DynamoDB-Migrationen ohne Downtime
Aus SQL kommend ist eine Migration ein ALTER TABLE, das die Tabelle sperrt,
während es jede Zeile neu schreibt. DynamoDB hat kein Schema zu ändern — Items sind
schemalos, also ist das Hinzufügen eines Attributs oder eines neuen Entitätstyps
kostenlos.
Der harte Teil ist das Zugriffsmuster, das die neuen Daten bedienen müssen, und das Umformen lebender Daten, um es zu bedienen, ohne ein Stop-the-World-Neuschreiben.
Wie migriert man eine DynamoDB-Tabelle ohne Downtime?
DynamoDB kennt kein ALTER TABLE, daher sperren Migrationen die Tabelle nie. Du fügst Attribute, eine neue Key-Form oder einen neuen online per UpdateTable hinzu und formst Live-Daten inkrementell um: Backfill alter Items entweder lazy beim Lesen oder mit einem gedrosselten Sweep, kombiniert mit Dual-Writes während der Übergangsphase. Es gibt keinen Flag-Day-Cutover.
- Es gibt kein
ALTER TABLE. Items sind schemalos. Eine „Migration" bedeutet, Attribute, eine neue Key-Form oder einen neuen Index hinzuzufügen — nie einen festen Spaltensatz neu zu schreiben. - Neue Schreibvorgänge sind einfach; alte Items sind das Problem. Die bestehenden Zeilen tragen die neuen Attribute nicht, also verfehlt jeder neue Index oder jede Abfrage sie still, bis du backfillst.
- Füge Indizes online hinzu, backfille lazy.
UpdateTablebaut einen GSI auf einer Live-Tabelle; backfille alte Items beim Lesen (lazy) oder mit einem kontrollierten Sweep — nie ein Flag-Day-Cutover. - Dual-Write über die Transition hinweg. Solange beide Formen koexistieren, schreibe das alte und neue Format zusammen, sodass kein Lesepfad veraltet.
Rahme es als Zugriffsmuster, nicht als Spalte
Angenommen, du betreibst ein SaaS-Workspace-Produkt auf einer Tabelle. Items
verwenden PK = "WS#<id>" und SK, überladen pro Entität:
| PK | SK | attributes |
|---|---|---|
| WS#a91 | META | name, tier |
| WS#a91 | DOC#2026-04-01#x7 | title, author, body |
| WS#a91 | DOC#2026-04-02#k2 | title, author, body |
Jetzt will das Produkt Kommentare zu Dokumenten, plus einen neuen Lesevorgang: „liste jeden Kommentar auf, den ein Mitglied über den Workspace geschrieben hat, neueste zuerst." Diese letzte Klausel ist die Migration. Ein neuer Entitätstyp allein ist trivial; eine Abfrage zu bedienen, die die aktuellen Keys nicht beantworten können, ist die Arbeit.
Füge zuerst den neuen Entitätstyp hinzu
Kommentare sind nur neue Items in derselben Partition — keine Migrationszeremonie, keine neue Tabelle:
| PK | SK | attributes |
|---|---|---|
| WS#a91 | DOC#2026-04-01#x7#CMT#01HZ... | author, text, createdAt |
Ein Query auf PK = "WS#a91" mit SK begins_with "DOC#2026-04-01#x7#CMT#" listet
bereits die Kommentare eines Dokuments auf. Bestehende Dokumente bleiben unberührt.
Diese Hälfte geht an Tag eins live — siehe
Item Collections und überladene Keys dafür, warum
dieselbe Partition beides hält.
Die neue Abfrage braucht einen GSI
„Alle Kommentare eines Mitglieds, neueste zuerst" kann von der Basistabelle nicht
bedient werden — memberId ist weder der PK noch ein SK-Präfix. Das ist ein
neuer Index, und ihn korrekt zu wählen ist eine eigene Entscheidung: siehe
GSI vs. LSI (ein LSI muss bei der Tabellenerstellung
existieren, also ist für eine Migration auf einer Live-Tabelle ein GSI deine einzige
Option).
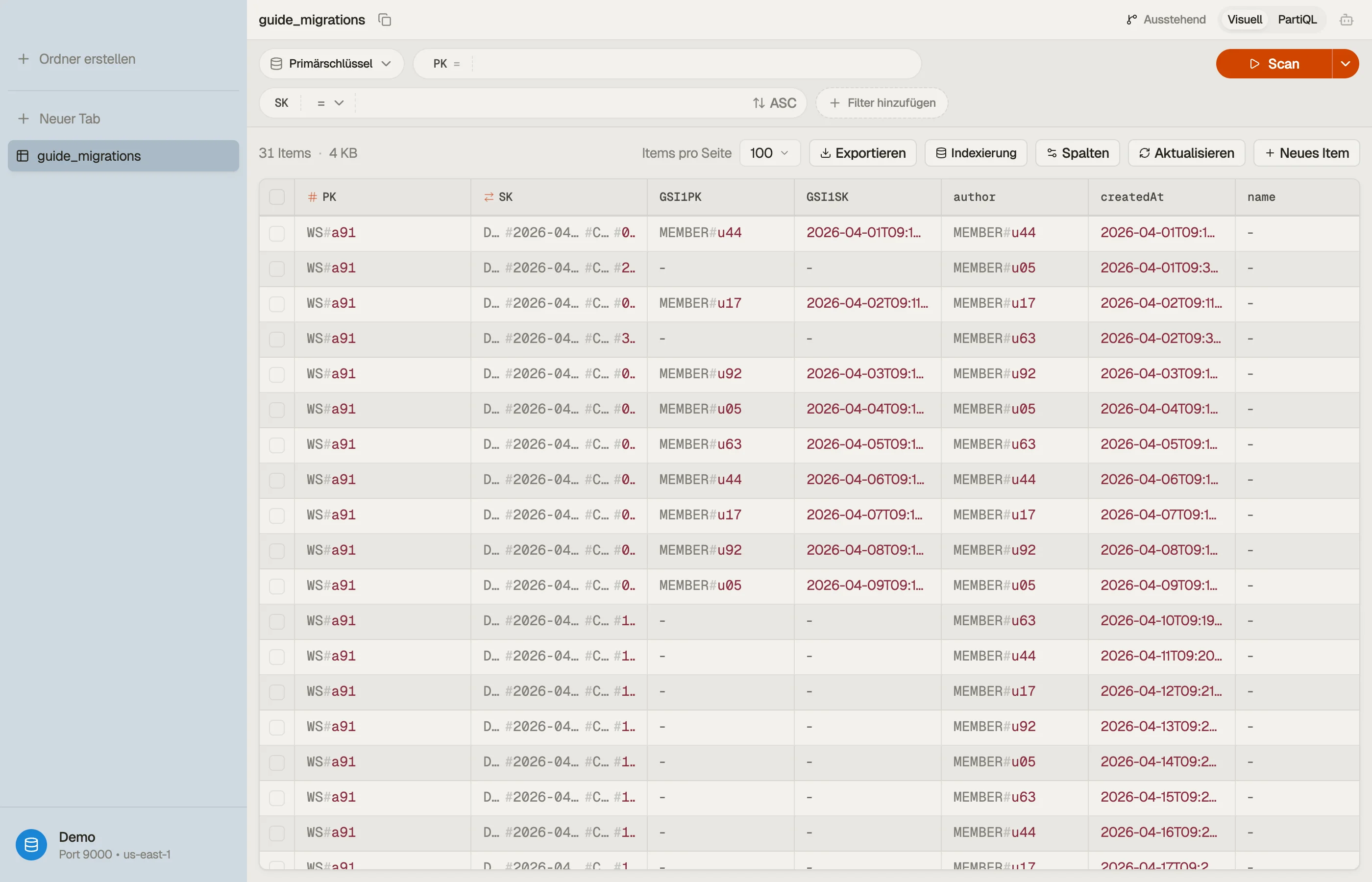
Füge einen generischen GSI1 hinzu und schreibe die neuen Attribute auf neue
Kommentar-Items:
| GSI1PK | GSI1SK |
|---|---|
| MEMBER#u44 | 2026-04-02T09:15:00Z |
Query GSI1 WHERE GSI1PK = "MEMBER#u44" mit ScanIndexForward = false gibt
Kommentare pro Mitglied neueste-zuerst.
Baue den Index online
UpdateTable fügt einer Live-Tabelle einen GSI ohne Downtime hinzu. DynamoDB
backfillt bestehende Items im Hintergrund in den Index; der Index meldet
CREATING/Backfilling, bis es fertig ist, dann kippt er auf ACTIVE
(Managing GSIs).
Zwei Fallen hier. Erstens warnt AWS, dass das Hinzufügen eines GSI
Basistabellen-Schreibvorgänge throtteln kann, wenn der neue Key ungleichmäßig
verteilt — füge ihn in einem verkehrsarmen Fenster hinzu und beobachte CloudWatch.
Zweitens ist der Index letztendlich konsistent, selbst nachdem er ACTIVE wird;
ein Schreibvorgang ist auf dem GSI möglicherweise einen Moment lang nicht sichtbar.
Siehe warum GSIs letztendlich konsistent sind.
Backfille die alten Items
Der GSI indexiert nur Items, die GSI1PK/GSI1SK haben. Deine
Pre-Migrations-Kommentare — geschrieben, bevor das Attribut existierte — erscheinen
nie, selbst nachdem der Backfill abgeschlossen ist. Der Online-GSI-Backfill kopiert
bestehende Items, aber er kann keine Attribute erfinden, die nicht auf ihnen sind.
Du musst die Werte hinzufügen.
Zwei Strategien:
| Strategie | Wie es funktioniert | Verwenden wenn |
|---|---|---|
| Lazy | Beim Lesen eines alten Items die neuen Attribute zurückschreiben | Alte Items werden oft gelesen; rinne die Kosten |
| Sweep | Ein paginierter Scan aktualisiert jedes alte Item einmal | Du brauchst den GSI bis zu einer Deadline komplett |
Für den Sweep blättere mit Scan durch und füge für jeden alten Kommentar die
Index-Attribute mit einem bedingten UpdateItem hinzu, sodass du nie einen
gleichzeitigen Schreibvorgang überschreibst.
Die Bedingung sichert darauf ab, dass das Attribut noch nicht existiert. Baue und
kopiere die exakte ConditionExpression und UpdateExpression mit dem
DynamoDB Expression Builder, statt
attribute_not_exists(GSI1PK) von Hand zu tippen.
Dual-Write durch die Transition
Bis jedes alte Item die neuen Attribute trägt, koexistieren zwei Formen. Der Schreibpfad muss das neue Format bei jedem Schreibvorgang befüllen — neue Kommentare und jedes Update eines alten — sodass die Lücke nur schrumpft.
Wähle eine Backfill-Endbedingung, die du verifizieren kannst: Der Sweep hat die ganze Tabelle durchblättert, oder der Lazy-Pfad lief lange genug, dass nicht-konvertierte Items von Natur aus veraltet sind. Erst dann entferne den alten Lesepfad. Dies zu überspringen ist, wie eine Migration „abschließt", während ein Bruchteil der Abfragen still zu kurze Ergebnisse zurückgibt.


Fallstricke
- Das Attribut hinzufügen ≠ backfilled. Ein neuer GSI startet für alte Items leer. Verifiziere die Abdeckung, bevor du der Abfrage vertraust.
- Einen Key an Ort und Stelle zu ändern ist keine Migration — es ist ein
Neuschreiben. Du kannst den
PK/SKeines Items nicht mutieren; du schreibst ein neues Item unter dem neuen Key und löschst das alte. Plane es als Copy-then-Delete, Dual-Read dazwischen. - Kein transaktionaler Cutover. Es gibt keinen Moment, in dem die ganze Tabelle kippt. Gestalte jeden Schritt so, dass er sicher ist, während beide Formen live sind.
Nächste Schritte
Prüfe die neuen Keys und überladenen Collections im Single-Table-Design und bestätige, dass der Backfill komplett ist, indem du die Live-Tabelle durchblätterst. Probiere DynoTable aus, um deine Tabelle zu durchsuchen, un-backfilled Items zu erkennen und die bedingten Updates gegen deine eigenen Daten auszuführen.