DynamoDB Batch Operations: BatchGetItem & BatchWriteItem
Wenn du viele Items auf einmal lesen oder schreiben musst, bedeutet ein GetItem oder
PutItem pro Item einen Netzwerk-Round-Trip pro Item — langsam und gesprächig.
DynamoDBs Batch-APIs falten viele Item-Operationen in einen einzigen Request:
BatchGetItem für Reads, BatchWriteItem für Writes.
Sie sind ein Gewinn bei Durchsatz und Latenz, keine Konsistenzgarantie — und an dieser Unterscheidung verbrennen sich Leute. Ein Batch ist keine Transaktion.
Was sind DynamoDB Batch Operations?
DynamoDB Batch Operations falten viele Item-Reads oder -Writes in einen einzigen Request: BatchGetItem holt bis zu 100 Items, BatchWriteItem schreibt oder löscht bis zu 25 — jeweils gedeckelt bei 16 MB. Sie sparen Round Trips, keine Kapazität. Entscheidend: Ein Batch ist keine Transaktion — Items gelingen oder scheitern unabhängig voneinander, ohne Rollback.
BatchGetItem— bis zu 100 Items (oder 16 MB) über eine oder mehrere Tabellen in einem Call holen.BatchWriteItem— bis zu 25 Put-/Delete-Operationen (oder 16 MB) in einem Call. Keine Updates — nur Puts und Deletes.- Nicht atomar. Einzelne Items können gelingen, während andere scheitern. Es gibt kein Rollback.
- Teilweises Scheitern ist normal. Gedrosselte Items kommen in
UnprocessedItems/UnprocessedKeyszurück — du musst sie selbst erneut versuchen, mit Backoff. - Dieselben Kapazitätskosten wie die einzelnen Calls — Batching spart Round Trips, keine Kapazitätseinheiten.
Das Problem: viele Items, ein Round Trip
Sagen wir, du betreibst einen Support-Desk. Ein Dashboard muss 50 Tickets per ID laden, um eine Queue zu rendern; ein nächtlicher Job archiviert 1.000 gelöste Tickets. Das ein Item nach dem anderen zu tun sind 50 (oder 1.000) sequenzielle Round Trips — die Latenz stapelt sich und der Job kriecht.
Batching faltet diese in eine Handvoll Calls. Der 50-Tickets-Read wird ein einziges
BatchGetItem; der Archivierungsjob wird ein Strom von BatchWriteItem-Calls mit je
25 Deletes. Weit weniger Round Trips, dieselben Daten bewegt.
Wie die Batch-APIs funktionieren
BatchGetItem nimmt eine Menge von Primary Keys (über eine oder mehrere Tabellen)
und liefert die passenden Items zurück. Du kannst pro Tabelle stark konsistente Reads
anfordern. Alles, was es nicht lesen konnte — meist weil der Request an ein
Durchsatzlimit gestreift hat — kommt in UnprocessedKeys zurück, statt den ganzen
Call scheitern zu lassen.
BatchWriteItem nimmt eine Liste von PutRequest- / DeleteRequest-Operationen.
Beachte, was fehlt: es gibt kein Update. Ein Batch-Write ersetzt entweder ein
ganzes Item (Put) oder entfernt es (Delete) — um bestimmte Attribute zu ändern,
brauchst du weiterhin UpdateItem. Items, die es nicht schreiben konnte, kommen in
UnprocessedItems zurück.
Das mentale Schlüsselmodell: ein Batch ist ein Bündel unabhängiger Operationen, jede für sich gelingend oder scheiternd — keine Alles-oder-nichts-Einheit.
Batches sind keine Transaktionen
Das ist die Falle. Wenn der Batch deines Archivierungsjobs auf halbem Weg an ein Durchsatzlimit stößt, werden manche Tickets gelöscht und manche nicht — und DynamoDB macht die durchgegangenen nicht rückgängig. Es gibt kein Rollback, keine Isolation, kein "alle 25 oder keins".
Wenn du Alles-oder-nichts-Semantik brauchst — "verschiebe das Ticket nach archiviert
und dekrementiere den Zähler offener Tickets, oder tu keins von beidem" — ist das
TransactWriteItems, kein Batch. Transaktionen kosten
mehr (jede Operation wird doppelt abgerechnet) und sind bei 100 Items gedeckelt, aber
sie geben dir die Atomarität, die Batches bewusst nicht liefern.
Mit nicht verarbeiteten Items umgehen
Ein korrekter Batch-Caller prüft immer die Unprocessed-Menge und versucht sie
erneut. DynamoDB liefert UnprocessedItems/UnprocessedKeys zurück, wann immer der
Request als Ganzes akzeptiert wurde, aber manche Items nicht bedient werden konnten —
typischerweise vorübergehende Drosselung.
Reiche nur die nicht verarbeiteten Items erneut ein, mit exponentiellem Backoff und Jitter. Einen Batch als Fire-and-Forget zu behandeln verwirft stillschweigend Writes — die Art Bug, die Monate später als fehlende Daten auftaucht.
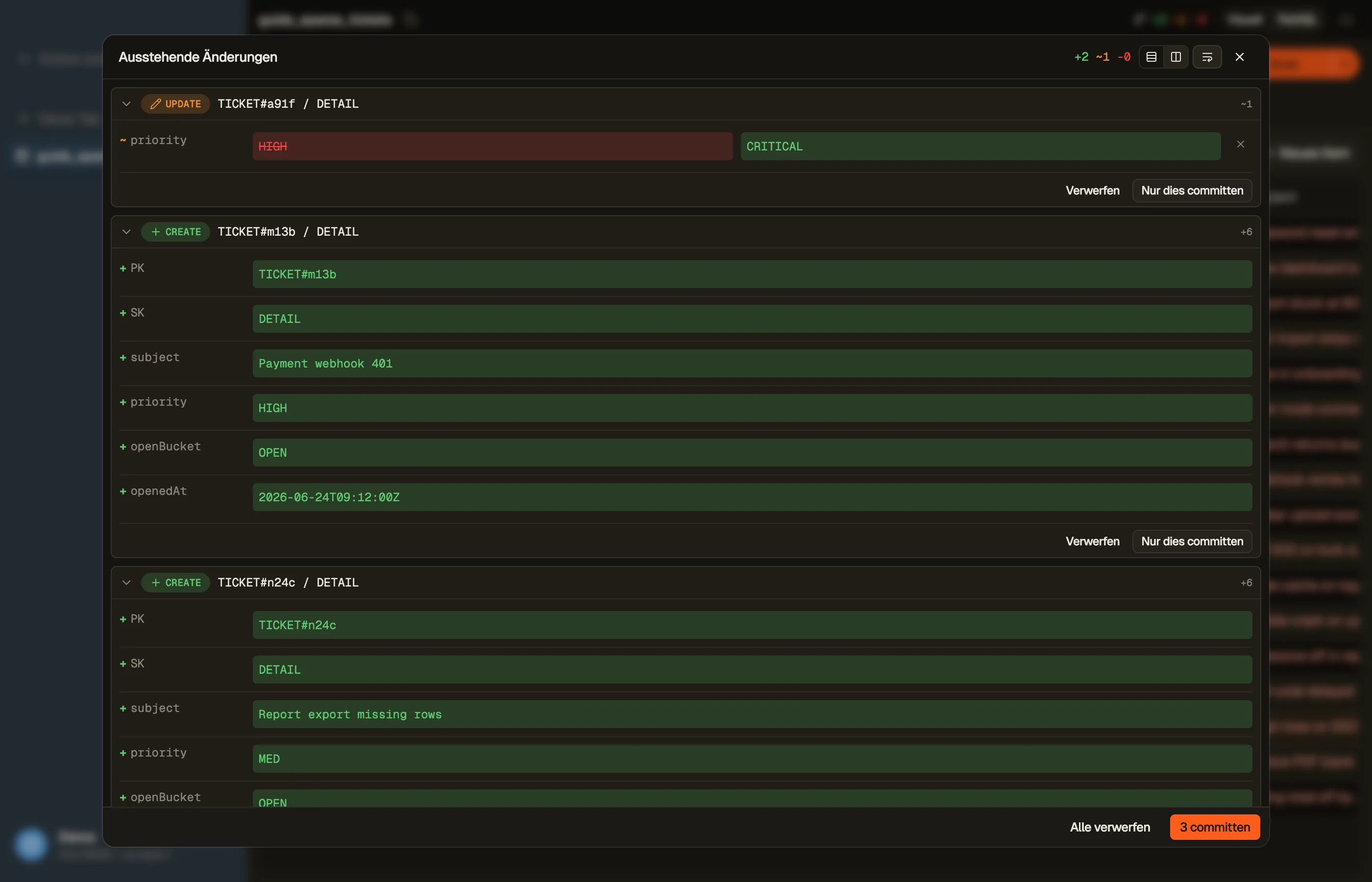
Batch-Writes in DynoTable
Schätze zuerst mit dem DynamoDB Pricing Calculator, was ein Massenjob kosten wird — ein Batch verbraucht dieselbe Kapazität wie die einzelnen Writes, die er bündelt, nur in weniger Requests.
In DynoTable stagst du deine Edits lokal und überprüfst sie, bevor du sie als effiziente gebündelte Writes commitest — Massen-Änderungen über viele Zeilen gehen in gruppierten Requests raus statt einem API-Call pro Änderung, mit dem Retry nicht verarbeiteter Items für dich erledigt.



Fallstricke und nächste Schritte
- Versuche
UnprocessedItems/UnprocessedKeysimmer erneut mit Backoff — sie sind erwartet, nicht außergewöhnlich. - Kein Rollback bei teilweisem Scheitern. Brauchst du Atomarität? Nutze Transaktionen.
- Keine Updates in einem Batch-Write —
BatchWriteItemist nur Put/Delete; greif zuUpdateItem, um Attribute zu ändern. - Beachte die Limits pro Call — 25 Writes / 100 Reads / 16 MB. Paginiere durch größere Jobs; siehe Pagination.
Willst du Massen-Reads und -Writes ausführen, ohne die Retry-Schleife zu skripten? DynoTable herunterladen und deine Tabellen direkt bearbeiten.