DynamoDB Item Collections
Eine Item Collection ist die Menge aller Items in einer Tabelle (oder einem Index), die sich denselben Partition-Key-Wert teilen. Sie ist kein Feature, das du einschaltest — sie ist eine emergente Eigenschaft deines Key-Schemas.
In dem Moment, in dem zwei Items denselben Partition Key tragen, bilden sie eine
Collection, und diese Collection wird zur Einheit, die DynamoDB dich in einer
einzigen Query zusammen lesen lässt.
Mach das richtig, und deine Reads kommen in einem Round Trip zurück. Mach es
falsch, und du steckst mit einem Scan fest.
Was ist eine DynamoDB Item Collection?
Eine DynamoDB Item Collection ist die Menge aller Items, die sich denselben Partition-Key-Wert teilen, zusammen gespeichert und nach Sort Key sortiert. Sie ist kein Feature, das du einschaltest — sie ist eine emergente Eigenschaft deines Key-Schemas. Die Collection ist die Einheit, die eine einzige Query effizient liest, während ein Scan jede Partition abläuft.
- Eine Collection ist einfach "derselbe Partition Key". Zwei oder mehr Items mit demselben Partition-Key-Wert werden zusammen gespeichert, sortiert nach Sort Key.
- Sie ist die Einheit einer effizienten
Query.Queryliest eine Collection;Scanläuft jede Partition ab. Das ist die ganze Performance-Geschichte. - Kein Sort Key, keine Collection. Eine Tabelle nur mit Partition Key hält ein Item pro Key — nichts zum Sammeln.
- Zwei Limits beißen: die 10-GB-Grenze pro Collection, wenn ein LSI existiert, und Hot Partitions durch Keys mit niedriger Kardinalität.
Das Problem: verwandte Items zusammen lesen
Angenommen, du betreibst eine Fahrzeugflotte, die jeweils alle paar Sekunden
Telemetrie streamt — Geschwindigkeit, Kühlmitteltemperatur, Tankstand. Der
dominierende Read ist "gib mir die jüngsten Messwerte für Fahrzeug V-7741".
Aus SQL kommend würdest du eine vehicle_id-Spalte indizieren und den Planner die
Arbeit machen lassen. Ein einfacher Key-Value-Store hat diesen Luxus nicht.
Er behandelt jeden Messwert als isolierten Datensatz, also bedeutet diese Frage, die ganze Tabelle zu scannen und zu filtern. Langsam, teuer und mit wachsender Flotte schlimmer.
DynamoDBs Antwort ist, "alle Messwerte für ein Fahrzeug" zu einem physisch gruppierten, direkt adressierbaren Ding zu machen. Diese Gruppierung ist die Item Collection.
Was eine Collection tatsächlich ist
DynamoDB speichert Items in Partitionen und leitet jedes Item zu einer Partition, indem es seinen Partition Key hasht. Jedes Item mit demselben Partition-Key-Wert landet daher in derselben Partition, sortiert nach Sort Key.
Der AWS Developer Guide benennt das genau so: Items, die sich einen Partition-Key-Wert teilen, sind eine Item Collection, zusammen gespeichert und nach Sort Key geordnet.
Das ist dieselbe Idee, die das Amazon-Dynamo-Paper von 2007 einführte — Consistent Hashing, um Keys Nodes zuzuweisen — erweitert um eine Sortier-Dimension, sodass verwandte Items auf der Platte benachbart liegen.
Weil sie benachbart und geordnet sind, gibt DynamoDB einen zusammenhängenden Lauf
von ihnen mit einem Seek zurück. Darum ist Query billig und Scan nicht:
Query liest eine einzelne Collection; Scan läuft jede Partition ab.
Um eine Collection zu bilden, brauchst du einen zusammengesetzten Primary Key — einen Partition Key und einen Sort Key. Eine Tabelle, die nur auf dem Partition Key gekeyt ist, hat genau ein Item pro Key-Wert, also gibt es nichts zum Sammeln.
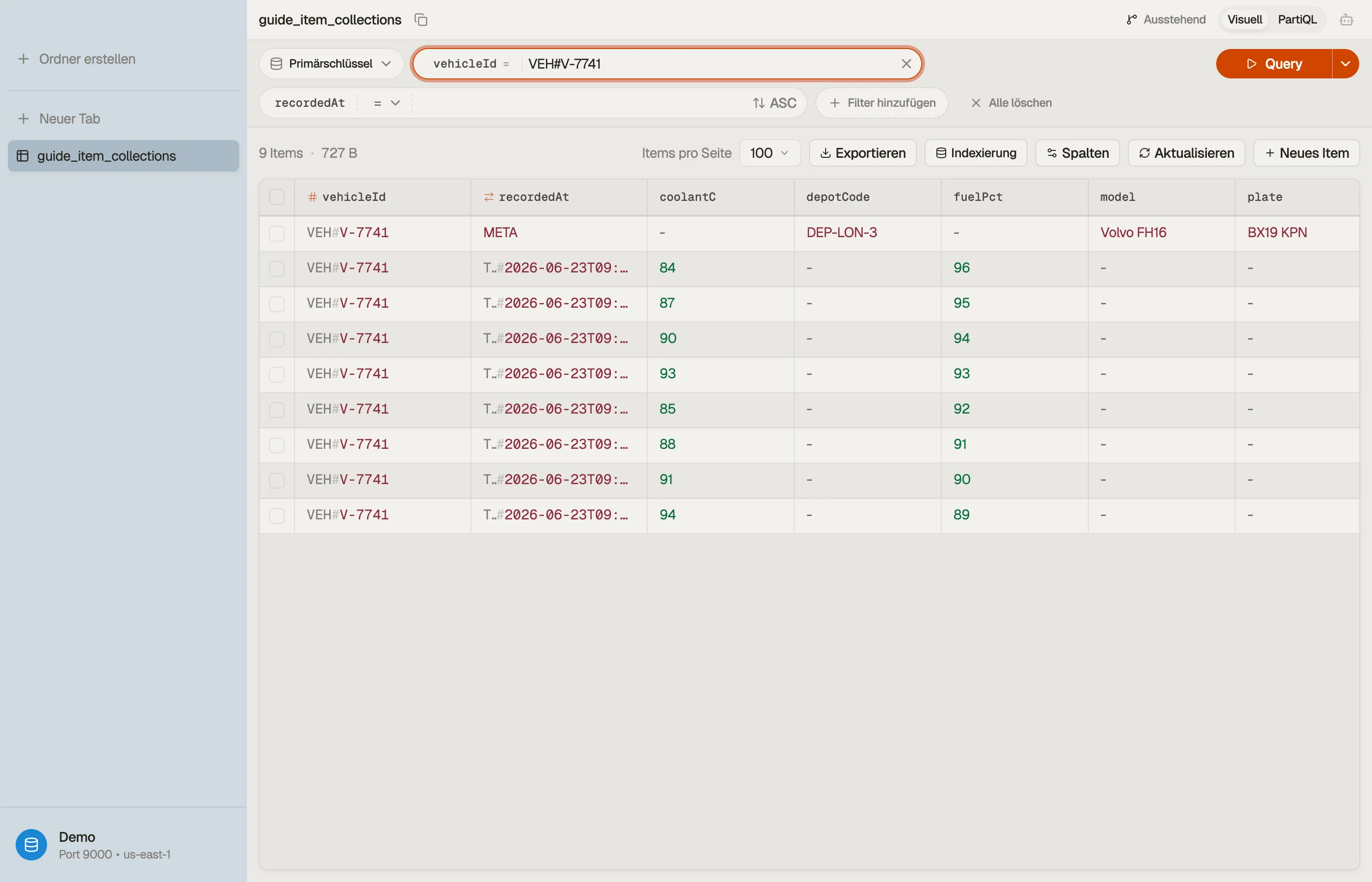
Unser durchgespieltes Beispiel: Fahrzeug → Telemetrie-Messwerte
Modelliere den Telemetrie-Stream mit einem zusammengesetzten Key. Der Partition Key identifiziert das Fahrzeug; der Sort Key ist der Zeitstempel des Messwerts, der die Messwerte innerhalb der Collection neueste-zu-älteste ordnet.
PK (vehicleId) SK (recordedAt) attributes
VEH#V-7741 META plate, model, depotCode
VEH#V-7741 TS#2026-06-23T09:00:01Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:06Z speedKph, coolantC, fuelPct
VEH#V-7741 TS#2026-06-23T09:00:11Z speedKph, coolantC, fuelPct
VEH#V-7742 META plate, model, depotCode
VEH#V-7742 TS#2026-06-23T09:00:02Z speedKph, coolantC, fuelPctHier leben zwei Collections — eine pro Fahrzeug. Das META-Item
(Fahrzeug-Metadaten) und alle Messwerte von V-7741 bilden eine Collection; die
Items von V-7742 bilden eine andere.
Beachte den Trick: gib den Metadaten einen Sort Key (META), der vor jedem
TS#...-Wert sortiert, und eine einzige Query auf PK = "VEH#V-7741" gibt das
Profil des Fahrzeugs und seine Messwerte zusammen zurück.
Das ist das Eltern-und-Kinder-Muster im Herzen von Single-Table Design.
Jeder gestrichelte Kasten ist eine Item Collection: derselbe Partition Key, Items
nach Sort Key sortiert. Eine Query liest genau einen Kasten.
Eine Collection abfragen
Weil die Collection nach Sort Key sortiert ist, bekommst du Range-Reads gratis. Um die Messwerte zu ziehen, die in einem Zehn-Minuten-Fenster für ein Fahrzeug aufgezeichnet wurden, begrenzt du den Sort Key:
Query
KeyConditionExpression: vehicleId = :v AND recordedAt BETWEEN :from AND :to
ScanIndexForward: false # newest firstDie Key-Condition beschränkt dich auf eine Collection (vehicleId = :v) und dann
auf eine zusammenhängende Scheibe davon (recordedAt BETWEEN ...). DynamoDB liest
nur diese Items und rechnet dir nur sie ab. Nur die Metadaten?
recordedAt = "META" holt das einzelne META-Item.
Diese Key-Conditions und Projection-Expressions von Hand zu bauen ist fummelig.
Der DynamoDB Expression Builder generiert die
KeyConditionExpression, die ExpressionAttributeNames und die
ExpressionAttributeValues für dich, sodass die Details rund um reservierte
Wörter und Platzhalter nicht beißen.
Collections auf Indexen
Ein Secondary Index hat sein eigenes Key-Schema, also bildet er seine eigenen Item Collections.
Füge einen Global Secondary Index hinzu, gekeyt auf depotCode (Partition) und
recordedAt (Sort), und "alle Messwerte aus Depot DEP-LON-3, neueste zuerst"
wird zu einer einzigen Query gegen die Collection dieses Index — ein Read, den
die Basistabelle nicht bedienen kann.
Darum zählt der Indextyp: er bestimmt, welche Collections du bilden kannst und wie sie sich verhalten. Siehe GSI vs. LSI für den Trade-off.
Eine scharfe Unterscheidung: ein Local Secondary Index (LSI) teilt sich den Partition Key der Basistabelle, also ist seine Collection physisch gebunden an die Basis-Item-Collection — und diese Bindung erzeugt ein hartes Limit, weiter unten.
Die Limits, die beißen
Item Collections sind mächtig, aber zwei Einschränkungen entscheiden, wie du Keys formst:
- Das 10-GB-LSI-Limit. Wenn eine Tabelle einen oder mehrere Local Secondary
Indexes hat, kann eine einzelne Item Collection — die Basis-Items plus ihre
LSI-Projektionen für einen Partition Key — 10 GB nicht überschreiten.
Überschreite es, und Writes, die die Collection wachsen lassen, beginnen mit
ItemCollectionSizeLimitExceededzu scheitern. Eine Tabelle ohne LSI hat keine solche Grenze pro Collection. Genau darum ist ein unbegrenzter, ewig wachsender Stream (Telemetrie, die nie aufhört) ein schlechter Fit für einen LSI: die Collection wächst nur. Ein GSI bekommt eigene Partitionen, also umgeht er das Limit. - Hot Partitions. Eine Collection lebt in einer Partition, und eine einzelne
Partition hat endlichen Durchsatz. Wenn ein Fahrzeug (oder ein
depotCode) einen wild überproportionalen Anteil des Traffics anzieht, kannst du diese Partition überhitzen, selbst während die Tabelle als Ganzes unterprovisioniert ist. Adaptive Capacity — behandelt in AWS' re:Invent-Deep-Dives "Advanced Design Patterns for DynamoDB" — isoliert und boostet Hot Keys automatisch, aber sie kann einen Key ohne jede Streuung nicht retten. Wähle Partition Keys mit hoher Kardinalität, damit der Traffic über viele Collections ausfächert.
Sieh es in DynoTable
Der schnellste Weg, Intuition für Collections aufzubauen, ist, sich eine
anzusehen. In DynoTable rendert das Abfragen eines Partition Key die ganze
Collection als zusammenhängende, nach Sort Key geordnete Liste — das META-Item
sitzt direkt vor seinen zeitgestempelten Messwerten, auf dem Bildschirm, ohne
mentale Rekonstruktion.


Fallstricke und nächste Schritte
- Kein Sort Key, keine Collection. Eine Tabelle nur mit Partition Key kann verwandte Items nicht gruppieren. Wenn du Items zusammen lesen musst, brauchst du einen zusammengesetzten Key.
- Lass eine LSI-Collection nicht unbegrenzt wachsen. Append-only-Streams gehören wegen der 10-GB-Grenze auf einen GSI (oder einen zeit-gebucketeten Partition Key), nicht auf einen LSI.
- Streue deine Partition Keys. Eine Collection ist nur so skalierbar wie die Partition, in der sie lebt. Partition Keys mit niedriger Kardinalität erzeugen Hot Spots.
- Greif zu
Query, nicht zuScan. Collections existieren, damit du verwandte Items mit einer gezieltenQuerylesen kannst; auf einenScanzurückzufallen wirft diesen Vorteil weg — siehe Query vs. Scan.
Skizziere dein eigenes Key-Schema, setz eine Query gegen einen echten Partition
Key ab und sieh zu, wie die Collection geordnet zurückkommt. Lade DynoTable
herunter und erkunde die Collections deiner Tabellen direkt.