Zero-Padding bei Sort Keys in DynamoDB
Ein DynamoDB-String-Sort-Key sortiert lexikografisch — ein Zeichen nach dem
anderen, von links nach rechts — nicht numerisch. Also landet "10" vor "2", weil
"1" vor "2" kommt. Zero-Padding auf eine feste Breite ist, wie du die
String-Reihenfolge zur numerischen Reihenfolge passend machst.
Warum sortiert „10" vor „2" in einem DynamoDB-Sort-Key?
Weil ein DynamoDB-String-Sort-Key lexikografisch nach UTF-8-Byte-Reihenfolge verglichen wird, nicht numerisch. Das Byte für „1" kommt vor „2", also landet „10" vor „2". Padde jede Zahl auf eine feste Breite mit führenden Nullen — „2" wird zu „0000000002" — und die String-Reihenfolge stimmt dann exakt mit der numerischen Reihenfolge überein.
- Die Falle: Zahlen, die als Strings gespeichert sind, sortieren wie Wörter.
"100","11","2"ist die Reihenfolge, die DynamoDB dir gibt — nicht, was du meintest. - Die Lösung: Padde jede Zahl auf eine feste Breite mit führenden Nullen, sodass
"2"zu"0000000002"wird. Jetzt stimmen lexikografische und numerische Reihenfolge überein. - Wähle eine Breite einmal: Bemiss sie für den größten Wert, den du je speichern wirst, und füge dann ein paar Stellen hinzu. Die Breite später zu ändern bedeutet, jeden Key neu zu schreiben.
- Absteigend kostenlos: Um hoch-nach-niedrig zu sortieren (der Leaderboard-Fall),
speichere
maxValue - value, ebenfalls zero-padded — DynamoDB hat keine Sortierrichtung pro Attribut.
Warum String-Sort-Keys dich verraten
Aus SQL kommend „funktioniert" ein ORDER BY score DESC über einer
Integer-Spalte einfach — die Engine weiß, dass die Spalte numerisch ist. DynamoDB
hat keinen solchen Luxus für einen Sort Key, der kein Number-Typ ist.
DynamoDB vergleicht String-(S)-Sort-Keys per UTF-8-Byte-Reihenfolge, gemäß der
AWS-Sort-Key-Dokumentation.
Bytes, nicht Größenordnung. "9" (0x39) übertrumpft "10", weil sein erstes Byte
"1" (0x31) schlägt. Die Länge ist irrelevant — nur das erste abweichende Byte
entscheidet.
Das ist der Footgun: In dem Moment, in dem eine Zahl in einem String-Sort-Key lebt,
gibt jeder Query, der den Bereich durchläuft, Zeilen in einer Reihenfolge zurück,
die durcheinandergewürfelt aussieht.
Baue einen Leaderboard-Sort-Key
Nimm ein saisonales Arcade-Leaderboard. Eine Item Collection pro Saison hält jeden Lauf jedes Spielers, und du willst die Top-Scores zuerst.
Modelliere es mit einem Composite Key in einer einzigen Item Collection:
leaderboardId(Partition Key) — z. B.SEASON#2026-SPRING.rankKey(Sort Key) — der zero-padded Score plus ein Tiebreaker.
Ein naiver erster Versuch speichert den rohen Score als String:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
| SEASON#2026-SPRING | "9" | quickdraw |
| SEASON#2026-SPRING | "10" | ace_pilot |
| SEASON#2026-SPRING | "1500" | nightowl |
| SEASON#2026-SPRING | "240" | bytecrash |
Ein Query auf SEASON#2026-SPRING gibt sie in dieser Byte-Reihenfolge zurück:
"10", "1500", "240", "9". Der 9-Punkte-Lauf sitzt ganz hinten und der
1500-Punkte-Lauf ist in der Mitte vergraben. Nutzlos für ein Leaderboard.
Padde auf eine feste Breite
Wähle eine Breite, die breit genug für den größten Score ist, den du je aufzeichnen wirst, dann left-padde mit Nullen. Sagen wir, Scores sind bei zehn Millionen gedeckelt — das sind acht Stellen, also verwende zehn Stellen für Spielraum:
| leaderboardId | rankKey | playerHandle |
|---|---|---|
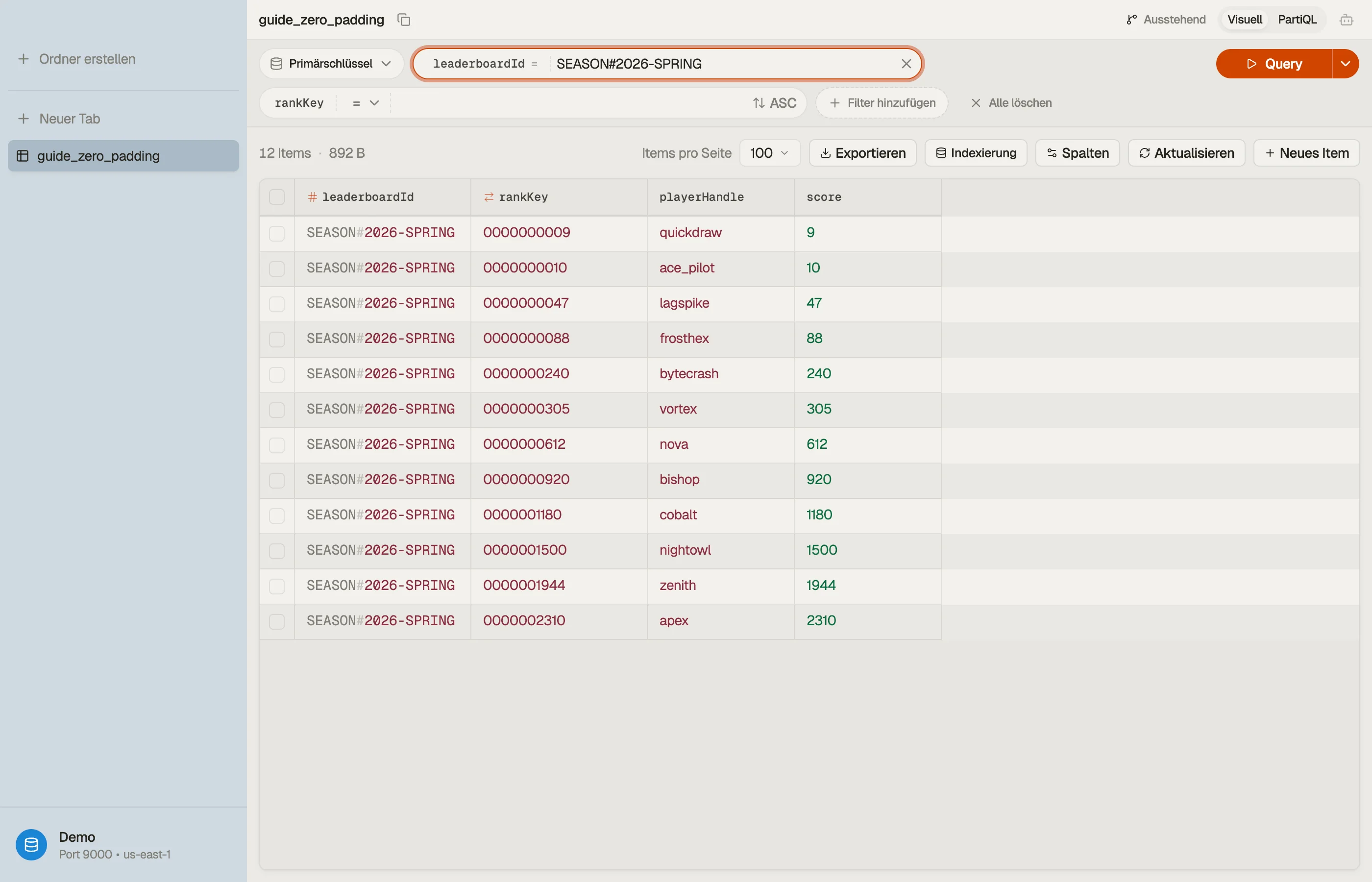
| SEASON#2026-SPRING | "0000000009" | quickdraw |
| SEASON#2026-SPRING | "0000000010" | ace_pilot |
| SEASON#2026-SPRING | "0000000240" | bytecrash |
| SEASON#2026-SPRING | "0000001500" | nightowl |
Jetzt ist jeder Key gleich lang, also erzeugen byteweiser Vergleich und numerischer
Vergleich die identische Reihenfolge. Ein aufsteigender Query gibt 9, 10, 240, 1500. Die Mathematik passt endlich zu den Bytes.
Die Breite ist eine Einbahntür. Wenn du auf zehn Stellen paddest und ein Score
später das überschreitet, sortiert ein 11-stelliger Wert vor einem 10-stelligen —
und bricht alles erneut — und das zu beheben bedeutet, jeden bestehenden rankKey
neu zu schreiben. Über-provisioniere die Breite; die Kosten sind eine Handvoll
Bytes.
Absteigend sortieren: speichere die Differenz
Ein Leaderboard will den höchsten Score zuerst. DynamoDB kann einen Sort Key
mit ScanIndexForward: false vorwärts oder rückwärts lesen, also ist absteigend
meist ein Lese-Zeit-Flag — greife zuerst danach.
Aber wenn eine Item Collection gemischte Sortierrichtungen bedienen muss, oder du
den Top-Score physisch zuerst willst, unabhängig von Lese-Flags, kehre die Zahl
selbst um. Speichere maxValue - score, zero-padded auf dieselbe Breite:
score inverted (9999999999 - score) rankKey
1500 9999998499 "9999998499"
240 9999999759 "9999999759"
10 9999999989 "9999999989"
9 9999999990 "9999999990"Aufsteigende Byte-Reihenfolge über dem invertierten Wert liefert jetzt die
ursprünglichen Scores hoch-nach-niedrig: 1500, 240, 10, 9. Der Kniff liegt im
Geist des
Amazon-Dynamo-Papers von 2007
— Keys sind undurchsichtige Bytes, also kodierst du Absicht in die Bytes.
Füge einen Tiebreaker hinzu
Zwei Spieler können gleichauf sein. Ein nackter padded Score kollidiert auf dem Sort Key, und ein zweiter Schreibvorgang würde den ersten überschreiben (gleicher PK + SK). Hänge ein eindeutiges Suffix an, sodass jeder Lauf ein eigenes Item ist und Gleichstände deterministisch aufgelöst werden:
rankKey = "<paddedScore>#<paddedTimestamp>#<playerId>"Zum Beispiel "0000001500#0000001719100800#p_8842". Gleicher Score, früherer
Timestamp gewinnt den höheren Platz — padde auch den Timestamp, sonst führt er genau
den Bug wieder ein, den du gerade behoben hast.
In DynoTable kannst du das Saison-Leaderboard sortiert nach dem zero-padded rankKey
durchsuchen und beobachten, wie die aufgefüllten Werte die Zeilen korrekt ausrichten —
Beweis, dass die Breiten stimmen, bevor du sie auslieferst.
Wenn du diesen Composite Key von Hand zusammensetzt, ist es leicht, eine Breite zu
vertippen. Die KeyConditionExpression für einen „Top der Saison"-Query im
Expression Builder zu generieren hält die
begins_with / between-Syntax ehrlich, während du mit Breiten experimentierst.


Fallstricke, die du vermeiden solltest
- Zu schmales Padding. Das ganze Schema kollabiert beim ersten Mal, dass ein Wert die Breite überläuft. Bemiss für den schlimmsten Fall, dann füge Stellen hinzu.
- Das Lese-Flag vergessen. Wenn du nur je absteigend liest, ist
ScanIndexForward: falsevielleicht alles, was du brauchst — greife nicht zu invertierten Keys, wenn ein Flag es tut. - Gemischte Breiten in einer Collection. Jeder Key, der einen Sort-Bereich teilt, muss dieselbe Breite verwenden. Eine Migration, die neue Zeilen paddet, aber alte nicht, verschachtelt sie falsch.
- Das falsche Segment padden. In einem Composite Key padde jedes numerische Segment, das an der Reihenfolge teilnimmt — Score und Timestamp beide, nicht nur den Score.
Nächste Schritte
Zero-Padding ist ein Werkzeug im breiteren
Sort-Key-Design-Werkzeugkasten; paare es mit
Item Collections, wenn du einen Key überlädst, um mehrere
Muster zu bedienen, und stütze dich auf einen präzisen Query statt auf einen
Scan, sobald die Reihenfolge stimmt.
Probiere DynoTable aus, um eine echte Tabelle zu durchsuchen und zu beobachten, wie deine zero-padded Sort Keys in numerische Reihenfolge fallen, bevor du das Schema ausschiffst.