Queries lesen dann nur ihn, kein Filter, keine verschwendete Read Capacity.
- Ein Secondary Index indiziert nur Items, die seinen Key haben. Lass den Key auf einem Item weg, und es betritt den Index nie — kein Platzhalter, keine Null-Zeile.
- Also erfindest du einen Key, den nur die gewünschten Items tragen. Schreib ihn auf die Items, die du abfragst, entferne ihn auf dem Rest. Der Index wird genau diese Teilmenge.
- Die Query liest nur die Teilmenge, kein Filter. Ihre Größe folgt der kleinen heißen Menge, nicht der Tabellensumme.
REMOVEist der Hebel, nicht das Leeren. Ein leerer String ist immer noch ein Wert und wird immer noch indiziert — du musst das Attribut löschen.
Das Problem: Filtern spart keine Reads
Aus SQL kommend gehst du davon aus, dass eine WHERE-Klausel die Arbeit
verkleinert. DynamoDBs FilterExpression tut das nicht. Sie läuft nachdem
Items gelesen wurden, nicht davor.
Laut dem AWS Developer Guide reduziert Filtern "nicht die Menge der verbrauchten Read Capacity" — du zahlst für jedes untersuchte Item und wirfst dann die Nicht-Treffer weg.
Wenn also 50 deiner 5 Millionen Tickets offen sind, liest eine gefilterte
Query/Scan durch Millionen, um dir diese 50 zu geben.
Das ist die Falle hinter jedem "warum ist mein Scan so teuer"-Thread; Query vs. Scan hat das vollständige Kostenbild.
Ein Sparse Index umgeht sie, indem er den Index selbst klein macht.
Wie Sparseness funktioniert
Ein Secondary Index indiziert nur Items, die die Key-Attribute des Index tatsächlich haben.
Die AWS-Docs zu Global Secondary Indexes sagen es klar: "ein Global Secondary Index enthält nur Items, die die für diesen Index definierten Key-Attribute haben."
Verpass den Partition Key (oder Sort Key) des GSI auf einem Item, und DynamoDB schreibt es einfach nicht in den Index. Kein Platzhalter, keine Null-Zeile — das Item fehlt.
Diese "Abwesenheit by default" ist der ganze Trick. Indiziere kein
status-Attribut, das jedes Item trägt. Erfinde ein Attribut, das nur die
Items überhaupt tragen, die du abfragen willst.
Der Index wird dann zu einer sauberen Liste genau dieser Items, und eine Query
dagegen liest nur sie — kein Filter, keine verschwendete Kapazität.
Stell dir die Basistabelle vor, die den Index speist, wo nur Items mit dem Key hinüberwandern:
Nur die gekeyten (offenen) Items replizieren in den Index; geschlossene Items betreten ihn nie.
Das ist dieselbe Key-Form-Denkweise wie Single-Table Design: Keys sind Werkzeuge, die du für ein bestimmtes Zugriffsmuster baust, keine treuen Spiegel deiner Daten.
Ein durchgespieltes Beispiel: "nur offene Tickets"
Nimm eine Support-Ticket-Tabelle. Die Basistabelle ist dafür gekeyt, ein Ticket per id zu holen und die Tickets eines Kunden aufzulisten:
| PK | SK | attributes |
|---|---|---|
| TICKET#a91f | DETAIL | subject, body, priority, openState |
| CUSTOMER#88 | TICKET#a91f | subject, priority, openState |
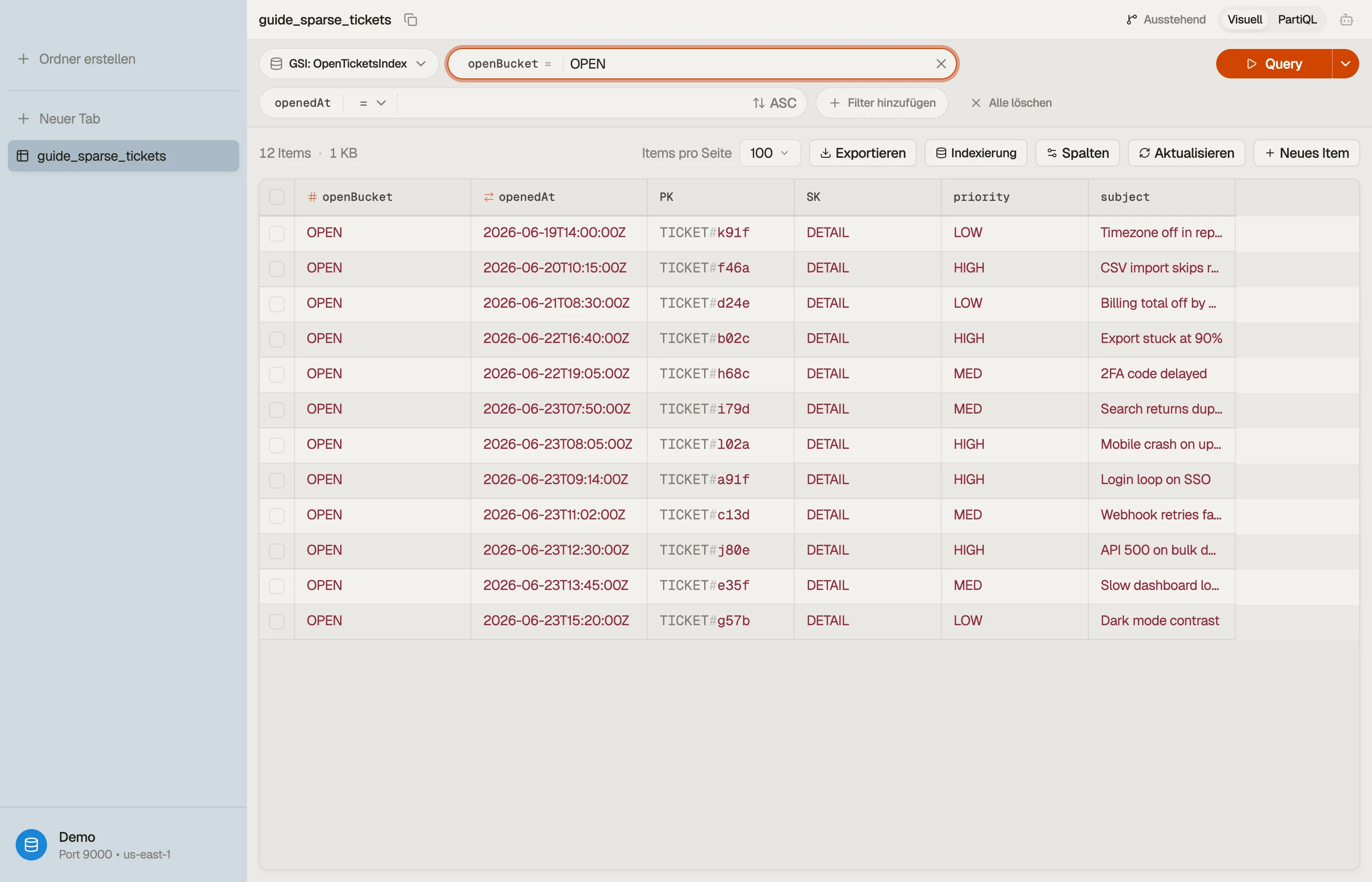
Über die Lebenszeit der Tabelle landen die meisten Tickets schließlich geschlossen. Aber die Dashboard-Query, die deine Agents den ganzen Tag treffen, ist "zeig mir jedes offene Ticket, ältestes zuerst" — ein paar hundert Zeilen, versteckt in Millionen.
Der Sparse-Index-Zug: definiere einen GSI mit Partition Key openBucket und Sort
Key openedAt, und schreibe openBucket nur auf offene Tickets. Setze es,
wenn das Ticket erstellt wird; REMOVE es, wenn das Ticket gelöst wird.
| PK | SK | openBucket | openedAt | |
|---|---|---|---|---|
| TICKET#a91f | DETAIL | OPEN | 2026-06-23T09:14:00Z | ← offen: im Index |
| TICKET#b02c | DETAIL | OPEN | 2026-06-22T16:40:00Z | ← offen: im Index |
| TICKET#77de | DETAIL | (fehlt) | 2026-05-30T11:02:00Z | ← geschlossen: NICHT im Index |
Tickets a91f und b02c tragen openBucket, also leben sie im GSI. Ticket
77de wurde gelöst und hatte openBucket entfernt, also fiel es still heraus.
Das Dashboard ist jetzt eine billige Query:
Query IndexName = "open-tickets-index"
KeyConditionExpression: openBucket = "OPEN"
ScanIndexForward: true # oldest firstDas liest nur offene Tickets. Wenn Tickets schließen, schrumpft der Index von allein — seine Größe folgt der offenen Population, nie der Gesamtzahl.
Ein statischer Partitionswert ("OPEN") ist hier genau deshalb in Ordnung, weil
die Menge klein bleibt. Eine riesige offene Menge bräuchte einen geshardeten
Partition Key, aber der Index "kleine Teilmenge" ist genau dort, wo ein Wert die
richtige Wahl ist.
Der Übergang, der es funktionieren lässt, ist eine einzige Update-Expression — das Entfernen des Attributs, wenn das Ticket gelöst wird.
Prototype diese REMOVE-Klausel und die getypte Key-Condition für die Leseseite
im DynamoDB Expression Builder, statt
ExpressionAttributeNames und :val-Platzhalter selbst von Hand
zusammenzubauen.
Mach es in DynoTable
Der schwere Teil eines Sparse Index ist nicht der Read — es ist das Sehen, welche Items es in den Index geschafft haben und welche still herausfielen.
DynoTable lässt dich eine Tabellenansicht auf einen Secondary Index umschalten und
genau die befüllte Teilmenge sehen. So kannst du bestätigen, dass ein gelöstes
Ticket open-tickets-index wirklich verlassen hat, statt mit einem veralteten Key
zu verweilen.


Fallstricke und nächste Schritte
Ein paar Dinge, auf die du achten solltest:
- Entferne den Key, leere ihn nicht. Ein leerer String ist immer noch ein
Wert, und DynamoDB indiziert ein Item, dessen
openBucket""ist. Um ein Item aus dem Index zu droppen, musst du das AttributREMOVEn — es auf einen falsy Wert zu setzen hält es drin. - Der Index ist letztendlich konsistent. GSIs aktualisieren asynchron, also kann ein gerade gelöstes Ticket kurz noch erscheinen — GSI-Reads unterstützen nur letztendliche Konsistenz. Vertrau ihm nicht für "ist dieses Ticket genau jetzt offen".
- Bedenke projizierte Attribute. Eine
Queryauf dem Index gibt nur die in ihn projizierten Attribute zurück. Wenn das Dashboard Betreff und Priorität braucht, projiziere sie — oder zahle ein zusätzlichesGetItemfür das volle Basis-Item. - Das ist eine GSI-Stärke, keine LSI-Stärke. Local Secondary Indexes teilen sich den Partition Key der Basistabelle und können Items so nicht selektiv droppen. GSI vs. LSI schlüsselt den Trade-off auf.
Sparse Indexes sind eine der ältesten Ideen im Modell. Das ursprüngliche Amazon-Dynamo-Paper von 2007 baute den Store darum herum, bekannte, hochvolumige Zugriffsmuster billig zu bedienen.
Ein Sparse Index ist genau das: forme die Keys so, dass die häufige Query nichts liest, was sie nicht braucht.
Um einen für echt zu bauen und zu inspizieren, lade DynoTable herunter, richte es auf deine Tabelle und schalte die Datenansicht auf deinen Sparse GSI — sieh zu, wie die Teilmenge sich aktualisiert, während Items den Index-Key gewinnen und verlieren.