Wie du Daten in DynamoDB modellierst
In SQL modellierst du zuerst Entitäten und Beziehungen und vertraust dann darauf, dass der Query-Planner später zusammensetzt, was immer du verlangst. DynamoDB dreht das um. Du modellierst die Reads, von denen du schon weißt, dass du sie machen wirst, und die Keys existieren, um sie zu bedienen.
Es gibt keine Join-Engine und keinen Planner, der zur Laufzeit eine Strategie wählt. Eine Query liest eine Partition entlang eines Keys, und das ist der gesamte Performance-Vertrag. Also entwirfst du Keys für bekannte Zugriffsmuster, nicht für ein ordentliches Schema.
AWS sagt es klar in seinem Best-Practices-Guide: "du solltest dein Schema nicht zu entwerfen beginnen, bevor du die Fragen kennst, die es beantworten muss."
Dieser Guide spielt den ganzen Prozess an einer Domäne durch: einem Multiplayer-Game-Leaderboard, das Spieler verfolgt, die Matches, die sie spielen, und ihr Ranking pro Saison. Wir gehen von einer Liste von Fragen zu einem funktionierenden Key-Schema.
Wie modellierst du Daten in DynamoDB?
Modelliere zuerst die Reads, nicht die Tabellen. Liste alle Queries auf, die die App stellt, und entwirf dann einen und , sodass jede Frage zu einer einzigen Query oder einem GetItem führt. Ko-lokalisiere Items, die zusammen gelesen werden, lege Werte, über die du rangierst, in den Sort Key, und füge einen GSI für jedes Zugriffsmuster hinzu, das die Basistabelle nicht bedienen kann.
- Liste zuerst die Reads, nicht die Tabellen. Die Fragen sind die Spec; die Substantive sind Ablenkung.
- Jede Frage muss eine
Queryoder einGetItemsein. Wenn eine Frage einenScanbraucht, ist das Modell falsch. - Ko-lokalisierte Items teilen sich einen Partition Key; alles, worüber du rangest, kommt in den Sort Key.
- Eine Frage, die die Basistabelle nicht beantworten kann, bekommt einen GSI — nie einen
Scanmit Filter.
Schritt 1 — Rahme das Problem als Fragen, nicht als Tabellen
Widersteh dem Drang, players-, matches- und scores-Tabellen zu zeichnen. Dieser Instinkt ist die SQL-Gewohnheit, und hier ist er falsch. Schreib stattdessen jeden Read auf, den die App tatsächlich durchführt. Für unser Leaderboard:
- Hol das Profil eines Spielers per id.
- Liste die jüngsten Matches eines Spielers, neueste zuerst.
- Zeig die Top-N-Spieler für eine bestimmte Saison, nach Rating gerankt.
- Schlag einen Spieler über sein öffentliches Handle nach (z. B. für eine Profil-URL).
Diese vier Fragen — nicht die Substantive — sind die Spec. Jede muss sich zu einer einzigen Query (oder einem GetItem) auflösen, weil das die einzige Zugriffsform ist, die DynamoDB im großen Maßstab billig bedient.
Wenn eine Frage nur durch Scannen der Tabelle beantwortet werden kann, ist das Modell falsch, und du wirst es in Latenz und Kosten spüren — siehe Query vs. Scan dafür, warum ein Scan die zu vermeidende Falle ist.
Die ganze Methode ist eine kurze, geordnete Pipeline, die du einmal pro Domäne durchläufst:
Jeder Schritt unten bildet einen Kasten ab: auflisten, aufzählen, Keys entwerfen, Indexe für den Rest hinzufügen, dann validieren.
Schritt 2 — Verstehe die Primitive, mit denen du modellierst
Eine Tabelle hat einen Partition Key (PK), der bestimmt, auf welcher physischen Partition ein Item lebt, und einen optionalen Sort Key (SK), der Items innerhalb dieser Partition ordnet.
Die AWS-Core-Components-Docs nennen das Paar den Primary Key des Items. Eine Query zielt immer auf genau einen PK-Wert und kann den SK range-scannen oder filtern — das ist das ganze Toolkit.
Dieses Single-Partition-Design ist es, was DynamoDB die vorhersehbaren, latenzarmen, horizontal partitionierten Reads liefern lässt, die zuerst im Amazon-Dynamo-Paper von 2007 beschrieben wurden.
Zwei Konsequenzen treiben jede Entscheidung unten:
- Items, die zusammen gelesen werden, sollten sich einen Partition Key teilen, sodass eine
Querysie in einer einzigen abgerechneten Anfrage zurückgibt. - Alles, worüber du rangen willst (jüngste Matches, Top-Ratings), muss im Sort Key leben, weil das das einzige Attribut ist, das
Queryordnen und begrenzen kann.
Wenn eine Frage eine andere Zugriffsform braucht, als die Basistabelle bietet, fügst du einen Global Secondary Index hinzu — eine Neu-Projektion der Tabelle unter einem anderen PK/SK.
(Für GSI versus Local Secondary Index siehe GSI vs. LSI.)
Schritt 3 — Entwirf die Keys, eine Frage nach der anderen
Wir verwenden eine einzelne Tabelle mit generischen, überladenen Key-Attributen — den Single-Table-Ansatz — weil ein Spieler und seine Matches zusammen gelesen werden.
Erfinde deine eigenen Präfixe; hier taggen PLAYER#, MATCH# und SEASON# den Entitätstyp innerhalb ansonsten generischer Keys.
Fragen 1 und 2 (Profil + jüngste Matches) teilen sich eine Partition, also hängen beide am selben PK:
| partitionId | rangeId | attributes |
|---|---|---|
| PLAYER#u8231 | PROFILE | handle, region, createdAt |
| PLAYER#u8231 | MATCH#2026-06-23T14 | result=win, ratingDelta=+18, mapId |
| PLAYER#u8231 | MATCH#2026-06-23T11 | result=loss, ratingDelta=-15, mapId |
Query partitionId = "PLAYER#u8231" gibt das Profil und jedes Match in einem Read zurück. Für das Profil allein GetItem.
Für jüngste Matches läuft rangeId begins_with "MATCH#" mit ScanIndexForward = false sie neueste-zuerst ab — der Zeitstempel im Sort Key übernimmt die Ordnung gratis.
Fragen 3 und 4 können aus dieser Partition nicht beantwortet werden — sie drehen sich um Saison-Rang und um Handle, von denen keines der Basis-PK ist. Jede bekommt einen GSI.
Wir fügen zwei generische Index-Attribute hinzu, gsiPartition / gsiSort, und lassen jedes Item sie mit dem befüllen, was dieser Index braucht:
| partitionId | rangeId | gsiPartition | gsiSort |
|---|---|---|---|
| PLAYER#u8231 | PROFILE | SEASON#2026-Q2 | RATING#1842 |
| PLAYER#u8231 | PROFILE | HANDLE#nighthawk | PLAYER#u8231 |
Jetzt gibt Query auf den Saison-Index WHERE gsiPartition = "SEASON#2026-Q2" mit ScanIndexForward = false die Spieler nach Rating gerankt zurück — das ist das Leaderboard.
Ein zweiter Index, gekeyt auf HANDLE#…, löst ein öffentliches Handle in einem Read zu einer Spieler-id auf. Eine physische Tabelle, vier Single-Query-Zugriffsmuster.
Eine Null-Padding-Anmerkung zu
RATING#1842: DynamoDB sortiert Sort Keys lexikografisch, nicht numerisch, also muss ein Rating auf eine feste Breite nullgepaddet werden (RATING#01842), sonst würde9nach1000sortieren. Das ist ein klassischer Modellierungsfallstrick, den es sich lohnt, von vornherein richtig zu machen.
Schritt 4 — Validiere das Modell in DynoTable
Ein Key-Schema verdient erst Vertrauen, wenn du zusiehst, wie eine echte Query genau die Items zurückgibt, die du erwartet hast, und nichts mehr.
Öffne die Tabelle in DynoTable, führe die Leaderboard-Query gegen den Saison-Index aus und bestätige, dass die Partition gerankt und begrenzt zurückkommt — kein Scan, keine clientseitige Sortierung.

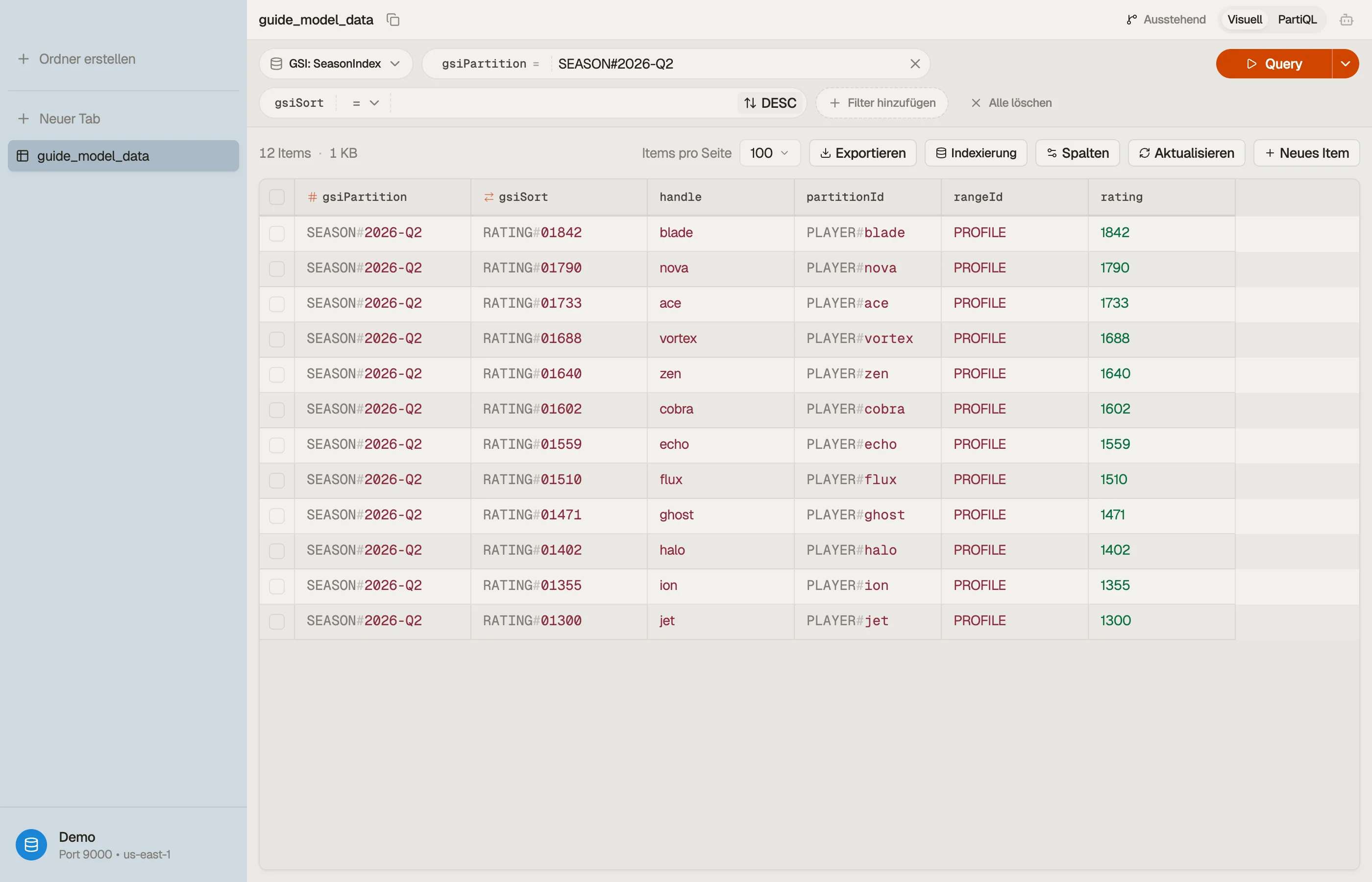

Wenn du die Condition-Expressions für diese Queries baust — das begins_with, das gsiPartition = :p, die Platzhalter-:p-Bindung — lass den DynamoDB Expression Builder es machen.
Er generiert die KeyConditionExpression, die ExpressionAttributeNames und die ExpressionAttributeValues, sodass ein reserviertes Wort wie result oder ein vertippter Platzhalter nie still einen Read kaputtmacht.
Schritt 5 — Fallstricke und nächste Schritte
Ein paar Fallen zum Prüfen, bevor du das Modell ausschiffst:
- Modelliere keine Beziehungen, die du nie zusammen liest. Ein GSI pro Frage ist billig; ein verschwendeter GSI ist wiederkehrende Kosten. Füge Indexe aus der Fragenliste hinzu, nicht spekulativ.
- Achte auf Partitionshitze. Wenn ein PK (ein Promi-Spieler, eine einzelne heiße Saison) den meisten Traffic absorbiert, kann diese Partition drosseln. Streue Writes mit einem Suffix-Shard, wenn ein Key nachweislich heiß ist — AWS behandelt das unter Partition-Key-Design.
- Null-padde und ISO-8601-iere alles Numerische oder Zeitliche in einem Sort Key, damit lexikografische Ordnung der Reihenfolge entspricht, die du meinst.
- Eine neue Frage = ein neuer Key oder Index, nie ein
Scan. Wenn später ein wirklich neues Zugriffsmuster auftaucht, erweitere die Keys; tünche es nicht mit einem Filter über.
Modelliere zuerst die Fragen, entwirf Keys, sodass jede eine Query ist, dann beweise es.
Probier DynoTable, um deine Tabelle zu durchstöbern, diese Queries gegen die Basistabelle und die GSIs nebeneinander auszuführen und zuzusehen, wie die Zugriffsmuster, die du entworfen hast, genau das zurückgeben, was du geplant hast.