n:m-Beziehungen in DynamoDB
Eine Studentin schreibt sich in viele Kurse ein; ein Kurs hält viele Studierende.
In SQL greifst du zur Join-Tabelle und einem vierfachen JOIN.
DynamoDB hat keine Joins, also muss die Beziehung in den Keys leben — und der
Trick ist, jede Einschreibungs-Edge in einer Form zu speichern, die beide Seiten
direkt Queryen können.
Dieser Guide spielt das Problem Studierende ↔ Kurse von Anfang bis Ende durch: die Zugriffsmuster, das Adjazenzlisten-Muster, das sie löst, ein eigenes Key-Schema zum Kopieren und wie du beide Richtungen zurückliest, ohne je die Tabelle zu scannen.
Wie modellierst du eine n:m-Beziehung in DynamoDB?
DynamoDB hat keine Joins, also modellierst du eine n:m-Beziehung mit dem Adjazenzlisten-Muster: Speichere jeden Link als eigenes Edge-Item, das nach einer Seite gekeyt ist, und füge dann einen invertierten GSI hinzu, der die Keys tauscht. Eine einzige Edge, einmal geschrieben, beantwortet dann Queries aus beiden Richtungen günstig.
- Speichere jede Einschreibung als eigenes Edge-Item, nicht als Listenattribut auf einer der Seiten.
- Keye die Edge nach der Studentin (
PK = STU#…,SK = ENROLL#CRS#…), sodass eineQuerydie gesamte Kursliste einer Studentin zurückgibt. - Füge einen invertierten GSI hinzu, der die Rollen tauscht (
GSI1PK = CRS#…), sodass dieselbe Edge auch "wer ist in diesem Kurs?" beantwortet. - Eine Edge, einmal geschrieben, billig in beide Richtungen gelesen — das ist das ganze Spiel.
Rahme zuerst die Zugriffsmuster
Modellierung in DynamoDB ist zugriffsmuster-first: du legst die Reads fest, bevor du auch nur einen Attributnamen wählst. Eine n:m-Beziehung hat fast immer zwei symmetrische Reads plus die Entitäts-Lookups:
- Hol das Profil einer Studentin und liste jeden Kurs, in den sie eingeschrieben ist.
- Hol die Metadaten eines Kurses und liste jeden in diesen Kurs eingeschriebenen Studierenden.
- Schlag eine einzelne Einschreibungs-Edge nach — um eine Note zu aktualisieren oder den Kurs abzulegen.
Der Schmerz: die beiden List-Reads zeigen in entgegengesetzte Richtungen über
dieselbe Menge an Edges. Ein naives Design bedient eine billig und erzwingt einen
Scan für die andere — genau die Falle, behandelt in
Query vs. Scan.
Die Aufgabe ist, beide Richtungen zu einer einzigen Query zu machen.
Verwende das Adjazenzlisten-Muster
Die eigene Empfehlung von DynamoDB für Beziehungen ist die Adjazenzliste: modelliere jede Beziehung als ein Item, dessen Partition Key der eine Endpunkt und dessen Sort Key der andere ist.
AWS dokumentiert das auf der Seite Best Practices for Managing Many-to-Many Relationships des DynamoDB Developer Guide.
Warum Keys und nicht eine zweite Tabelle? Weil das Primitive, das DynamoDB dir
gibt, eine Query gegen eine einzelne Partition ist.
Eine Query liest einen zusammenhängenden Bereich von Sort-Key-Werten unter einem
Partition Key in einer abgerechneten Operation — das ist der einzige "Join", den
die Engine anbietet.
Um eine Beziehung zu bekommen, die von beiden Seiten billig liest, duplizierst du die Edge: schreib sie einmal nach der Studentin gekeyt, dann nutze einen Secondary Index, um dieselbe Edge nach dem Kurs gekeyt zu projizieren.
Das ist das überladene-Keys-Denken aus Single-Table Design, angewandt auf eine Beziehung statt auf eine Eltern-Kind-Hierarchie.
Die Form sind zwei gestapelte Sichten derselben Edge — die Basistabelle nach Studentin gekeyt, der invertierte GSI nach Kurs:
Jede Edge wird einmal auf der Basistabelle geschrieben und mit getauschten Keys
in den GSI projiziert, sodass eine Query gegen beide Partitionen die Beziehung
billig liest.
Die Linie reicht zurück zum Amazon-Dynamo-Paper von 2007: der Partition Key ist die Verteilungseinheit, und Single-Key-Zugriff ist der schnelle Pfad.
Beziehungen in DynamoDB sind eine Übung darin, n:m-Reads in genau diesen schnellen Pfad zu biegen.
Spiel das Beispiel durch: Studierende ↔ Kurse
Verwende eine Tabelle mit generischen Keys, PK und SK, und kodiere den
Entitätstyp in den Wert. Die Einschreibungs-Edge ist das Herzstück:
| PK | SK | attributes |
|---|---|---|
| STU#a91 | PROFILE | name, year, major |
| STU#a91 | ENROLL#CRS#math204 enrolledOn, grade | |
| STU#a91 | ENROLL#CRS#cs101 | enrolledOn, grade |
| CRS#math204 | METADATA | title, credits, term |
| CRS#cs101 | METADATA | title, credits, term |
Eine einzige Query PK = "STU#a91" gibt das Profil der Studentin und jede
Einschreibung in einem Read zurück. Engt sie mit SK begins_with "ENROLL#" ein,
um nur die Kurs-Edges zu bekommen. Das löst "liste die Kurse einer Studentin".
Aber "liste die Studierenden eines Kurses" zeigt in die andere Richtung — und die Basistabelle kann es nicht beantworten, weil die Studierenden-id im Partition Key steckt, nicht im Sort Key.
Füge einen invertierten Global Secondary Index hinzu, der die Rollen tauscht.
Gib den Edge-Items ein generisches GSI1PK/GSI1SK-Paar, das den Kurs auf der
Partitionsseite und den Studierenden auf der Sortierseite hält:
| PK | SK | GSI1PK | GSI1SK |
|---|---|---|---|
| STU#a91 | ENROLL#CRS#math204 | CRS#math204 | STU#a91 |
| STU#b30 | ENROLL#CRS#math204 | CRS#math204 | STU#b30 |
| STU#a91 | ENROLL#CRS#cs101 | CRS#cs101 | STU#a91 |
Jetzt listet Query GSI1 WHERE GSI1PK = "CRS#math204" jeden Studierenden in
diesem Kurs auf — der Read, den die Basistabelle nicht bedienen konnte. Ein
Edge-Item, einmal geschrieben, beantwortet beide Richtungen.
Es muss ein GSI sein, kein LSI: die Kurs-Partition ist völlig verschieden von der Studierenden-Partition, und ein LSI teilt sich den Partition Key der Basistabelle.
Der Index spannt mehrere Partitionen, also muss er global sein — siehe GSI vs. LSI.
Ein Haken: GSIs in DynamoDB werden asynchron befüllt. Eine brandneue Einschreibung
kann einen Moment brauchen, bis sie in der CRS#…-Richtung erscheint.
Behandle den Kurs-Roster-Read als letztendlich konsistent — was der Developer Guide für Global Secondary Indexes ausdrücklich hervorhebt.
Schreib und lies es in DynoTable
Die Einschreibung zu schreiben heißt, vier Key-Attribute plus die eigenen Daten
der Edge zu setzen. Die Bedingung, die eine Studentin daran hindert, sich zweimal
in denselben Kurs einzuschreiben, ist ein attribute_not_exists(PK)-Guard auf dem
zusammengesetzten Key.
Das ist genau die Art Bedingung, die du visuell mit dem
DynamoDB Expression Builder zusammenbauen
kannst, statt die ExpressionAttributeNames und Platzhalterwerte von Hand zu
schreiben.
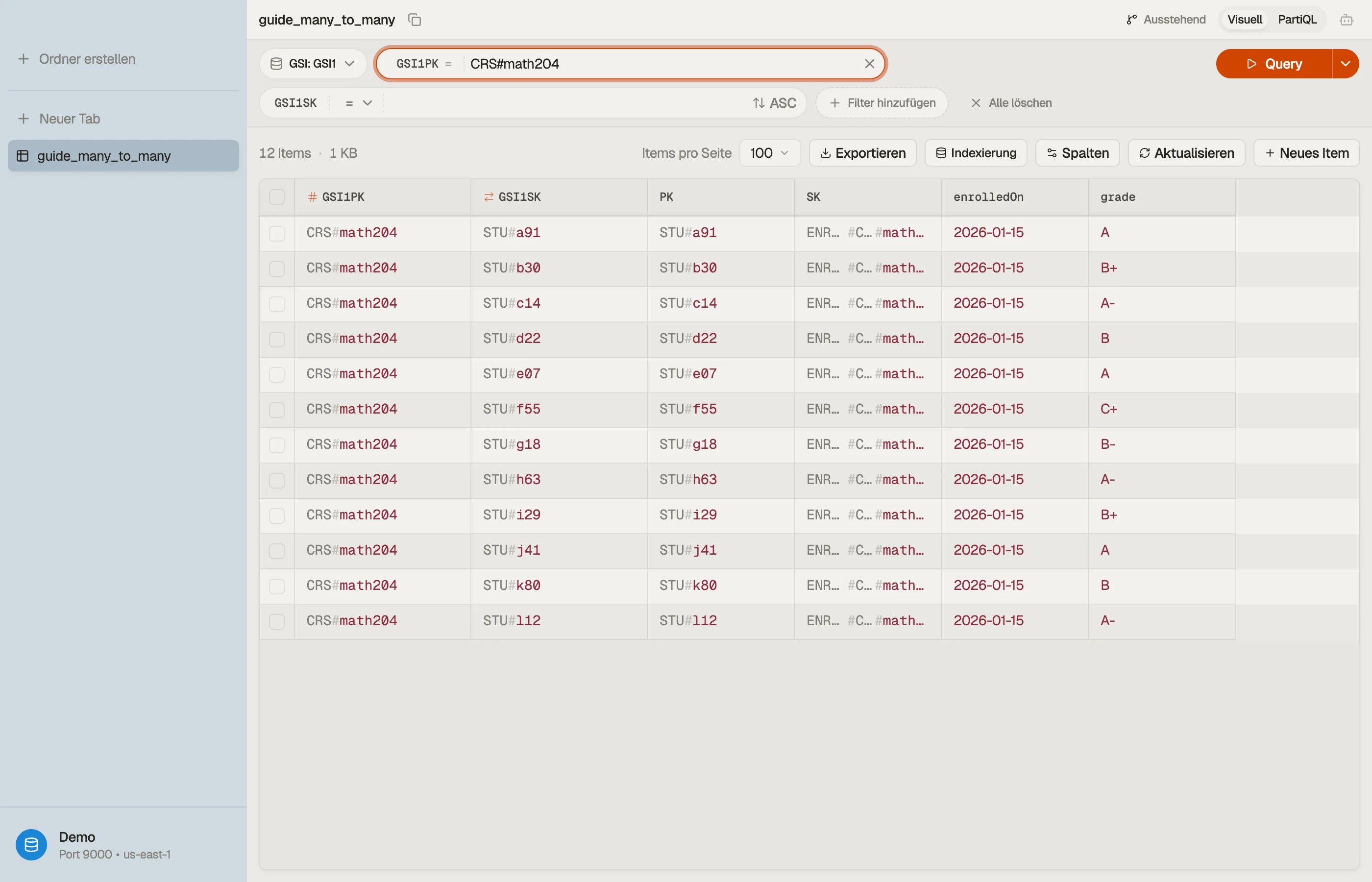
In DynoTable richtest du eine Query auf GSI1, setzt GSI1PK = "CRS#math204",
und der Roster kommt als Tabelle zurück, die du an Ort und Stelle lesen, sortieren
und bearbeiten kannst — beide Richtungen der Beziehung aus einem Schema
durchstöberbar.


Fallstricke und nächste Schritte
- Speichere eine Seite nicht als Listenattribut. Ein
courseIds-Array auf dem Studierenden-Item wirkt ordentlich, bis ein Kurs seinen Roster braucht, das Array die 400-KB-Item-Grenze erreicht oder zwei Einschreibungen kollidieren und sich gegenseitig überschreiben. Diskrete Edge-Items skalieren und aktualisieren unabhängig. - Halte Edge-Daten auf der Edge. Die
gradeundenrolledOnder Einschreibung gehören auf das Edge-Item, nicht dupliziert auf die Studentin oder den Kurs — es gibt genau eine Zeile pro Paar (Studentin, Kurs) zum Aktualisieren. - Bedenke die GSI-Propagierung. Die invertierte Indexrichtung ist letztendlich konsistent, also kann ein Read direkt nach einer Einschreibung um den Bruchteil einer Sekunde hinterherhinken.
- Projiziere nur, was der Roster braucht. Ein
KEYS_ONLYoder eine schmale Projektion hält den GSI klein, wenn die Roster-Sicht nur ids braucht.
Um tiefer in die umgebenden Muster einzusteigen, lies Single-Table Design für überladene Keys und GSI vs. LSI dafür, wann der invertierte Index global sein muss.
Dann lade DynoTable herunter, um das Schema Studierende ↔ Kurse wirklich zu modellieren — schreib die Edges, baue die Bedingung mit dem Expression Builder und frag beide Richtungen der Beziehung ohne einen einzigen Scan ab.