Composite Sort Keys in DynamoDB
Ein Composite Primary Key ist ein Partition Key plus ein Sort Key. Der Kniff,
der ihn mächtig macht, ist das, was du in den Sort Key packst: Kodiere eine
Hierarchie als einen einzigen begrenzten String, und ein einziger Query liest
einen ganzen Teilbaum in Sortierreihenfolge — keine Joins, keine Rekursion, kein
zweiter Round-Trip.
Wie funktionieren Composite Sort Keys in DynamoDB?
Ein Composite Sort Key packt eine Hierarchie in einen einzigen begrenzten String — root/photos/2026/ —, den DynamoDB in UTF-8-Byte-Reihenfolge speichert. Da das Layout bereits zum Baum passt, liest ein einziger Query mit begins_with(SK, "root/photos/") einen ganzen Teilbaum in Pfadreihenfolge. Keine Joins, keine Rekursion, kein zweiter Round-Trip — nur ein Präfix-Scan über eine zusammenhängende Scheibe.
- Der Sort Key ist ein sortierbarer String, nicht nur eine ID. Packe einen
Pfad hinein —
root/photos/2026/— und DynamoDB speichert die Items der Partition automatisch in UTF-8-Byte-Reihenfolge. - Ein Trennzeichen verwandelt Präfix-Treffer in Teilbaum-Lesevorgänge.
begins_with(SK, "root/photos/")liefert jeden Nachfahren dieses Ordners in einem Query. - Sort Keys unterstützen Bereichsbedingungen, keine beliebigen Filter. Du
bekommst
begins_with,between,>,<— gestalte den Key so, dass der benötigte Lesevorgang ein Präfix oder ein Bereich ist, keinScan. - Das Trennzeichen ist tragend. Wähle eines, das in keinem Pfadsegment auftauchen kann, sonst kollidieren zwei unverwandte Zweige.
Warum der Sort Key das ganze Spiel ist
Aus SQL kommend würdest du einen Ordnerbaum mit einem parent_id-Self-Join
modellieren und ihn rekursiv ablaufen — ein Query pro Ebene. In DynamoDB ist das
ein N+1-Footgun gegen einen Key-Value-Store, der keine Joins hat.
DynamoDB speichert jedes Item unter einem Partition Key, sortiert nach seinem Sort Key, bei Strings in UTF-8-Byte-Reihenfolge (AWS: Query Key Conditions). Wenn dein Sort Key also der Pfad ist, passt das physische Layout bereits zum Baum. Ein Lesevorgang wird zu einem Präfix-Scan über eine zusammenhängende Scheibe — kein Graph-Walk.
Das ist die Verschiebung: Der Sort Key ist keine Kennung, die du exakt abgleichst. Er ist eine sortierbare Adresse. Gestalte ihn, und der Query fällt von selbst heraus.
Modelliere einen Dateibaum
Angenommen, du speicherst Dateibäume pro Konto. Ein Laufwerk pro Konto ist die natürliche Partition; der Pfad darin ist der Sort Key.
| PK | SK | node_type | bytes |
|---|---|---|---|
| DRIVE#a91 | root/ | folder | - |
| DRIVE#a91 | root/photos/ | folder | - |
| DRIVE#a91 | root/photos/2026/ | folder | - |
| DRIVE#a91 | root/photos/2026/beach.jpg | file | 284910 |
| DRIVE#a91 | root/photos/2026/sunset.jpg | file | 512004 |
| DRIVE#a91 | root/docs/ | folder | - |
| DRIVE#a91 | root/docs/taxes.pdf | file | 88210 |
Zwei eigene Konventionen leisten hier die Arbeit:
PK = DRIVE#<account>hält den ganzen Baum eines Kontos in einer einzigen Item Collection, sodass jeder Teilbaum-Lesevorgang ein Single-Partition-Queryist.SKist der vollständige Pfad mit einem abschließenden/bei Ordnern. Der abschließende Schrägstrich ist Absicht — er sorgt dafür, dass ein Ordner vor seinen eigenen Kindern sortiert wird, und hältroot/photos/von einer gleichrangigen Datei namensroot/photosgetrennt.
Lies einen Teilbaum in einem Query
Liste alles unter root/photos/ auf — Ordner, Unterordner und Dateien, rekursiv:
Query
KeyConditionExpression = PK = :drive AND begins_with(SK, :prefix)
:drive = "DRIVE#a91"
:prefix = "root/photos/"Das liefert root/photos/, root/photos/2026/, beach.jpg und sunset.jpg — in
Pfadreihenfolge, in einem abgerechneten Lesevorgang. Du zahlst nur für die Items in
dieser Scheibe, nicht für das ganze Laufwerk.
In DynoTable führst du genau diese begins_with-Abfrage gegen den Pfad-Sort-Key aus und
der Ordner samt seinen Nachfahren kommt in Pfadreihenfolge zurück — keine Platzhalter-Syntax,
die du von Hand schreiben musst.
Brauchst du die rohe KeyConditionExpression (Namen, Werte und begins_with) für deinen
eigenen Code? Baue und kopiere sie im
DynamoDB Expression Builder.

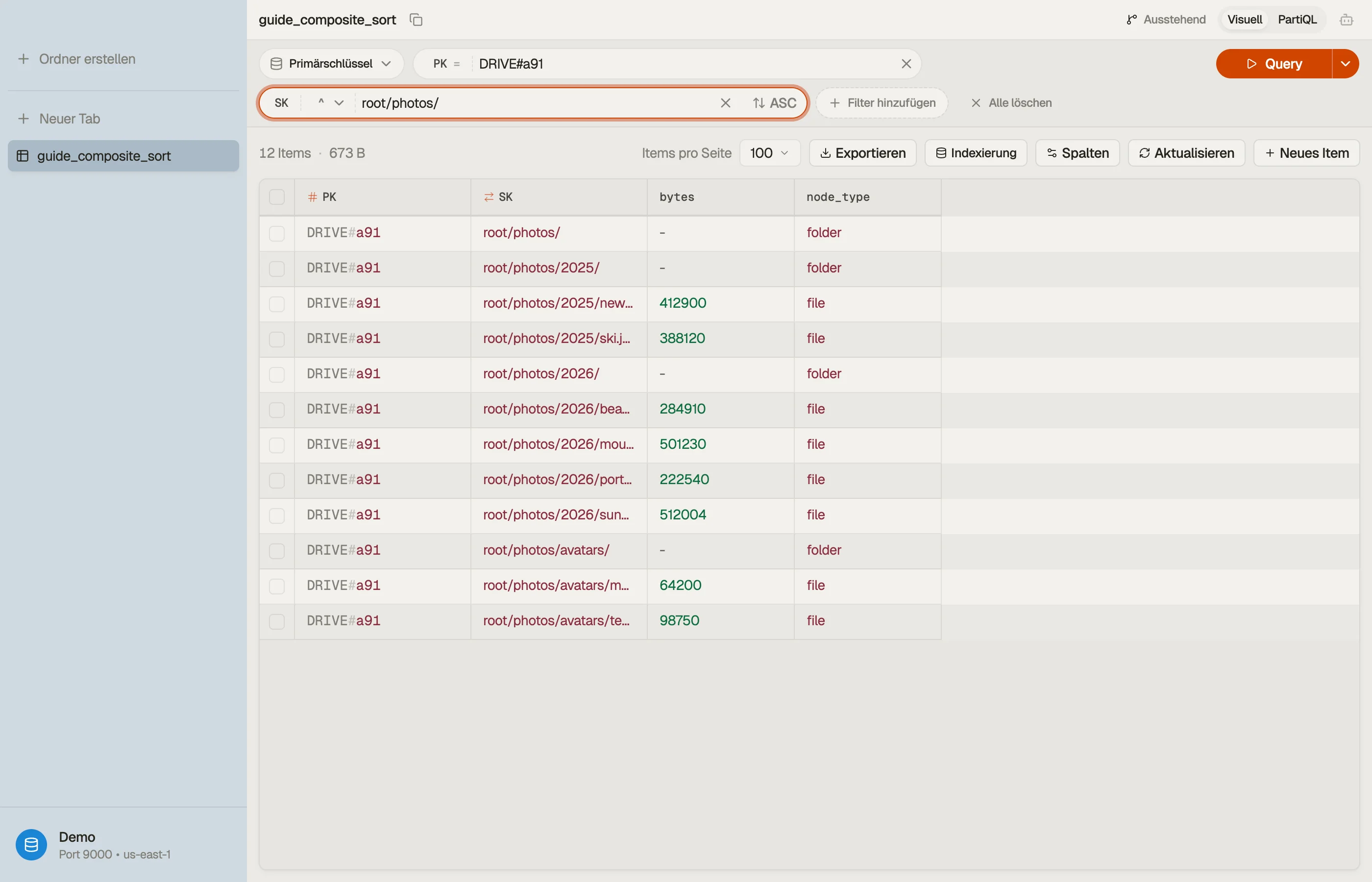

Liste eine Ebene, nicht den ganzen Teilbaum
begins_with gibt dir den rekursiven Lesevorgang. Für eine nicht-rekursive
Verzeichnisauflistung — die unmittelbaren Kinder von root/photos/ und nichts
Tieferes — speichere ein depth-Attribut und füge einen
Sort-Key-Bereich plus einen Filter hinzu, oder teile den Pfad in einen parent-GSI
auf. Die einfachste Variante: Halte ein parent-Attribut (root/photos/) und
einen darauf verschlüsselten GSI.
Der Punkt: Ein Sort Key beantwortet Präfix- und Bereichs-Fragen günstig.
„Nur direkte Kinder" ist eine andere Frage — modelliere sie explizit, statt zu
hoffen, dass eine FilterExpression sie effizient macht. Ein Filter läuft nach
dem Lesevorgang, und du zahlst für jedes Item, das er verwirft.
Wähle das Trennzeichen sorgfältig
Das Trennzeichen ist Teil deines Datenvertrags. Zwei Regeln:
- Es darf niemals innerhalb eines Pfadsegments auftauchen. Wenn Dateinamen
/enthalten können, ist/das falsche Trennzeichen — eine Datei namensa/bist nicht von einem Ordnerazu unterscheiden, derbhält. Wähle ein reserviertes Byte (manche Teams verwenden#oder ein Steuerzeichen) und verbiete es in Segmenten. - Achte auf die Sortierreihenfolge an Grenzen.
/(0x2F) sortiert vor Ziffern und Buchstaben, was für Baumreihenfolge meist das ist, was du willst. Ändere das Trennzeichen, und du änderst die Reihenfolge — verifiziere es an echten Daten.
Composite Sort Key vs. ein separates Sortier-Attribut
Composite Sort Key (root/photos/2026/x) | Reiner ID-Sort-Key + parent-Attribut | |
|---|---|---|
| Teilbaum-Lesevorgang | Ein begins_with-Query | Rekursive Queries (N+1) oder GSI-Walk |
| Reihenfolge | Pfadreihenfolge, kostenlos | Muss ein explizites Sortier-Attribut hinzufügen |
| Verschieben / Umbenennen | Alle Nachfahren neu schreiben | Einen parent-Zeiger aktualisieren |
| Direkt-Kinder-Liste | Braucht depth-Attr oder GSI | Natürlich (parent = x) |
Composite Keys gewinnen, wenn Lesevorgänge teilbaumförmig sind und die Reihenfolge zählt; das Flat-ID-Modell gewinnt, wenn der Baum sich ständig ändert. Die meisten leselastigen Hierarchien — Dateibäume, Kategoriebäume, Org-Charts — neigen zu Composite.
Fallstricke und nächste Schritte
- Überfülle den Key nicht. Alles, was du kodierst, ist unveränderlich und nur per Präfix indexiert. Attribute, die du per Gleichheit abfragst, gehören in eigene Felder oder einen GSI, nicht in den Sort Key gequetscht.
- Ein Sort Key kann kein beliebiges
WHERE. Nurbegins_with,betweenund Vergleiche. Wenn du nach einerFilterExpressiongreifst, hast du den Key wahrscheinlich falsch modelliert — siehe Query vs. Scan. - Mehr zum Key-Design findest du im Single-Table-Design; für den Fall, dass ein Teilbaum-Lesevorgang einen Index statt der Basistabelle braucht, siehe GSI vs. LSI.
Baue die begins_with-Key-Bedingung mit dem
Expression Builder, dann
lade DynoTable herunter, um diese Präfix-Abfragen gegen deine eigenen
Tabellen auszuführen und einen Teilbaum in Pfadreihenfolge zurückkommen zu sehen.