DynamoDB-Index-Projektionen: KEYS_ONLY, INCLUDE und ALL
Wenn du einen sekundären Index erstellst, kopiert DynamoDB nicht automatisch das ganze Item hinein. Du wählst, was kopiert wird — die Projektion des Index. Wähl zu wenig, und deine Abfragen zahlen einen zweiten Read, um den Rest zu holen; wähl alles, und du zahlst bei jedem Update zusätzliche Speicher- und Schreibkosten. Es ist ein Trade-off, den du einmal bei der Index-Erstellung festlegst und mit dem du dann lebst.
(Verwechsle das nicht mit einem Projektionsausdruck, der die Attribute kürzt, die ein einzelner Read zurückgibt. Auf dieser Seite geht es darum, was ein Index physisch speichert — siehe Projektionsausdrücke für den anderen.)
Was ist eine DynamoDB-Index-Projektion?
Eine Projektion ist die Menge an Attributen, die DynamoDB aus der Basistabelle in einen sekundären Index kopiert. Du wählst einen von drei Typen: KEYS_ONLY (nur die Keys), INCLUDE (Keys plus eine benannte Liste von Attributen) oder ALL (das gesamte Item). Mehr Projektion bedeutet weniger Basistabellen-Fetches, aber höhere Speicher- und Schreibkosten.
- Eine Projektion ist die Menge an Attributen, die in einen sekundären Index kopiert werden.
KEYS_ONLY— nur die Tabellen- und Index-Keys. Am kleinsten, am günstigsten.INCLUDE— die Keys plus eine benannte Liste zusätzlicher Attribute deiner Wahl.ALL— jedes Attribut des Items. Am größten; Abfragen brauchen nie die Basistabelle.- Das Lesen eines nicht projizierten Attributs erzwingt bei einem GSI einen Fetch aus der Basistabelle — eine stille Zusatzkosten. (Ein LSI kann nicht projizierte Attribute für dich holen, zu zusätzlichen Lesekosten.)
- Mehr Projektion = mehr Speicher + mehr Schreibkosten, da jeder Basistabellen-Write zum Index propagiert.
Das Problem: der Index, der dich zweimal lesen lässt
Sagen wir, du betreibst einen Support-Desk mit einem GSI, der dich offene Tickets
nach Priorität auflisten lässt. Du projizierst KEYS_ONLY, um ihn schlank zu halten.
Die Abfrage kommt schnell zurück — aber sie gibt dir nur Ticket-IDs, und dein
Queue-Bildschirm braucht von jedem Ticket Betreff, Bearbeiter und Alter.
Also macht dein Code jetzt eine zweite Runde Reads gegen die Basistabelle, um jedes Ergebnis anzureichern. Die "eine Abfrage", die du entworfen hast, ist tatsächlich eine Abfrage plus N Gets, und die Latenz und Kosten, die du sparen wolltest, kamen direkt zurück. Die Projektion war für das Zugriffsmuster zu dünn.
Was jeder Projektionstyp kopiert
KEYS_ONLYspeichert nur den Basistabellen-Key und den Index-Key. Nutze es, wenn die Abfrage nur wissen muss, welche Items passen, und du Details anderswo holst — oder gar nicht.INCLUDEspeichert die Keys plus eine feste Liste von Attributen, die du benennst. Der Sweet Spot: projiziere genau die Felder, die deine Abfrage zum Rendern braucht, und nicht mehr.ALLkopiert das gesamte Item. Abfragen werden vollständig aus dem Index selbst bedient, um den Preis, den gesamten Speicher und Schreibdurchsatz des Items in den Index zu duplizieren.
Für die Support-Desk-Queue ist INCLUDE mit subject, assignee und age die
richtige Wahl — die Queue rendert allein aus dem Index, ohne zweiten Fetch und ohne
das große body-Feld des Tickets in den Index zu duplizieren.
Die Kosten, die du eintauschst
Jedes Attribut, das du projizierst, wird
ein zweites Mal gespeichert
und im Index neu geschrieben, wann immer sich das Basis-Item ändert. Eine
großzügige ALL-Projektion auf einer häufig aktualisierten Tabelle vervielfacht also
sowohl Speicher als auch Schreibkapazität. Die Disziplin lautet: projiziere, was die
Abfrage liest, nicht "alles, nur für den Fall".
Eine Feinheit, die wissenswert ist: Bei einem sparse Index hält die Projektion
weiterhin nur die Items, die den Index-Key tragen — also bleibt INCLUDE/ALL auf
einem Sparse Index klein, weil der Index selbst
klein ist. Wäge den Speicher- und Schreib-Multiplikator für deine Projektion mit dem
DynamoDB-Preisrechner ab und stelle die
Index-Abfragen selbst mit dem
DynamoDB Expression Builder zusammen.
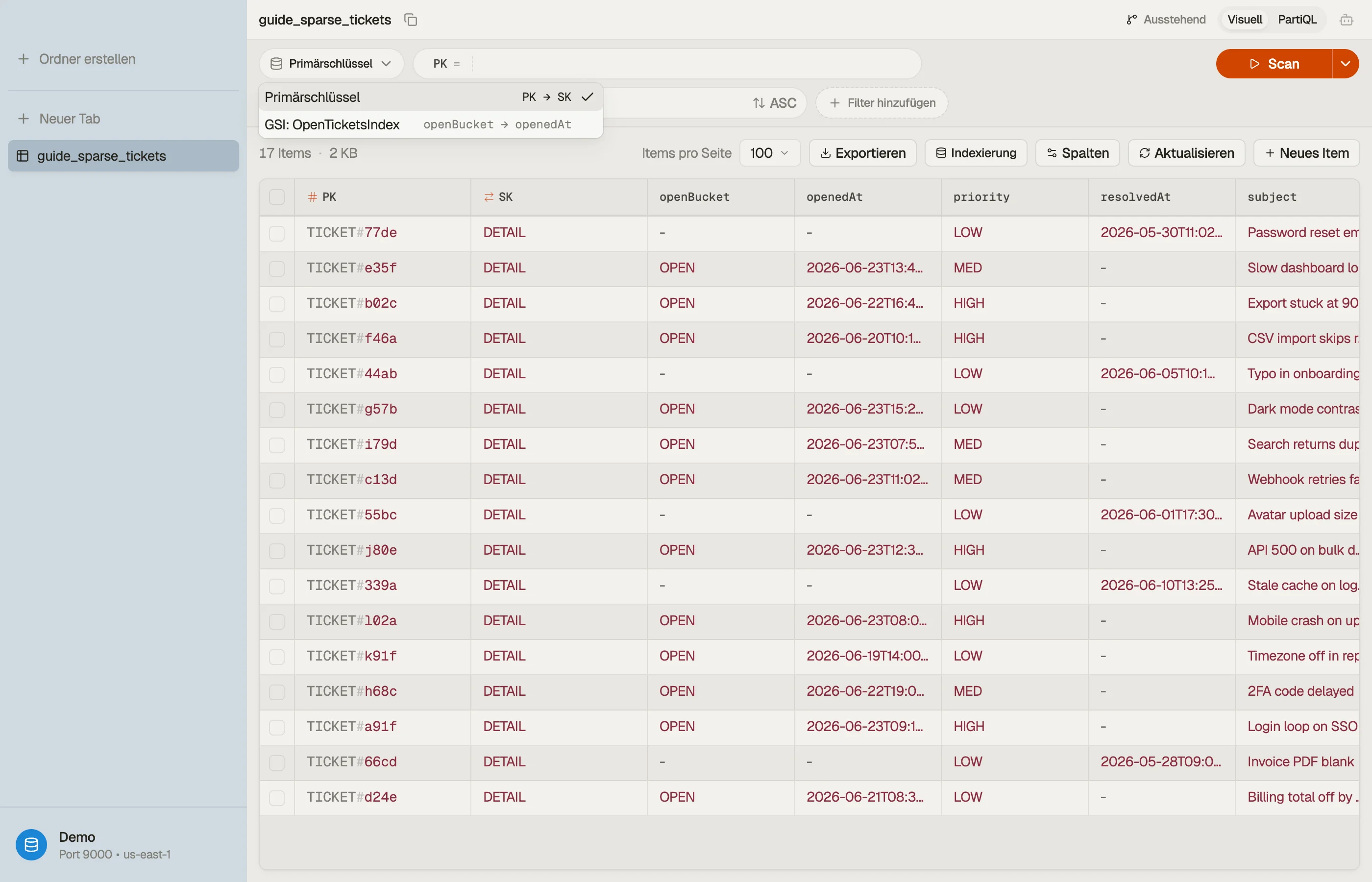
Eine Projektion in DynoTable sehen
DynoTable listet jeden sekundären Index einer Tabelle auf und lässt dich direkt durch einen abfragen. Führe dasselbe Zugriffsmuster gegen die Basistabelle und gegen einen GSI aus und vergleiche die Ergebnisse — die Attribute, die im Index-Ergebnis fehlen, sind genau die, die er nicht projiziert, sodass die Wirkung einer Projektion sichtbar ist, ohne die Tabellendefinition erneut zu lesen.


Fallstricke und nächste Schritte
- Ein nicht projiziertes Attribut auf einem GSI bedeutet einen Basistabellen-Fetch — entwirf die Projektion rund um das, was die Abfrage rendert.
ALList selten kostenlos — es dupliziert Speicher- und Schreibkosten; standardmäßigINCLUDE, es sei denn, der Index braucht wirklich jedes Feld.- Projektionen sind weitgehend fest. Du kannst die Projektion eines GSI später nicht frei bearbeiten, ohne den Index neu zu erstellen — wähle von vornherein bewusst.
- Verwandt: GSI vs. LSI und Sparse Indexes prägen, wie viel eine Projektion tatsächlich speichert.
Willst du sehen, was jeder deiner Indizes tatsächlich zurückgibt, bevor du sie neu entwirfst? Lade DynoTable herunter und frage deine Tabellen direkt ab.