Key Overloading in DynamoDB
Aus SQL kommend bedeutet eine Spalte für immer eine Sache: orders.created_at ist
immer ein Datum, users.email ist immer eine E-Mail. Key Overloading wirft das
über Bord. Du gibst dem Partition und dem Sort Key generische Namen — pk, sk —
und lässt jeden Item-Typ eine andere Bedeutung hineingießen. Eine Tabelle, viele
Entitäten, eine Form.
Was ist Key Overloading in DynamoDB?
Key Overloading bedeutet, viele Entitätstypen unter generischen Key-Namen wie pk/sk in einer einzigen Tabelle zu speichern, wobei der Typ im Wert kodiert wird (USER#u_3001, INVOICE#2026-0014). Der Attributname bleibt neutral, sodass Benutzer, Rechnungen und Events dieselbe Partition teilen; der Wert trägt den Typ, und ein Sort-Key-Präfix erlaubt es, mit einem einzigen Query und begins_with jede Entität gezielt abzuschneiden.
- Generische Key-Namen, typisierte Werte. Benenne deine Keys
pk/skund packe den Entitätstyp in den Wert:pk = "TENANT#acme",sk = "USER#u_3001". Der Name ist dumm; der Wert trägt den Typ. - Es ist das, was Single-Table-Design funktionieren lässt. Ohne Overloading ist
eine geteilte Tabelle nur eine Kramschublade. Mit ihm sitzt jede Entität in einer
Partition, die du per
Queryabfragen kannst. begins_withist der Lohn. Ein Typ-Präfix auf dem Sort Key lässt einenQueryeine ganze Entität oder eine Scheibe davon ziehen, ohneScanund ohne Filter.- Der Preis: Lesbarkeit. Ein roher
pk/sk-Dump sagt dir nichts. Du brauchst einen Viewer, der die Präfixe dekodiert, sonst schielst du auf Strings.
Warum generische Namen echte schlagen
DynamoDB hat genau zwei Key-Attribute pro Tabelle, und ein Query kann nur einen
einzigen Partition Key anvisieren. Wenn du also deinen Key userId nennst, können
nur User-Items sauber in dieser Tabelle leben — alles andere muss eine userId
vortäuschen oder in eine eigene Tabelle umziehen.
Overloading umgeht das. Ein neutraler Name wie pk legt sich auf keine Entität
fest, also können ein User, eine Rechnung und ein Audit-Event sich alle dasselbe
Key-Attribut und dieselbe Tabelle teilen. Der Wert, nicht der Attributname, sagt,
was das Item ist.
Das ist der Zug, der Single-Table-Design von der Theorie in etwas verwandelt, das du tatsächlich abfragen kannst. Die geteilte Tabelle ist der Container; Overloading ist, was verschiedenen Entitäten erlaubt, darin zu koexistieren.
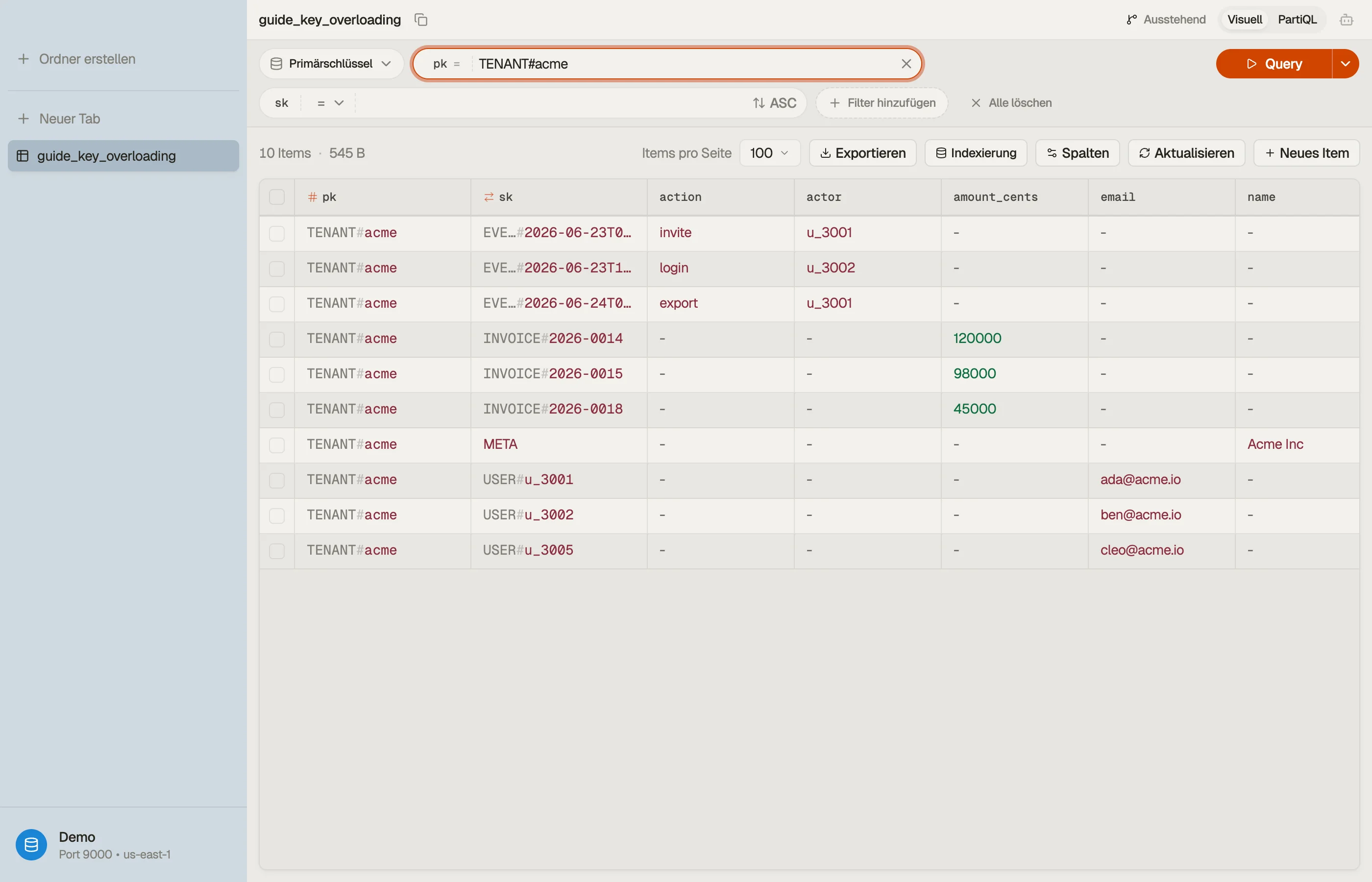
Ein Multi-Tenant-Beispiel
Angenommen, du betreibst ein SaaS-Billing-Produkt. Jeder Mandant hat Mitglieder, Rechnungen und einen Audit-Trail. Statt drei Tabellen packe alles in eine und überlade die Keys:
| pk | sk | attributes |
|---|---|---|
| TENANT#acme | META | name="Acme Inc", plan="team" |
| TENANT#acme | USER#u_3001 | email, role="admin" |
| TENANT#acme | USER#u_3002 | email, role="member" |
| TENANT#acme | INVOICE#2026-0014 | amount_cents, status="paid" |
| TENANT#acme | INVOICE#2026-0015 | amount_cents, status="open" |
| TENANT#acme | EVENT#2026-06-23T09:12Z | actor="u_3001", action="invite" |
Jede Zeile teilt pk = "TENANT#acme", also bilden sie eine Item Collection —
alle ko-lokalisiert, alle in einem Partitions-Lesevorgang erreichbar.
Das Sort-Key-Präfix leistet die eigentliche Arbeit. Es gruppiert Entitäten und ordnet sie.
Frage die überladene Collection ab
Weil der Typ im Sort-Key-Präfix liegt, zerschneidet begins_with die Partition nach
Entität, ohne irgendetwas zu scannen:
Query pk = "TENANT#acme" -- der ganze Mandant, jeder Typ
Query pk = "TENANT#acme" AND begins_with(sk, "USER#") -- nur Mitglieder
Query pk = "TENANT#acme" AND begins_with(sk, "INVOICE#") -- nur RechnungenDu zahlst nur für die Items, die die Bedingung trifft, nicht für die ganze
Partition — das Gegenteil eines gefilterten Scan, bei dem
du dafür zahlst, Zeilen zu lesen, die du dann wegwirfst. AWS nennt das eine Key-
Condition; sie läuft auf den Keys, bevor irgendwelche Daten die Partition
verlassen.
Wenn du diese begins_with-Bedingung von Hand baust, mach die Typ-Tags richtig —
ein verirrtes USERS# statt USER# liefert nichts zurück, stillschweigend. Der
Expression Builder generiert die
KeyConditionExpression und die ExpressionAttributeValues-Map, sodass die Präfixe
zu dem passen, was du tatsächlich geschrieben hast.
Überlade auch den Index
Derselbe Kniff gilt für einen GSI. Gib ihm generische Key-Namen — gsi1pk,
gsi1sk — und lass jede Entität schreiben, was sie braucht. Ein Index beantwortet
dann Muster, die die Basistabelle nicht kann.
| pk | sk | gsi1pk | gsi1sk |
|---|---|---|---|
| TENANT#acme | INVOICE#2026-0015 | STATUS#open | 2026-06-30 |
| TENANT#acme | INVOICE#2026-0014 | STATUS#paid | 2026-06-12 |
| TENANT#beta | INVOICE#2026-0099 | STATUS#open | 2026-06-25 |
Jetzt listet Query gsi1 WHERE gsi1pk = "STATUS#open" jede offene Rechnung über
alle Mandanten hinweg auf, nach Fälligkeitsdatum geordnet — eine
partitionsübergreifende Ansicht, die die mandanten-bezogenen Keys der Basistabelle
nie bedienen könnten. Eine andere Entität kann gsi1 mit ihrer eigenen Bedeutung
wiederverwenden (etwa gsi1pk = "ROLE#admin"), sodass ein Index mehrere
Lesevorgänge abdeckt. Denk nur daran, dass ein GSI
letztendlich konsistent ist — seine Schreibvorgänge hinken der
Basistabelle hinterher.
Mach es in DynoTable
Rohe überladene Keys sind feindlich zu lesen: INVOICE#2026-0015 und
EVENT#2026-06-23T09:12Z verschwimmen in einer flachen Liste. Ein Viewer, der nach
Partition gruppiert und die Präfixe hervorhebt, verwandelt die Kramschublade zurück
in Entitäten.


Fallstricke
- Wähle Trennzeichen einmal und ändere sie nie.
#ist die Konvention.#und:über Entitäten zu mischen brichtbegins_withauf Weisen, vor denen dich nichts warnt. - Überlade keine Werte, die Bereichsmathematik brauchen. Ein Sort Key von
INVOICE#2026-0015sortiert lexikalisch, nicht numerisch — zero-padde IDs und verwende ISO-8601-Daten, sodass die String-Reihenfolge zur gemeinten Reihenfolge passt. - Reserviere den Präfix-Namensraum. Zwei Entitätstypen, die beide mit
USERbeginnen (etwaUSER#undUSERGROUP#), kollidieren unterbegins_with(sk, "USER"). Mache Präfixe vom ersten Zeichen an eindeutig. - Plane den Lesevorgang vor den Keys. Overloading bedient Zugriffsmuster, die du aufgezählt hast. Wenn du deine Lesevorgänge noch nicht kennst, lies zuerst Single-Table-Design — die Keys sind den Queries nachgelagert.
Kartiere eine Partition, dann lade DynoTable herunter, um deine eigenen
überladenen Keys zu durchsuchen und zu beobachten, wie ein Query einen ganzen
Mandanten auf einmal zurückzieht.